Clear Sky Science · nl
Hypergraaf-gebaseerde contrastieve embedding en aandachtfusie voor de detectie van huidkanker
Waarom slimmer huidonderzoek ertoe doet
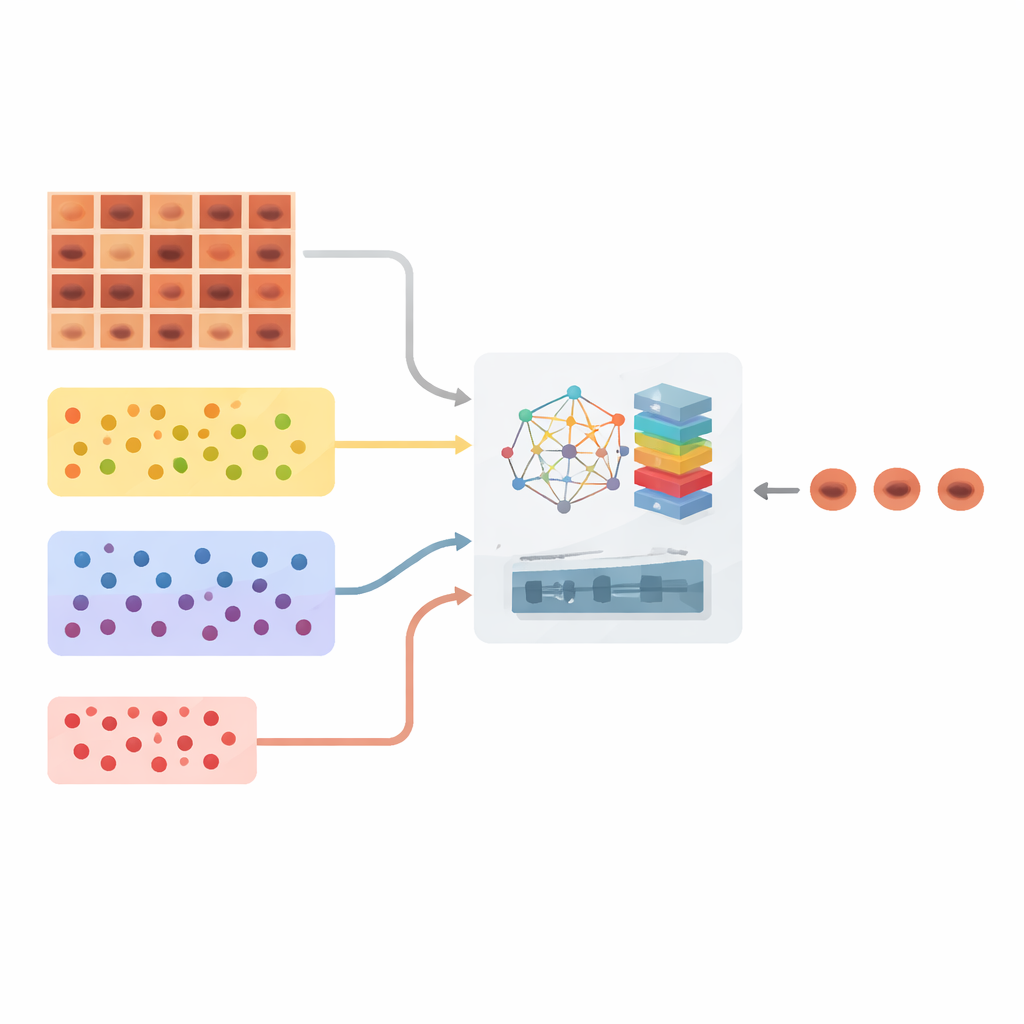
Huidkanker is een van de meest voorkomende vormen van kanker, en melanomen, hoewel relatief zeldzaam, zijn vooral dodelijk wanneer ze laat worden ontdekt. Artsen kunnen vergrote foto’s van moedervlekken en vlekken—dermoscopische beelden genoemd—gebruiken om problemen te zoeken, maar veel laesies lijken verwarrend veel op elkaar. Sommige gevaarlijke kankers zijn in het echt zeldzaam en daardoor schaars in trainingsdata voor AI-systemen. Dit artikel introduceert een nieuw computerzichtkader genaamd C2G‑HFMTA dat is ontworpen om huidkankers betrouwbaarder te herkennen, vooral de ongewone maar kritieke gevallen, en dat tegelijk verklaringen biedt die een clinici kan interpreteren.
