Clear Sky Science · nl
Een raamwerk van commandant-agenten met grote taalmodellen voor ruimtelijk redeneren in combatsimulatie
Slimmere kaarten voor beslissingen met grote belangen
Moderne kunstmatige intelligentie kan essays schrijven en examens halen, maar worstelt nog steeds met beslissingen die afhangen van geografie — zoals waar troepen op het slagveld te plaatsen of hoe veilig door complex terrein te bewegen. Dit artikel introduceert “Geo-Commander”, een AI-systeem dat grote taalmodellen niet alleen leert lezen en redeneren, maar ook “met kaarten te denken”, waardoor ze assistenten worden die tactisch verantwoorde posities kunnen voorstellen in gedetailleerde combatsimulaties.
Waarom woorden alleen niet genoeg zijn
Grote taalmodellen blinken uit in tekstueel redeneren, maar echte wereldbeslissingen hangen vaak af van waar iets zich bevindt, hoe het terrein eruitziet en hoe omstandigheden in de tijd veranderen. In militaire simulaties kan een slechte positiekeuze betekenen dat je blootgesteld wordt aan vijandelijk vuur of een cruciale kans mist. Eerdere systemen vertrouwden ofwel op starre, handgemaakte regels of specialiseerden zich in langetermijnplanning zonder fijnmazige controle over specifieke locaties. Visuele taalmodellen kunnen kaartbeelden bekijken, maar behandelen die vaak als statische plaatjes en missen daarmee diepere ruimtelijke relaties en veranderende zichtlijnen die in gevechten van belang zijn. Deze kloof tussen verbaal redeneren en ruimtelijk begrip beperkt hoe nuttig AI vandaag de dag is voor taken met veel geografische relevantie.
Het terrein omzetten in een gestructureerde speelplek
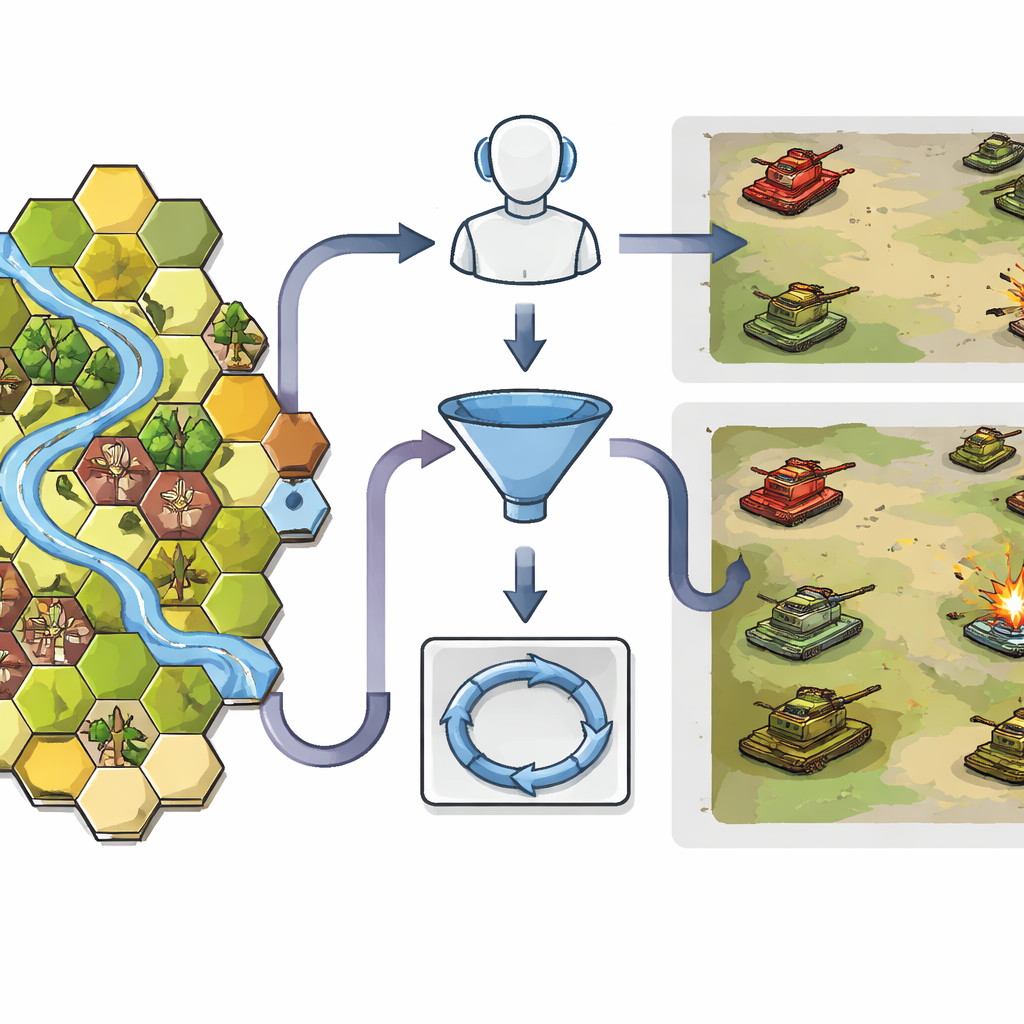
