Clear Sky Science · de
Ein hybrides Simulations‑und‑Machine‑Learning‑Proxymodell zur Optimierung des Waterflood‑Designs in der Bahariya‑Formation
Warum klügerer Wassergebrauch in Ölfeldern wichtig ist
Um die letzten Tropfen Öl aus einem Reservoir zu holen, wird in der Regel Wasser ins Gestein gepresst, um das Öl zu den Förderbrunnen zu verdrängen. Dieser Vorgang, Waterflooding genannt, ist weit verbreitet, aber alles andere als perfekt: Zu viel Wasser kann an den falschen Stellen injiziert werden, wertvolles Öl zurücklassen und große Mengen Produktionswasser erzeugen. Diese Studie zeigt, wie die Kombination klassischer, physikbasierter Simulationen mit modernem Machine Learning Ingenieuren helfen kann, Waterfloods in einem besonders komplexen ägyptischen Ölfeld intelligenter zu entwerfen und so mehr Öl mit weniger zeitaufwändigen Versuchsreihen am Computer zu fördern.
Ein kniffliges unterirdisches Puzzle
Die Bahariya‑Formation in Ägyptens Westlicher Wüste ist kein ordentliches, einheitliches Gesteinsschwamm. Sie besteht vielmehr aus alten Fluss- und Deltaablagerungen, mit Lagen aus Sandstein und Schiefer, die unregelmäßig zusammengesetzt sind. Dieses Flickwerk erzeugt Kanäle, in denen Fluide leicht fließen, und Sackgassen, in denen Öl eingeschlossen bleibt. Die Bohrlochdaten sind begrenzt, sodass sich dieses unterirdische Labyrinth nur schwer detailliert beschreiben lässt. Traditionelle Reservoirsimulatoren können solche Systeme zwar modellieren, aber eine umfassende Untersuchung erfordert Tausende langsamer, rechenintensiver Durchläufe – zu viele für Entscheidungen im Alltagsbetrieb vor Ort.
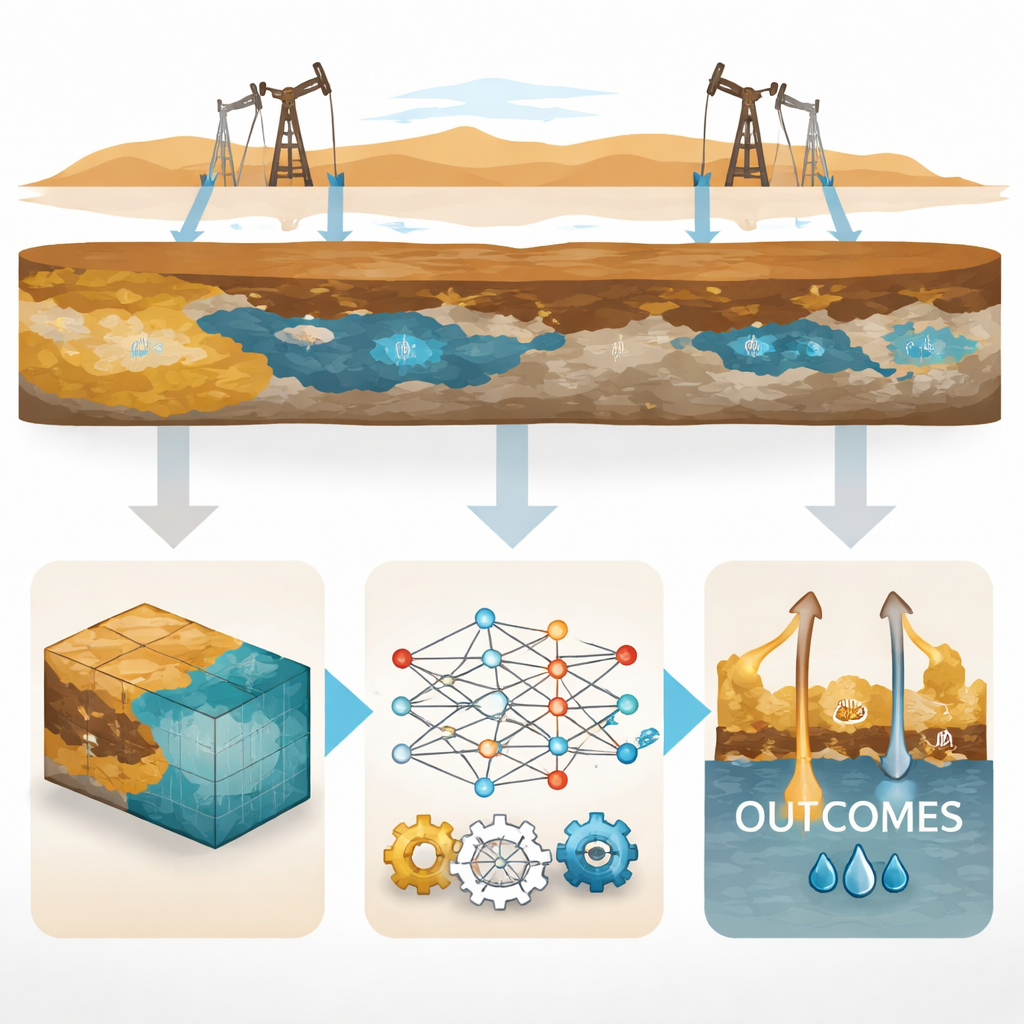
Physikmodelle mit datengetriebener Lernmethodik verbinden
Die Autoren bauten ein detailliertes dreidimensionales Computermodell des Reservoirs unter Verwendung geologischer und petrophysikalischer Informationen wie Gesteinsqualität, Porenraum und Flüssigkeitseigenschaften. Anschließend entwarfen sie eine große Menge von „Was‑wenn“‑Szenarien – insgesamt 1.536 – indem sie Schlüsselparameter