Clear Sky Science · sv
En hybrid simulerings–maskininlärningsproxymodell för optimering av waterflood‑design i Bahariya‑formationen
Varför smartare vattenanvändning på oljefält spelar roll
Att få ut de sista dropparna olja ur en reservoar innebär oftast att man pressar in vatten i berget för att svepa oljan mot produktionsbrunnarna. Denna process, kallad waterflooding, är utbredd men långt ifrån perfekt: för mycket vatten kan injiceras på fel ställen, vilket lämnar värdefull olja kvar och skapar stora mängder avloppsvatten. Denna studie visar hur en kombination av klassiska fysikbaserade simuleringar och modern maskininlärning kan hjälpa ingenjörer att utforma smartare waterflood‑program i ett särskilt komplext egyptiskt oljefält, vilket återvinner mer olja med färre försöks‑och‑fel‑körningar på datorn.
Pussel under marken
Bahariya‑formationen i Egyptens västra öken är inte en prydlig, enhetlig svamp av sten. Istället är den uppbyggd av gamla flod‑ och deltadepositioner, med skikt av sandsten och skiffer sydda ihop i oregelbundna mönster. Detta lapptäcke skapar kanaler där vätskor kan röra sig lätt och blindgångar där olja fastnar. Data från brunnar är begränsade, vilket gör det svårt att beskriva denna underjordiska labyrint i detalj. Traditionella reservoarsimulatorer kan modellera sådana system, men för att göra det grundligt krävs tusentals långsamma, datorintensiva körningar — för många för vardagliga beslutsprocesser ute på fältet.
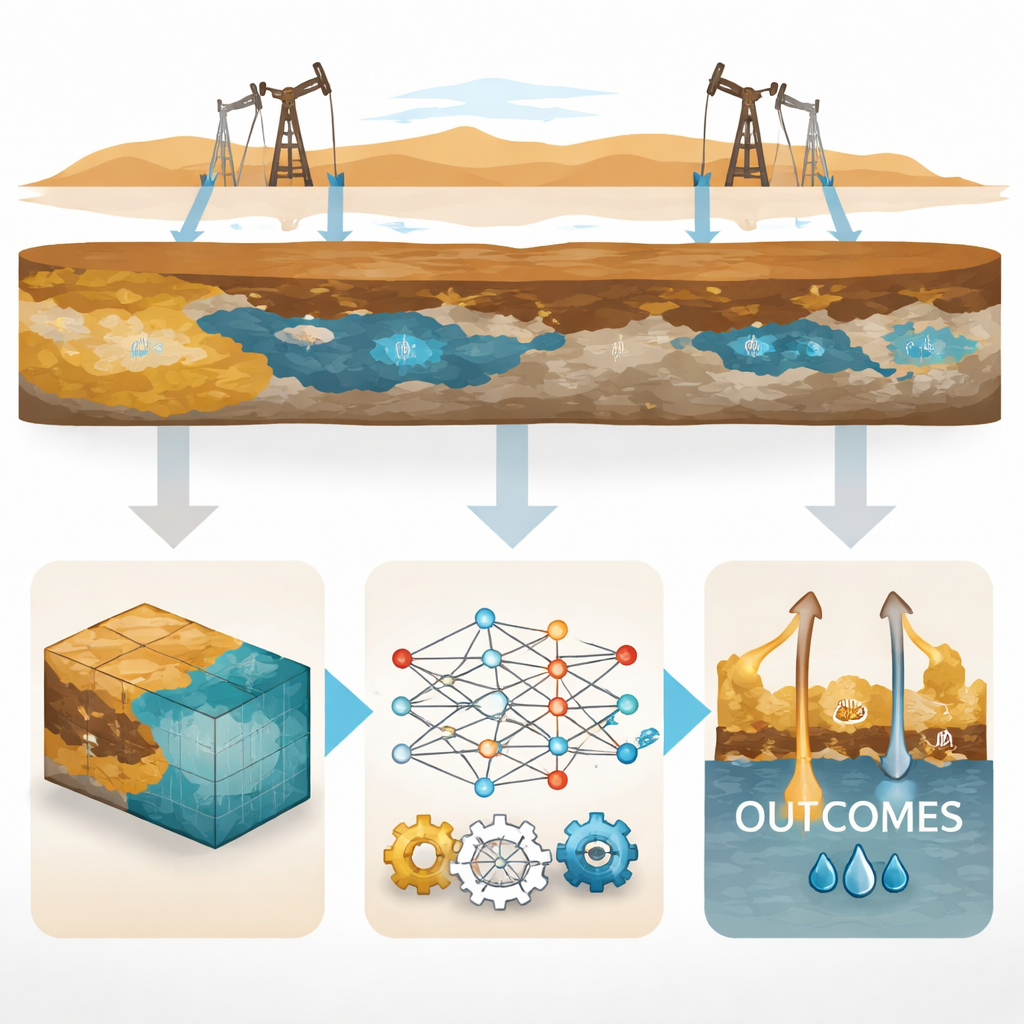
Att blanda fysikmodeller med datadriven inlärning
Författarna byggde en detaljerad tredimensionell datormodell av reservoaren med geologisk och petrofysisk information såsom bergkvalitet, porutrymme och vätskors egenskaper. De utformade sedan en stor uppsättning "what‑if"‑scenarier — totalt 1 536 — genom att variera nyckelfaktorer som hur snabbt vatten