Balanceren van veelvoorkomende en zeldzame huidvlekken
Een belangrijk obstakel bij geautomatiseerde screening op huidkanker is onevenwichtigheid: sommige goedaardige laesies komen duizenden keren voor in datasets, terwijl ernstige kankers of ongewone laesies misschien maar enkele tientallen keren voorkomen. Standaard diepe leermodellen neigen ertoe zich op de meerderheid te concentreren en de zeldzame klassen stilzwijgend te negeren—precies het tegenovergestelde van wat artsen willen. De auteurs pakken dit aan door eerst de grote HAM10000‑dermoscopiedataset te reorganiseren, die meer dan tienduizend beelden bevat verdeeld over zeven typen huidlaesies. Hun strategie, Clustered Class‑Based Segmentation genoemd, groepeert beelden in drie clusters—zeer veelvoorkomend, matig veelvoorkomend en zeldzaam—en zorgt ervoor dat het algoritme tijdens training gestructureerde aandacht geeft aan elke groep in plaats van te worden overspoeld door de meerderheidscases.
Het systeem leren hoe gevallen zich tot elkaar verhouden
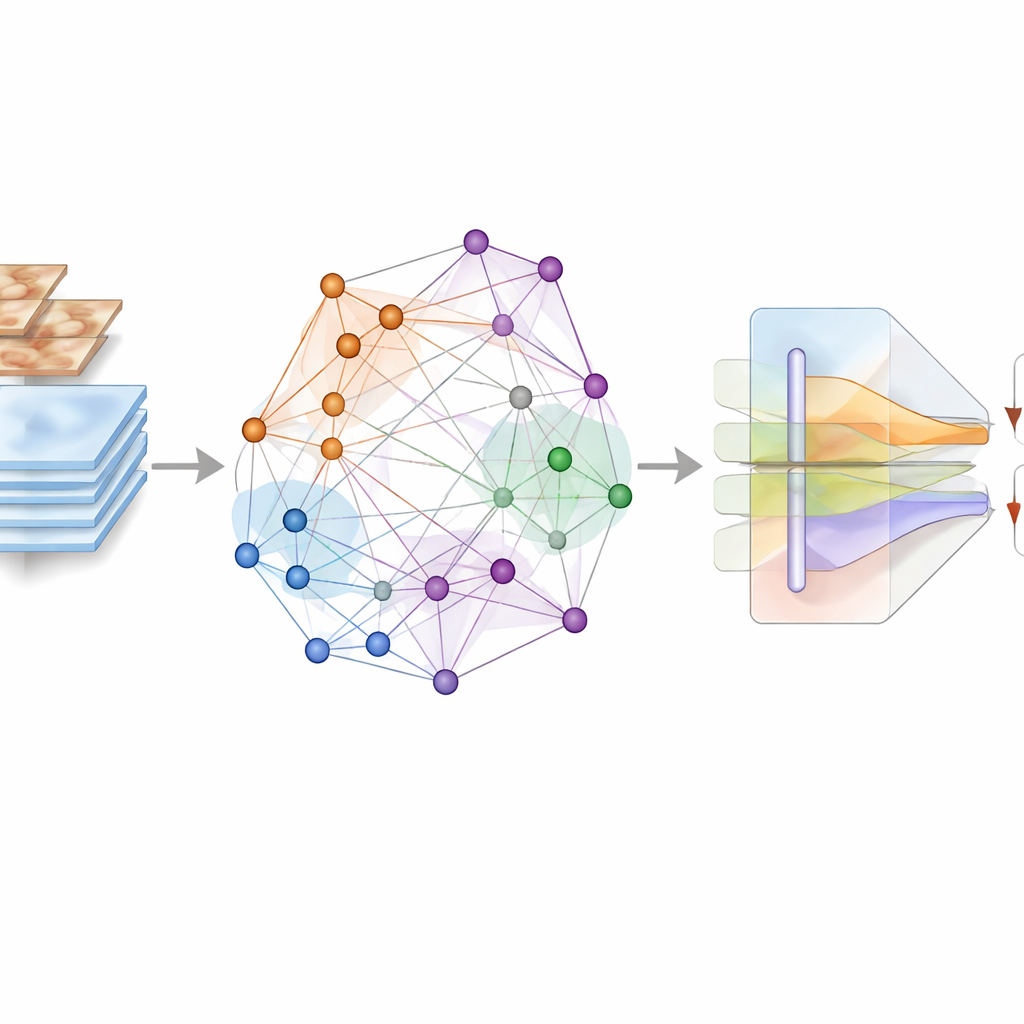
In plaats van beelden simpelweg in een neuraal netwerk te voeren en het netwerk patronen te laten onthouden, bouwt het kader een abstracte kaart van relaties tussen beelden. Met een krachtige feature‑extractor (DenseNet201) wordt elk laesiebeeld omgezet in een numerieke vingerafdruk. Deze vingerafdrukken worden knopen in een graaf waarin verbindingen laten zien hoe twee laesies op elkaar lijken. De auteurs gaan verder en gebruiken een “hypergraaf”, die meerdere beelden tegelijk kan verbinden en rijkere groepspatronen kan vastleggen. Bovenop deze structuur passen ze een gesuperviseerd contrastief leerschema toe: beelden met dezelfde diagnose worden dichter naar elkaar toegetrokken in deze abstracte ruimte, terwijl beelden met verschillende diagnoses uit elkaar worden geduwd. Cruciaal is dat dit proces direct wordt gestuurd door de echte laesielabels, niet door zware beeldvervormingen, zodat subtiele kleuren en texturen die belangrijk zijn voor de diagnose behouden blijven.
