Clear Sky Science · zh
基于超图的对比嵌入与注意力融合用于皮肤癌检测
为何更聪明的皮肤检查很重要
皮肤癌是最常见的癌症之一,黑色素瘤虽相对罕见,但若发现迟则尤为致命。医生可以使用对痣和斑点的放大照片(称为皮肤镜图像)来寻找异常,但许多病变看起来非常相似。一些危险癌症在真实世界中很少见,因此在人工智能系统的训练数据中也相对稀缺。本文提出了一种新的计算机视觉框架,称为 C2G‑HFMTA,旨在更可靠地识别皮肤癌,特别是那些罕见但关键的病例,同时提供临床可解释的说明。
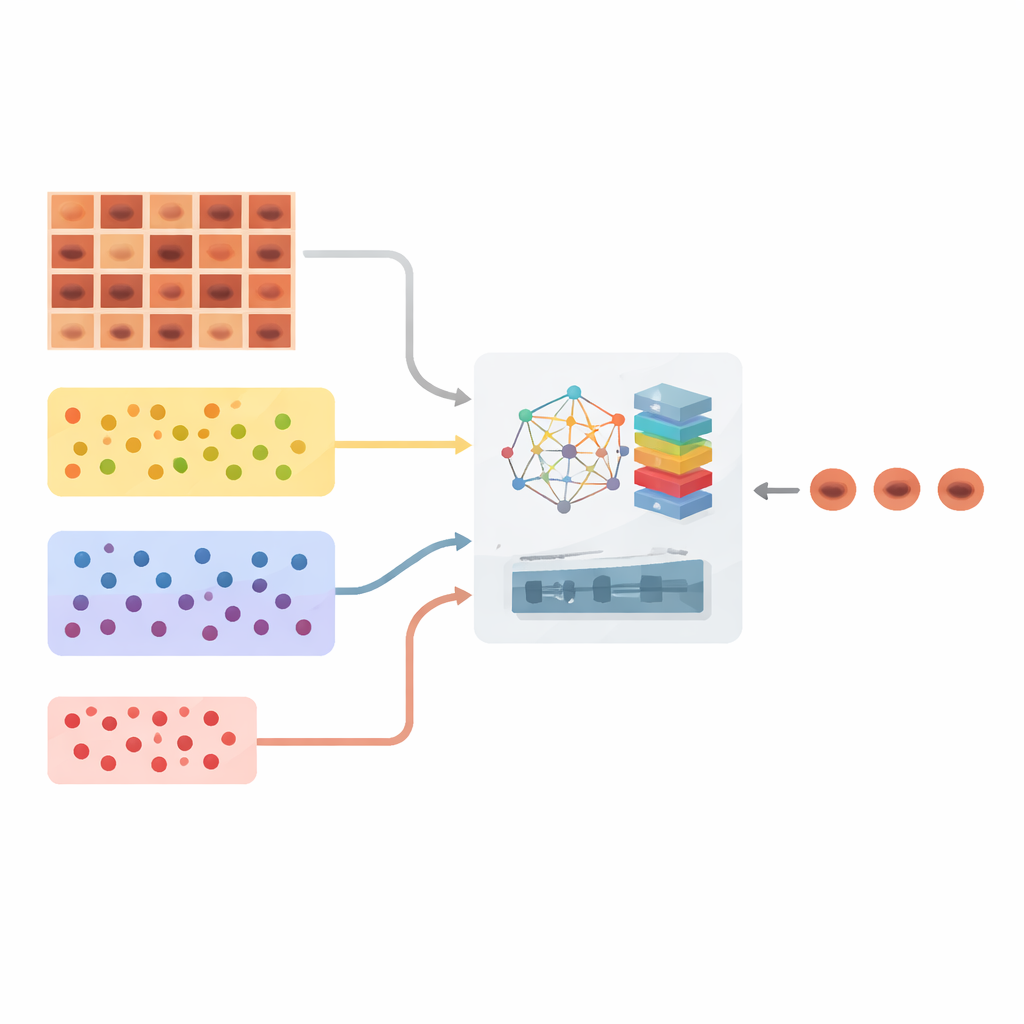
在常见与罕见皮损之间实现平衡
自动化皮肤癌筛查的一个主要障碍是数据不平衡:某些良性病变在数据集中出现数千次,而严重癌症或罕见病变可能只出现数十次。标准深度学习模型往往偏向多数类,默默忽视罕见类别,而这恰恰与医生的需求相反。作者通过首先重新组织大型的 HAM10000 皮肤镜数据集来应对这一问题,该数据集包含七类皮损的逾万张图像。他们称之为“基于类别的聚类分割”的策略,将图像分为三类——非常常见、适度常见和罕见病变——并确保在训练过程中算法对每一组给予有结构的关注,而不是被多数类所淹没。
教会系统理解病例之间的关系
框架不是简单地将图像输入神经网络并让其记忆模式,而是构建图像之间关系的抽象地图。利用强大的特征提取器(DenseNet201),每张病变图像被转换为数值指纹。这些指纹成为图中的节点,连接表示两个病变在外观上的相似性。作者进一步使用“超图”,可同时连接多个图像,从而捕捉更丰富的群体模式。在此结构之上,他们应用有监督的对比学习方案:来自相同诊断的图像在该抽象空间中被拉近,而不同诊断的图像被推远。关键在于,这一过程直接由真实的病变标签引导,而不是依赖强烈的图像扰动,因此诊断中重要的细微颜色和纹理得以保留。
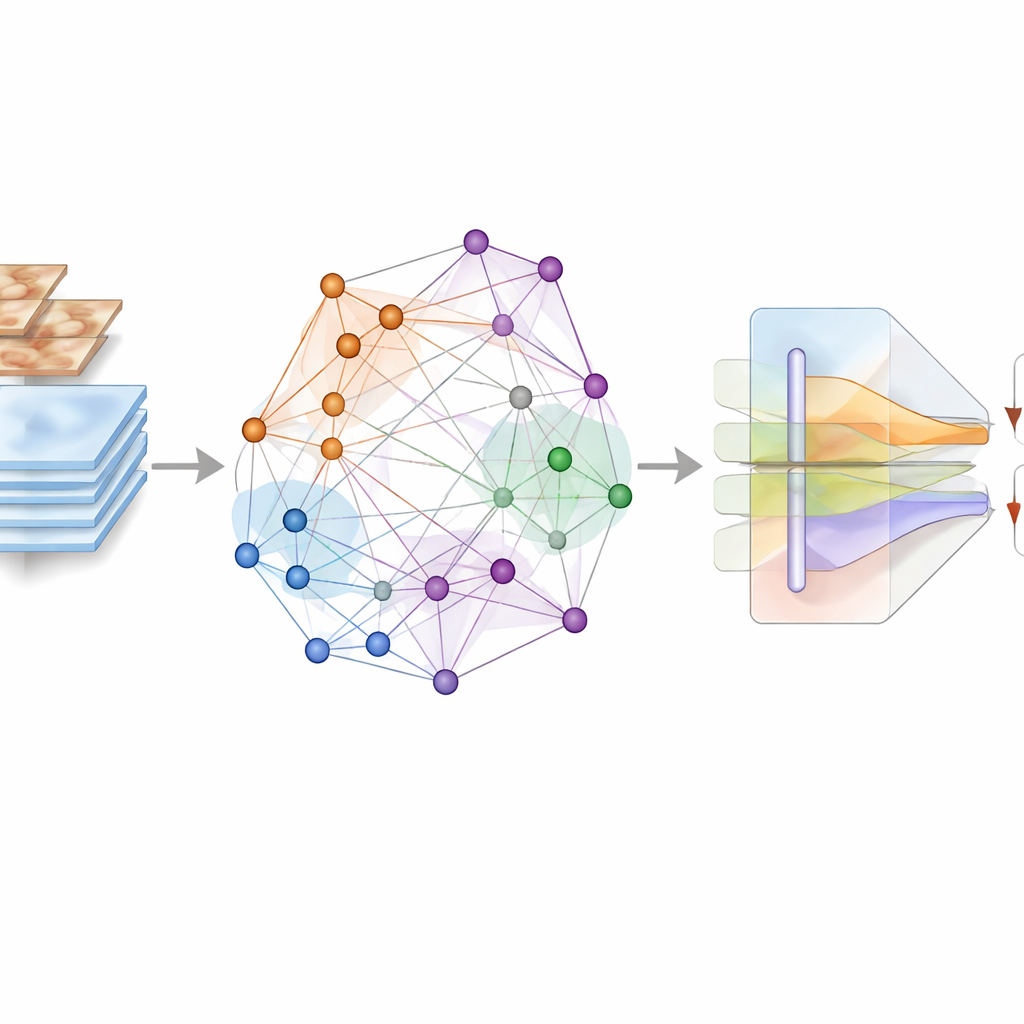
让语义引导注意力
