Clear Sky Science · ru
Кластеризация с помощью машинного обучения для улучшения пропускной способности 5G в аплинке
Почему более быстрые загрузки на телефоне важны
Трансляция прямой трансляции, участие в видеозвонке или отправка больших файлов с телефона зависят от того, как быстро данные могут перетекать с вашего устройства в сеть — то есть от аплинка. Хотя сети пятого поколения (5G) обещают очень высокие скорости, обеспечить плавную и надежную работу для каждого пользователя в многолюдном месте — задача непростая. В этой статье рассматривается, как простые методы машинного обучения могут помочь 5G‑ячейке обслуживать многих требовательных пользователей одновременно, повышая скорость загрузки и обеспечивая более справедливое распределение ресурсов.
Переполненная маломощная ячейка в реальных условиях
Исследование сосредоточено на «пикоячейке», небольшой 5G‑базовой станции, которая обслуживает всего пятнадцать соседних пользователей в радиусе до 250 метров — представьте оживлённое кафе, этаж офиса или угол стадиона. Вместо предположения о идеальных условиях авторы моделируют четыре реалистичных беспроводных окружения, учитывая обычные эффекты, такие как затухание сигнала и затраты пути по мере распространения радиоволн и их отражений от препятствий. Каждому пользователю назначается определённый тип сервиса — аудиопоток, видеозвонки или высококачественное видео — каждый из которых требует минимальной скорости передачи данных для комфортного использования. Система вычисляет для каждого пользователя силу его сигнала, величину интерференции и результирующую пропускную способность канала до базовой станции.
Когда обещания 5G не оправдываются
До применения машинного обучения исследователи анализируют, насколько хорошо эта маленькая сеть обслуживает пользователей при более традиционном подходе. Они обнаруживают, что только 9 из 15 пользователей (60%) фактически получают достаточно пропускной способности, чтобы удовлетворить минимальные требования их сервиса. Некоторые пользователи получают несколько мегабит в секунду, тогда как другие едва добираются до нескольких десятков килобит, что приводит к прерывистым звонкам или зависанию видео. Такое неравенство возникает потому, что пользователи делят радиоресурсы в сложной, постоянно меняющейся среде, где устройства на разных расстояниях и под разными углами относительно базовой станции конкурируют за ограниченную полосу.
Позволяя данным группироваться самостоятельно
Чтобы справиться с этой проблемой, авторы обращаются к классическому неконтролируемому методу машинного обучения — кластеризации. Вместо того чтобы рассматривать каждого пользователя по‑отдельности, сеть группирует пользователей с похожими условиями канала и потребностями сервиса. В исследовании сравниваются три метода кластеризации — K‑means, DBSCAN и гауссовские смеси — и выясняется, что K‑means лучше всего подходит для этой задачи. Он прост и быстр, масштабируется линейно по числу пользователей, что важно для принятия решений в реальном времени в загруженных 5G‑ячейках. Алгоритм использует три основных показателя для каждого пользователя: качество канала, текущую скорость передачи и минимально требуемую скорость сервиса. После аккуратного масштабирования этих признаков, чтобы ни один не доминировал, K‑means формирует три кластера пользователей, отражающие как радиоусловия, так и требования сервиса.
