Clear Sky Science · zh
用于战斗模拟空间推理的大型语言模型指挥官代理框架
为重要决策提供更智能的地图
现代人工智能能写文章、通过考试,但在依赖地理信息的决策上仍然吃力——例如在战场上部署部队或在复杂地形中安全机动。本论文提出了“Geo-Commander”,一个不仅教会大型语言模型阅读与推理、还教其“用地图思考”的AI系统,使其能够在详细的战斗模拟中建议战术上合理的位置。
单靠文字还不够
大型语言模型在处理文本推理方面表现出色,但现实决策往往取决于位置、地形如何,以及条件如何随时间变化。在军事模拟中,位置选择失误可能意味着暴露在敌方火力下或错失关键机会。以往系统要么依赖僵化的手工规则,要么侧重于长期规划却缺乏对具体位置的细粒度控制。视觉语言模型可以查看地图图像,但往往把它们当作静态图片,忽略了在战斗中重要的更深层次空间关系和可视线变化。言语推理与空间理解之间的这一差距限制了当今AI在以地理为核心的任务中的实用性。
将地形转化为结构化的游乐场
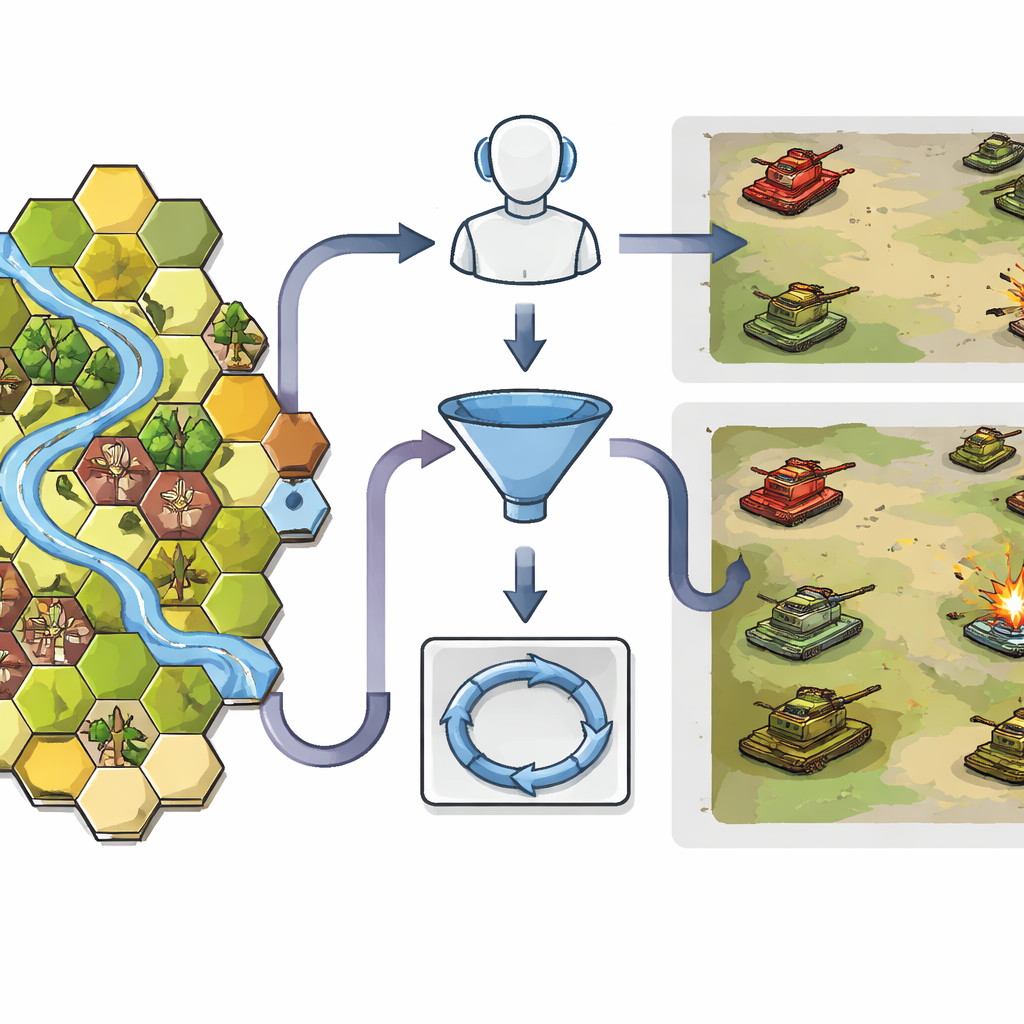
Geo-Commander 通过为AI提供高度结构化的战场视图来解决这个问题。地形被转换为六边形网格,这是战争游戏中常见的格式,每个格子包含简洁但丰富的信息:位置、高程以及地面类型,例如开阔地、林地、建筑或河流。这种结构帮助AI理解谁能看到谁、谁能移动到何处。第一个模块称为Geo-Choice,像一个智能筛选器。它不是让模型在数千个可能位置中逐一考虑,而是利用基本战术知识将地图缩小到最多十个符合当前任务的有前景候选点——无论任务是躲避敌人、远程狙击,还是近距离冲锋。
让AI逐步推理每一步
在将地图缩小后,第二个组件——空间化的 ReAct 链(Spatialized ReAct Chain)允许AI以显式的循序循环来推理其选项。语言模型检查每个候选点,调用专门的工具来测量与敌方的距离、友军到达所需的时间,以及该点的视野宽度。在每轮计算后它会修正判断,类似于人类指挥官查看地图、询问射程估计然后重新评估。关键是,这一过程产生可解释的推理轨迹:系统可以用通俗语言说明为何某一格子在掩护、可见性或机动潜力上优于其他备选项。