第二个重要组成部分是基于注意力的融合模块,它将图结构学到的内容与图像的原始视觉细节结合起来。图衍生的表征编码了每个病变与数据集中其他样本的关系,类似于关于类别身份的高层“问题”。来自原始图像的像素级特征则充当“证据”。在多模态注意力块内,这两种信息流相互作用:来自图的语义线索引导模型将注意力集中于图像中有助于区分难以辨认病变的关键区域和模式。残差连接与多尺度处理有助于保留细微特征,例如轻微的色素变化、边界不规则或微小血管,这些细节常常将危险病变与无害病变区分开来。
模型的性能如何
研究者在 HAM10000 数据集上使用严格的实验方案评估了他们的框架,包括五折交叉验证并与 30 多种流行的卷积与变换器模型进行了广泛比较。他们的方法达到约 93% 的总体准确率及相近的 F1 分数,远超所有基线模型。更重要的是,提升在绝大多数系统表现不佳的罕见病变类型上最为显著。额外的测试表明,每个组件——基于类别的聚类、超图对比嵌入和注意力融合——都对性能有显著贡献。t‑SNE、UMAP 与 Grad‑CAM 热图等可视化工具显示,该方法产生了更清晰的病变类型簇,并将注意力集中在具有医学意义的图像区域,例如黑色素瘤的边界不规则处或某些癌前病变的致密角质区。
这对未来的皮肤检查意味着什么
简而言之,这项研究提出了一个在检查皮肤病变时更加公平且更有辨别力的 AI 框架。通过明确平衡常见与罕见病例、绘制图像之间的关系并让这些关系指导模型在每张图片中“观察”的位置,C2G‑HFMTA 在基于计算机的皮肤癌诊断上取得了实质性改进。尽管该系统仍需在更大且更多样化的临床数据集上进行验证,但它指向了未来可能帮助皮肤科医生—甚至家庭筛查应用—更早且更有把握地发现危险皮肤癌的工具,同时不忽视那些最重要的罕见病例。
引用: Banerjee, T., Chhabra, P., Kumar, M. et al. Hypergraph-based contrastive embedding and attention fusion for detection of skin cancer. Sci Rep 16, 12808 (2026). https://doi.org/10.1038/s41598-026-43351-9
关键词: 皮肤癌检测, 皮肤镜图像 AI, 对比学习, 类别不平衡, 医学图像分析