Clear Sky Science · zh
由机器学习驱动的聚类用于勾勒 5G 网络上行吞吐量
为什么手机上传速度更快很重要
直播活动、参加视频通话或从手机发送大文件,这些都取决于数据从设备返回网络的速度——即上行链路。尽管第五代(5G)移动网络承诺极快的速率,但要确保在拥挤场景中每位用户都能享受平稳可靠的服务并非易事。本文探讨了简单的机器学习如何帮助某个 5G 小区同时管理多位高需求用户,提高上传速度并实现更公平的资源分配。
现实世界中的拥挤微小区
研究聚焦于“皮区小区”(picocell),一种覆盖半径最多 250 米、服务大约十五位附近用户的小型 5G 基站——想象一下繁忙的咖啡馆、办公楼层或体育场角落。作者并未假定理想条件,而是模拟了四种现实的无线环境,包含信号衰落与路径损耗等常见效应,模拟无线电波传播并被障碍物反射的情况。每位用户被分配到特定的服务类型——音频流、视频通话或高清视频——每种服务都有必须满足的最低数据率,才能保证体验流畅。系统为每位用户计算其信号强度、所受干扰以及回传基站的链路容量。
5G 承诺未达预期时
在引入机器学习之前,研究人员先考察如果按更传统的方式处理,这个小型网络能为用户提供怎样的服务。他们发现只有 15 位用户中 9 位(60%)实际获得了满足其服务最低要求的容量。有些用户享有数兆比特每秒的吞吐量,而另一些用户则勉强只有几十千比特,导致通话卡顿或视频停滞。这种不平衡产生于用户在复杂且不断变化的环境中共享无线资源,不同距离和角度处的设备为有限带宽竞争。
让数据自我分组
为了解决这个问题,作者转向经典的无监督机器学习方法——聚类。网络不再孤立地对待每位用户,而是将具有相似信道条件和服务需求的用户分为一组。研究比较了三种聚类方法——K‑means、DBSCAN 和高斯混合模型(GMM),但发现 K‑means 在该任务上表现最好。它既简单又快速,计算复杂度随用户数量线性增长,这对忙碌 5G 小区的实时决策至关重要。算法对每位用户使用三项主要信息:信道质量、当前数据率和最低服务要求。经过对这些特征的合理归一化使其互不掩盖后,K‑means 将用户划分为三类,反映了无线条件与服务需求的结合。
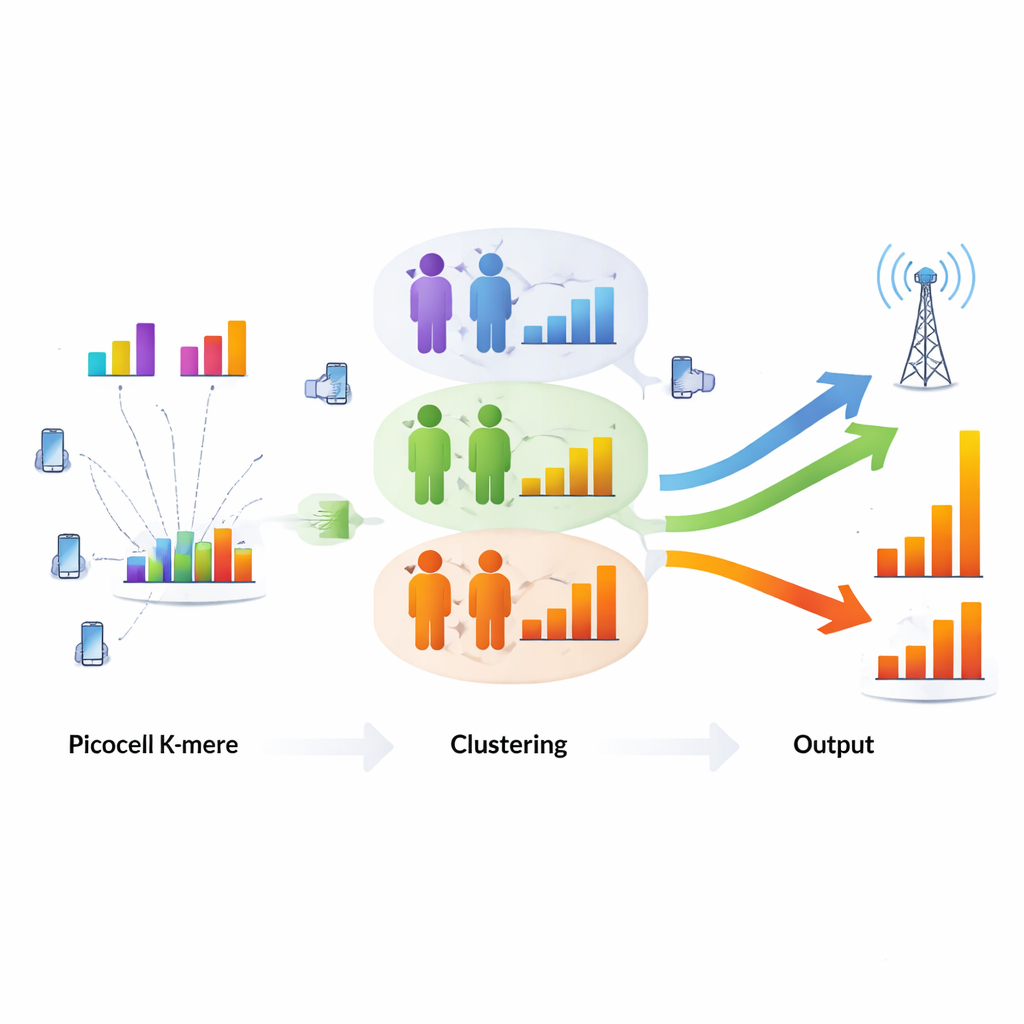
将智能分组转化为实际速率提升
一旦完成聚类,基站就能更智能地向每组分配带宽,有效地将资源“打包”给需求与条件相似的用户。这种重组显著提高了小区的总承载数据量。在输入特征归一化的情况下,累计吞吐量从 19.39 提升到 21.54 兆比特每秒——约提升 11%。在表现最好的聚类中,用户的累计速率达到 9.52 Mbps,且人均速率较高。同样重要的是,所有用户均满足其所分配服务的最低要求:视频通话、音频流和高清视频都达到或超过目标速率。研究还表明,随着更多用户加入,该方法仍保持高效,而一些运算开销更大的聚类技术其计算时间增长过快。
这对你未来的 5G 体验意味着什么
通俗地说,这项工作表明,即便是直接的机器学习方法也能成为 5G 上行连接的流量指挥官,将手机按合理方式分组并以能够提高总体容量且不落下个别用户的方式分配带宽。网络不再依赖僵化的“一刀切”规则,而是根据观察到的实际信号条件和应用需求进行自适应。作者建议未来系统可进一步实时更新聚类、采用更高级的学习方法并与聚焦信号引导(波束成形)结合。结合这些思路,有望在我们最依赖手机的拥挤场所实现快速且公平的 5G 上传体验。
引用: Ramesh, P., Bhuvaneswari, P.T.V. Machine learning driven clustering for silhouetting 5G network throughput. Sci Rep 16, 10583 (2026). https://doi.org/10.1038/s41598-026-45902-6
关键词: 5G 上行, 移动宽带, 机器学习, 用户聚类, 网络吞吐量