将系统付诸检验
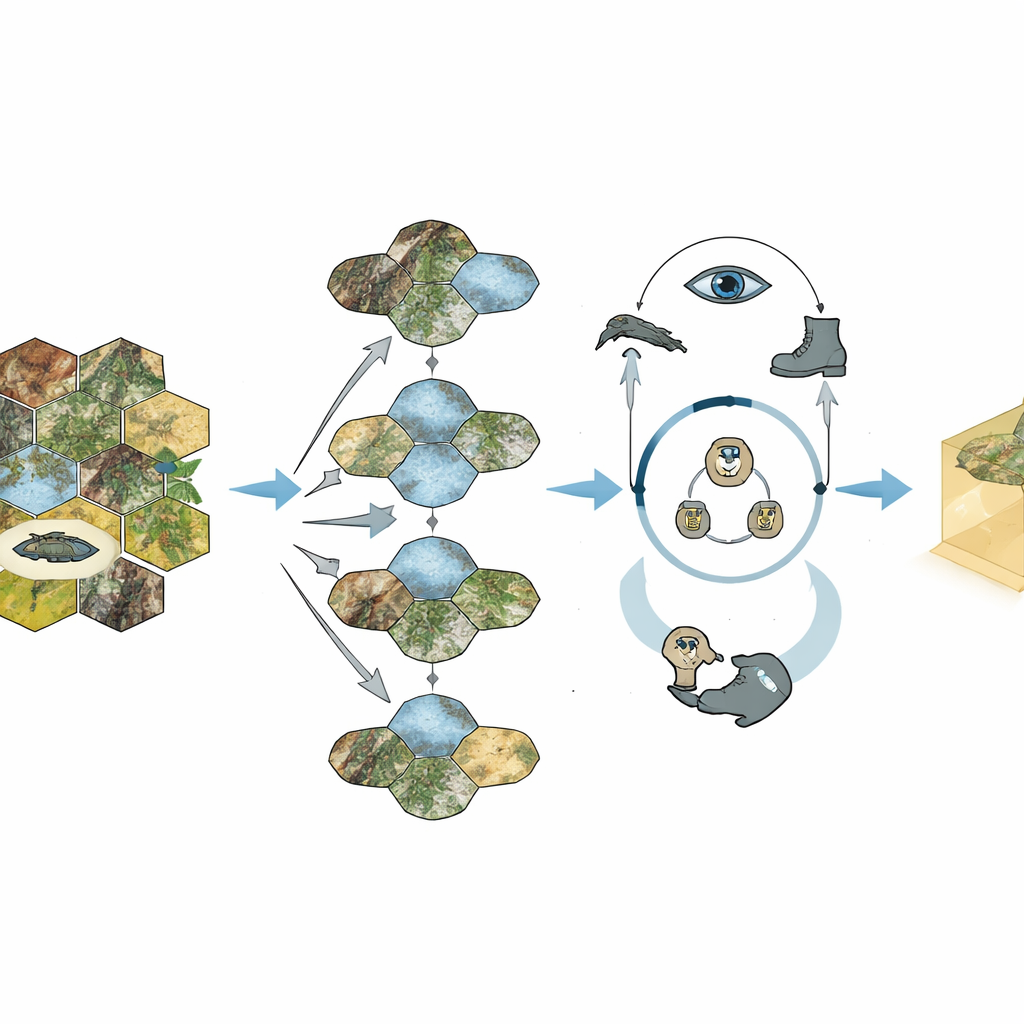
研究人员在专业级坦克战斗模拟中评估了Geo-Commander。他们设计了“静态”任务——AI在固定地图上选择最佳躲藏、狙击或突击点,以及“动态”战斗——红蓝两方坦克分队在多变地形中机动与交战。人类军事专家首先创建了详细的格子战术优劣评分表,提供了严格的基准。完整的Geo-Commander系统(结合Geo-Choice筛选和推理循环)在持续挑选位置方面优于标准的视觉语言模型、其简化版本以及现有的基于规则的指挥系统。在完整的模拟战斗中,它甚至超过了通过一百万次自对弈训练出的最先进强化学习代理的表现。
从战争游戏到更广泛的应用
Geo-Commander 展示了在赋予适当的空间结构和工具时,语言模型可以成为胜任的“地图思考者”,而不仅仅是处理更多文本。通过将基于网格的地形编码与显式的推理、行动与观测循环相结合,该系统把不透明的AI判断转化为可追溯、战术上合理的建议。研究聚焦于坦克战斗模拟并且限定在虚拟场景内,但相同的思想可应用于灾难响应规划、搜救路径制定或任何依赖下一步去向决策的任务。简言之,这项工作展示了AI从空谈世界到实地导航的一条路径,同时人类仍然牢牢掌握指挥权。
引用: Chen, Yb., Ping, Y., Zhou, S. et al. A framework of large language model commander agent for spatial reasoning in combat simulation. Sci Rep 16, 13431 (2026). https://doi.org/10.1038/s41598-026-43365-3
关键词: 空间推理, 战斗模拟, 大型语言模型, 决策支持, 地理空间人工智能