injiceras, hur lätt vattnet flödar genom berget, hur mycket olja som tenderar att bli kvar fastklämd och hur lätt eller tung oljan är. För varje scenario testade de tre standardupplägg för injektions‑ och produktionsbrunnar: ett five‑spot‑nät där injektorer sitter omgivna av producenter, ett förskjutet line‑drive‑mönster och ett perifert schema som injicerar vatten främst runt fältets kanter. Simulatorn rapporterade hur mycket olja som slutligen kunde återvinnas i varje fall.
Att lära upp en snabb proxy att härma simulatorn
I stället för att förlita sig på långsamma simuleringar för alltid, tränade teamet enkla maskininlärningsmodeller — specifikt linjär regression — för att lära sambandet mellan de varierade indata och den slutliga oljeåtervinningen för varje brunns‑mönster. Dessa modeller fungerar som "proxyer": när de väl är tränade kan de förutsäga återvinning på en bråkdel av en sekund. Forskarna delade noggrant upp data i tränings‑ och testset och kontrollerade prestanda över flera uppdelningar. För alla tre mönstren reproducerade modellerna simulatorns resultat med hög trohet, förklarade mer än 93 procent av variationen i återvinning och höll prediktionsfelen mycket små. I praktiken destillerades den tunga fysikbaserade simulatorn ner till lättviktiga ekvationer som fortfarande beter sig på ett fysikaliskt sannolikt sätt.
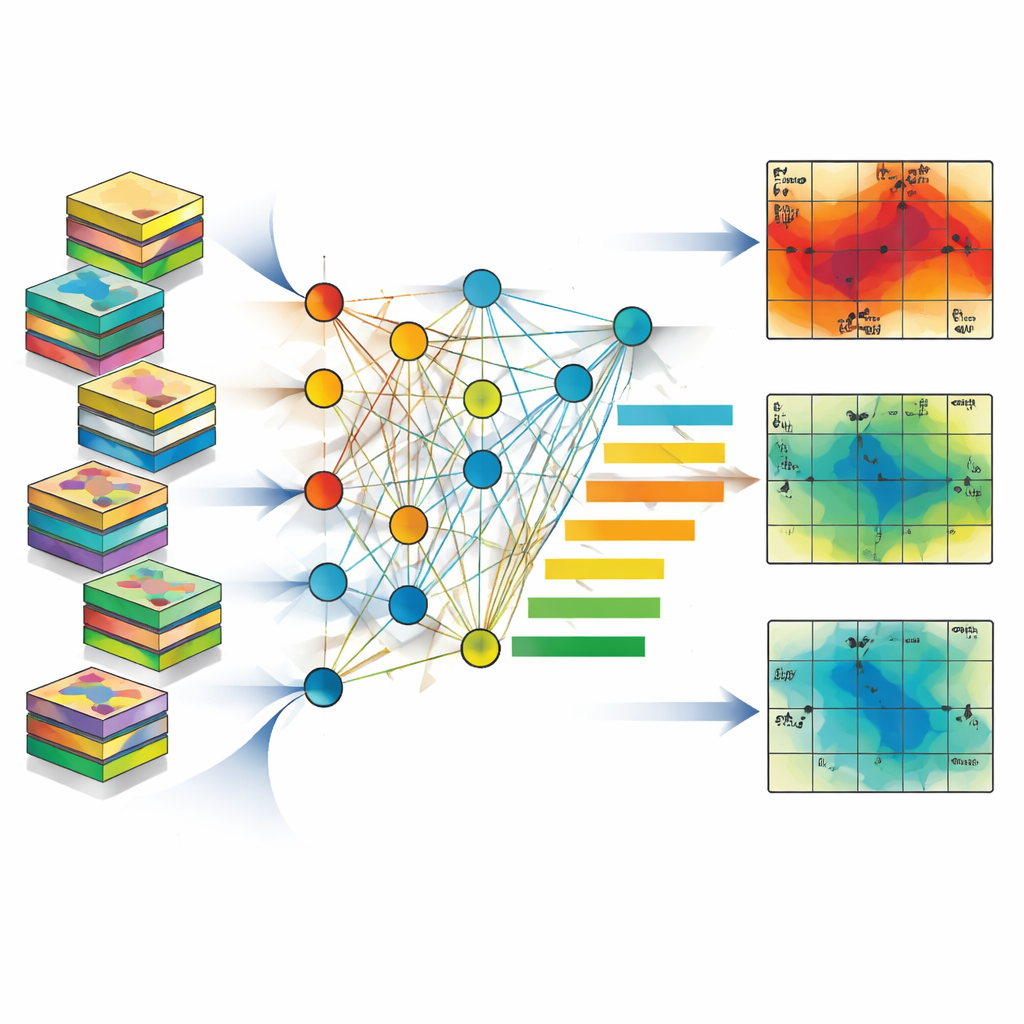
Vad som verkligen styr hur mycket olja som kommer ut
Med dessa snabba proxymodeller i handen undersökte författarna vilka faktorer som betyder mest. Genom att lätt förvränga varje indata i tur och ordning och se hur mycket prediktionerna försämrades fann de att mängden olja som blir kvar fast i berget efter översköljning — kallad residual oljesaturation — var den klart dominerande faktorn och stod för nära 40 procent eller mer av den prediktiva kraften över