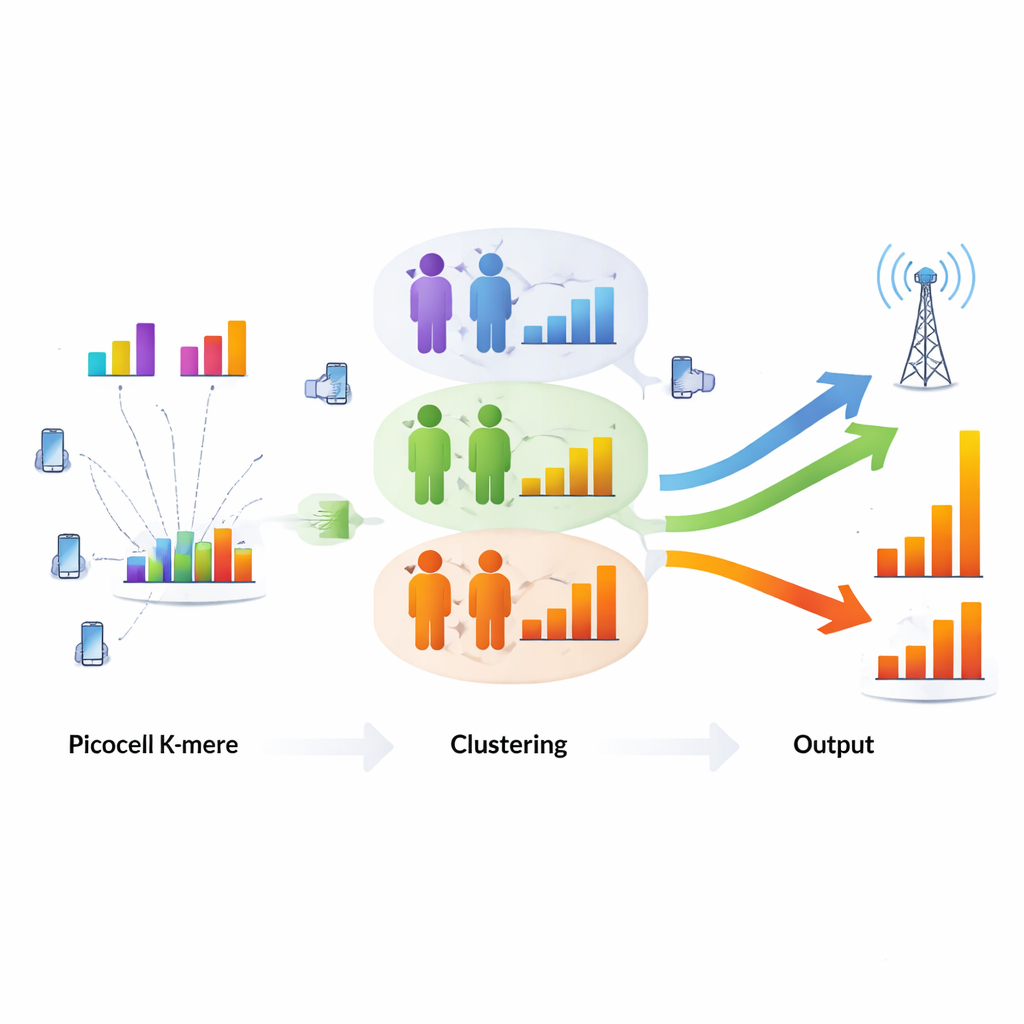
Как умная группировка превращается в реальное увеличение скорости
После кластеризации базовая станция может распределять полосу между группами более разумно, фактически «упаковывая» ресурсы для пользователей с похожими потребностями и условиями. Такая реорганизация существенно увеличивает общий объём данных, передаваемых ячейкой. При нормализации входных признаков суммарная пропускная способность возрастает с 19,39 до 21,54 мегабита в секунду — примерно на 11%. В наилучшей группе пользователи в совокупности достигают суммарной скорости 9,52 Мбит/с с высокой средней скоростью на пользователя. Не менее важно, что теперь каждый пользователь удовлетворяет минимальные требования своего сервиса: видеозвонки, аудиопотоки и HD‑видео работают на или выше целевых скоростей. Исследование также показывает, что этот подход остаётся эффективным по мере увеличения числа пользователей, в отличие от более тяжёлых методов кластеризации, время работы которых растёт слишком быстро.
Что это значит для вашего будущего опыта с 5G
Проще говоря, работа демонстрирует, что даже прямолинейные методы машинного обучения могут выступать в роли диспетчера трафика для 5G‑аплинка, группируя телефоны в осмысленные наборы и распределяя полосу так, чтобы повысить общую пропускную способность и не оставлять пользователей в невыгодном положении. Вместо опоры на жёсткие универсальные правила сеть адаптируется к реальным условиям сигнала и требованиям приложений, которые она наблюдает. Авторы предлагают, что будущие системы могли бы идти дальше — обновляя кластеры в реальном времени, применяя более продвинутые методы обучения и сочетая это с целевым управлением лучом (beamforming). В совокупности эти идеи могут помочь сделать обещание быстрых и справедливых 5G‑загрузок реальностью в многолюдных местах, где мы больше всего полагаемся на наши телефоны.
Цитирование: Ramesh, P., Bhuvaneswari, P.T.V. Machine learning driven clustering for silhouetting 5G network throughput. Sci Rep 16, 10583 (2026). https://doi.org/10.1038/s41598-026-45902-6
Ключевые слова: 5G восходящая линия, мобильный широкополосный доступ, машинное обучение, кластеризация пользователей, пропускная способность сети