Betekenis laten leiden waar aandacht naar uitgaat
Het tweede belangrijke ingrediënt is een op aandacht gebaseerde fusie‑module die samenbrengt wat de graaf heeft geleerd met de ruwe visuele details uit de beelden. De door de graaf afgeleide representaties, die coderen hoe elke laesie zich verhoudt tot andere over de dataset, fungeren als een hoogwaardig “vraagstuk” over klasse‑identiteit. De pixelniveau‑kenmerken uit de originele beelden dienen als het “bewijs.” Binnen het multimodale aandachtblok werken deze twee stromen samen: de semantische aanwijzingen uit de graaf sturen het model om zijn aandacht te concentreren op regio’s en patronen in het beeld die het belangrijkst zijn om lastig te onderscheiden laesies uit elkaar te houden. Residuele verbindingen en multiscale verwerking helpen fijne details te behouden, zoals lichte kleurverschillen, onregelmatige randen of kleine bloedvaten, die vaak het verschil maken tussen een gevaarlijke laesie en een goedaardige.
Hoe goed het model presteert
De onderzoekers evalueerden hun kader op de HAM10000‑dataset met zorgvuldige experimentele protocollen, waaronder vijfvoudige cross‑validatie en uitgebreide vergelijkingen met meer dan 30 populaire convolutionele en transformer‑gebaseerde modellen. Hun methode bereikte ongeveer 93% algehele nauwkeurigheid en een vergelijkbare F1‑score, waarmee ze alle baselines ver uitstierven. Belangrijk is dat de winst het sterkst was voor de zeldzame laesietypen waar de meeste systemen moeite mee hebben. Aanvullende tests lieten zien dat elk onderdeel—de klassegebaseerde clustering, de hypergraaf‑contrastieve embedding en de aandachtfusie—meetbaar bijdroeg aan de prestatie. Visuele hulpmiddelen zoals t‑SNE, UMAP en Grad‑CAM‑heatmaps toonden aan dat de nieuwe methode duidelijkere clusters van laesietypen oplevert en de aandacht richt op medisch betekenisvolle beeldregio’s, zoals onregelmatige randen bij melanomen of dichte keratinegebieden in bepaalde precancereuze laesies.
Wat dit betekent voor toekomstige huidonderzoeken
Simpel gezegd presenteert deze studie een AI‑kader dat zowel eerlijker als scherper is bij het onderzoeken van huidlaesies. Door expliciet veelvoorkomende en zeldzame gevallen in balans te brengen, relaties tussen beelden in kaart te brengen en die relaties te laten bepalen waar het model “kijkt” in elk plaatje, verbetert C2G‑HFMTA de computerondersteunde diagnose van huidkanker aanzienlijk. Hoewel het systeem nog validatie nodig heeft op grotere en meer diverse klinische verzamelingen, wijst het op toekomstige hulpmiddelen die dermatologen—en zelfs thuis‑screeningapps—kunnen helpen gevaarlijke huidkankers eerder en met grotere zekerheid te detecteren, zonder de zeldzame, maar belangrijke gevallen uit het oog te verliezen.
Bronvermelding: Banerjee, T., Chhabra, P., Kumar, M. et al. Hypergraph-based contrastive embedding and attention fusion for detection of skin cancer. Sci Rep 16, 12808 (2026). https://doi.org/10.1038/s41598-026-43351-9
Trefwoorden: detectie van huidkanker, dermoscopie AI, contrastief leren, klassenongelijkheid, analyse van medische beelden