alla mönster. Oljans kvalitet spelade också roll: lättare oljor flöt lättare och ökade återvinningen, medan berg som tillät vatten att röra sig alltför lätt tenderade att orsaka tidig vatten"‑breakthrough" och minskad svepning. Intressant nog berodde injektionshastighetens betydelse starkt på mönstret. I det perifera schemat hade hur hårt vattnet pressades in en mycket större inverkan än i det rutnätsliknande five‑spot‑upplägget, vilket visar att olika brunnsarrangemang svarar på olika spakar.
Från datorinsikt till fältbeslut
Genom att sätta ihop dessa delar visar studien att det inte finns ett universellt bästa waterflood‑mönster. I det simulerade Bahariya‑fältet gav det perifera upplägget den högsta slutliga återvinningen, följt av det förskjutna line‑drive‑mönstret och därefter five‑spot‑mönstret. Men denna rangordning framträdde först efter att de specifika bergstrukturerna och vätskeegenskaperna i denna reservoar tagits i beaktande. Det hybrida arbetsflödet — att använda simuleringar för att generera data och sedan maskininlärning för att analysera dem snabbt — erbjuder fältingenjörer ett praktiskt sätt att sålla bland många waterflood‑alternativ, förstå vilka parametrar som verkligen betyder något och finjustera injektionsstrategier utan att köra tusentals fulla simuleringar. För en lekmannaläsare är slutsatsen enkel: genom att låta datorer både följa fysikens lagar och lära av data kan operatörer få mer olja ur samma berg samtidigt som vatten‑ och datorkapaciteter används mer effektivt.
Citering: Gad, R., Salem, A.M., El Farouk, O.M. et al. A hybrid simulation-machine learning proxy model for waterflood design optimization in the Bahariya Formation. Sci Rep 16, 14023 (2026). https://doi.org/10.1038/s41598-026-49561-5
Nyckelord: waterflooding, maskininlärning, oljeutvinning, reservoarsimulering, Bahariya‑formationen