Geo-Commander pakt dit probleem aan door de AI een sterk gestructureerd overzicht van het slagveld te geven. Het terrein wordt omgezet in een zeshoekig raster, een vertrouwd formaat uit oorlogsspellen, waarbij elke cel eenvoudige maar rijke informatie draagt: positie, hoogte en het type ondergrond, zoals open velden, bos, gebouwen of rivieren. Deze structuur helpt de AI te begrijpen wie wie kan zien en wie waar naartoe kan bewegen. Een eerste module, Geo-Choice, fungeert als een slimme filter. In plaats van het model duizenden mogelijke locaties te laten overwegen, gebruikt het basis tactische kennis om de kaart te beperken tot hooguit tien veelbelovende kandidaatplekken die passen bij de huidige taak — of het nu gaat om verbergen voor de vijand, langeafstands sluipschieten of een directe aanval.
De AI elke zet laten overdenken
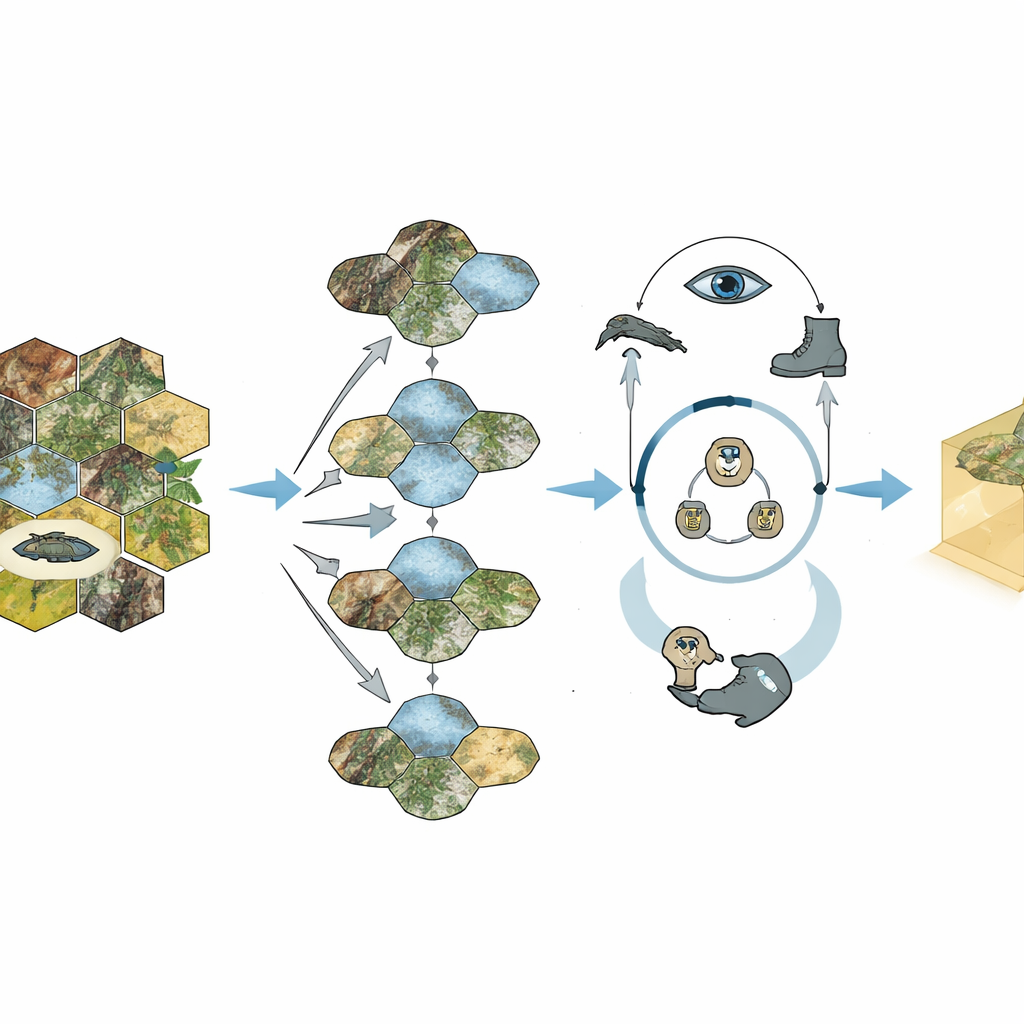
Wanneer de kaart is teruggebracht, stelt een tweede component, de Spatialized ReAct Chain, de AI in staat haar opties expliciet stap voor stap door te denken. Het taalmodel bekijkt elk kandidaatpunt, roept gespecialiseerde hulpmiddelen aan om te meten hoe ver het van vijanden is, hoe lang het voor vriendelijke eenheden duurt om er te komen en hoe breed het gezichtsveld zou zijn. Na elke ronde berekeningen herziet het zijn oordeel, vergelijkbaar met een menselijke commandant die een kaart controleert, reikwijdte-schattingen opvraagt en vervolgens opnieuw afweegt. Cruciaal is dat dit proces een interpreteerbaar spoor van redenering oplevert: het systeem kan in gewone taal uitleggen waarom een gekozen rastervak betere dekking, zicht of manoeuvreermogelijkheden biedt dan de alternatieven.
Het systeem op de proef stellen
De onderzoekers evalueerden Geo-Commander in een professionele tanksimulatie. Ze ontwierpen zowel “statische” taken, waarbij de AI gewoon het beste verstop-, sluipschiet- of aanvalspunt op een vaste kaart moest kiezen, als “dynamische” gevechten, waarin rode en blauwe tankdetachementen