variierten, etwa die Injektionsrate des Wassers, die Durchlässigkeit für Wasser, den verbleibenden, eingeschlossenen Ölanteil und die Leichtigkeit bzw. Schwerfälligkeit des Öls. Für jedes Szenario testeten sie drei standardmäßige Anordnungen von Injektions‑ und Produktionsbrunnen: ein Five‑Spot‑Gitter mit einem Injektor umgeben von Produzenten, ein versetztes Line‑Drive‑Muster und ein peripheres Schema, das Wasser hauptsächlich am Rand des Feldes einspeist. Der Simulator lieferte für jeden Fall die prognostizierte endgültige Ölrückgewinnung.
Einem schnellen Proxy das Verhalten des Simulators beibringen
Anstatt dauerhaft auf langsame Simulationen angewiesen zu bleiben, trainierte das Team einfache Machine‑Learning‑Modelle – konkret lineare Regressionen – um den Zusammenhang zwischen den variierten Eingangsgrößen und der finalen Ölrückgewinnung für jedes Brunnenmuster zu erlernen. Diese Modelle fungieren als „Proxys“: Einmal trainiert, können sie die Rückgewinnung in Bruchteilen einer Sekunde vorhersagen. Die Forschenden teilten die Daten sorgfältig in Trainings‑ und Testmengen und prüften die Leistung über mehrere Aufteilungen hinweg. Für alle drei Muster reproduzierten die Modelle die Ergebnisse des Simulators mit hoher Genauigkeit, sie erklärten mehr als 93 Prozent der Variabilität der Rückgewinnung und hielten die Vorhersagefehler sehr klein. Effektiv wurde der rechenintensive physikbasierte Simulator in leichte Gleichungen destilliert, die weiterhin physikalisch sinnvolles Verhalten zeigen.
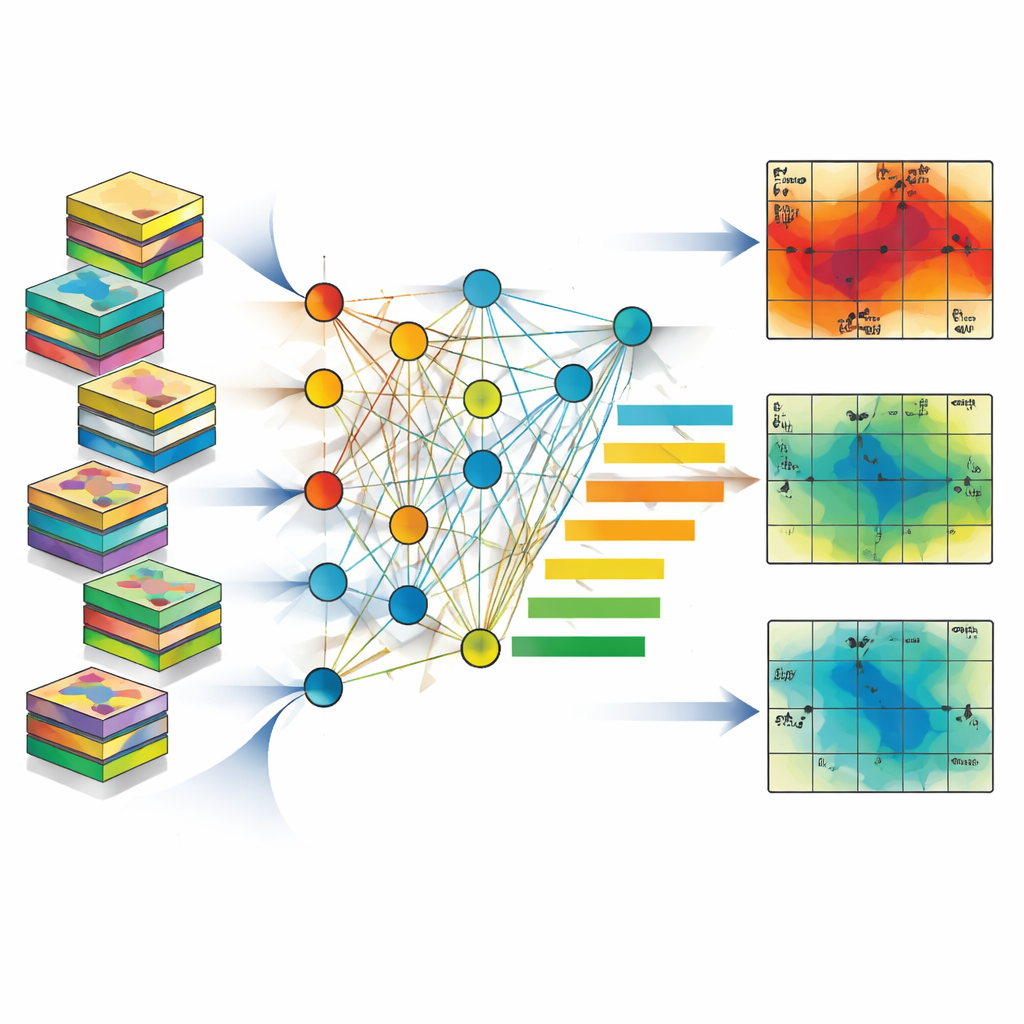
Was tatsächlich steuert, wie viel Öl herauskommt
Mit diesen schnellen Proxy‑Modellen untersuchten die Autoren, welche Faktoren am wichtigsten sind. Indem sie nacheinander jede Eingangsgröße leicht durcheinanderbrachten und beobachteten, wie sich die Vorhersagen verschlechterten, stellten sie fest, dass die Menge des nach der Flutung im Gestein verbleibenden Öls – die sogenannte residuale Öl‑Sättigung – mit Abstand die dominierende Steuergröße war und nahezu 40 Prozent oder mehr