manoeuvreerden en vochten over gevarieerd terrein. Menselijke militaire experts maakten eerst een gedetailleerde beoordelingslijst van welke rastercellen tactisch superieur waren, wat een moeilijke referentie opleverde. Het volledige Geo-Commander-systeem, dat de Geo-Choice-filter en de redeneerlus combineert, koos consequent betere posities dan standaard visuele taalmodellen, vereenvoudigde versies van zichzelf en een bestaand regelsystematisch commandantmodel. In volledige gesimuleerde gevechten presteerde het zelfs beter dan een state-of-the-art reinforcement learning-agent die was getraind met een miljoen self-play games.
Van oorlogsspellen naar bredere toepassingen
Geo-Commander laat zien dat taalmodellen competente “kaartdenkers” kunnen worden wanneer ze de juiste ruimtelijke structuur en hulpmiddelen krijgen, niet alleen meer tekst. Door rastergebaseerde terreinencoding te combineren met een expliciete cyclus van redeneren, handelen en waarnemen, verandert het systeem ondoorzichtige AI-oordeelvellingen in traceerbare, tactisch verantwoorde aanbevelingen. Hoewel de studie zich richt op tanksimulaties en veilig binnen virtuele scenario’s blijft, zouden dezelfde ideeën toepasbaar kunnen zijn op rampenresponsplanning, zoek- en reddingsroutes of elke taak waarbij beslissingen afhangen van waar je vervolgens naartoe moet gaan. In eenvoudige termen toont het werk een pad voor AI om van praten over de wereld naar het navigeren erin te bewegen, met mensen nog steeds stevig aan het roer.
Bronvermelding: Chen, Yb., Ping, Y., Zhou, S. et al. A framework of large language model commander agent for spatial reasoning in combat simulation. Sci Rep 16, 13431 (2026). https://doi.org/10.1038/s41598-026-43365-3
Trefwoorden: ruimtelijk redeneren, combatsimulatie, grote taalmodellen, besluitvormingondersteuning, geospatiale AI