der Vorhersagekraft über alle Muster ausmachte. Auch die Ölqualität spielte eine Rolle: Leichtere Öle flossen leichter und erhöhten die Rückgewinnung, während Gesteine, die Wasser zu leicht durchließen, tendenziell frühzeitige Wasser‑„Durchbrüche“ verursachten und die Sweep‑Effizienz verringerten. Interessanterweise hing die Bedeutung der Injektionsrate stark vom Muster ab. Im peripheren Schema hatte die Injektionsstärke einen deutlich größeren Einfluss als im gitterähnlichen Five‑Spot‑Layout, was zeigt, dass unterschiedliche Brunnenanordnungen auf unterschiedliche Stellschrauben reagieren.
Von der Computererkenntnis zur Feldentscheidung
In der Zusammenführung zeigt die Studie, dass es kein universell bestes Waterflood‑Muster gibt. Im simulierten Bahariya‑Feld lieferte das periphere Layout die höchste letztendliche Rückgewinnung, gefolgt vom versetzten Line Drive und schließlich dem Five‑Spot‑Muster. Diese Rangfolge entstand jedoch erst nach Berücksichtigung der spezifischen Gesteinsstruktur und Fluid‑Eigenschaften dieses Reservoirs. Der hybride Workflow – Simulationen zur Datengenerierung nutzen und anschließend Machine Learning für die schnelle Analyse einsetzen – bietet Feldingenieuren eine praktische Methode, viele Waterflood‑Optionen zu sichten, zu verstehen, welche Parameter wirklich relevant sind, und Injektionsstrategien zu optimieren, ohne Tausende vollständiger Simulationen laufen lassen zu müssen. Für die nicht‑fachliche Leserschaft lautet die Kernaussage simpel: Indem Computer sowohl die physikalischen Gesetze respektieren als auch aus Daten lernen, können Betreiber mehr Öl aus denselben Gesteinen fördern und dabei Wasser sowie Rechenressourcen effizienter einsetzen.
Zitation: Gad, R., Salem, A.M., El Farouk, O.M. et al. A hybrid simulation-machine learning proxy model for waterflood design optimization in the Bahariya Formation. Sci Rep 16, 14023 (2026). https://doi.org/10.1038/s41598-026-49561-5
Schlüsselwörter: Waterflooding, Machine Learning, Ölrückgewinnung, Reservoirsimulation, Bahariya‑Formation