Clear Sky Science · it
Embedding contrattivo basato su ipergrafi e fusione attention per il rilevamento del cancro della pelle
Perché controlli cutanei più intelligenti sono importanti
Il cancro della pelle è uno dei tumori più comuni e il melanoma, sebbene relativamente raro, è particolarmente letale se diagnosticato in ritardo. I medici possono usare foto ingrandite di nei e macchie, chiamate immagini dermoscopiche, per individuare segnali di allarme, ma molte lesioni appaiono sorprendentemente simili tra loro. Alcuni tumori pericolosi sono rari nella pratica clinica e quindi scarsi nei dati di addestramento dei sistemi di intelligenza artificiale. Questo articolo introduce un nuovo framework di visione artificiale chiamato C2G‑HFMTA, progettato per rilevare i tumori cutanei in modo più affidabile, soprattutto nei casi poco comuni ma critici, fornendo allo stesso tempo spiegazioni interpretabili dal clinico.
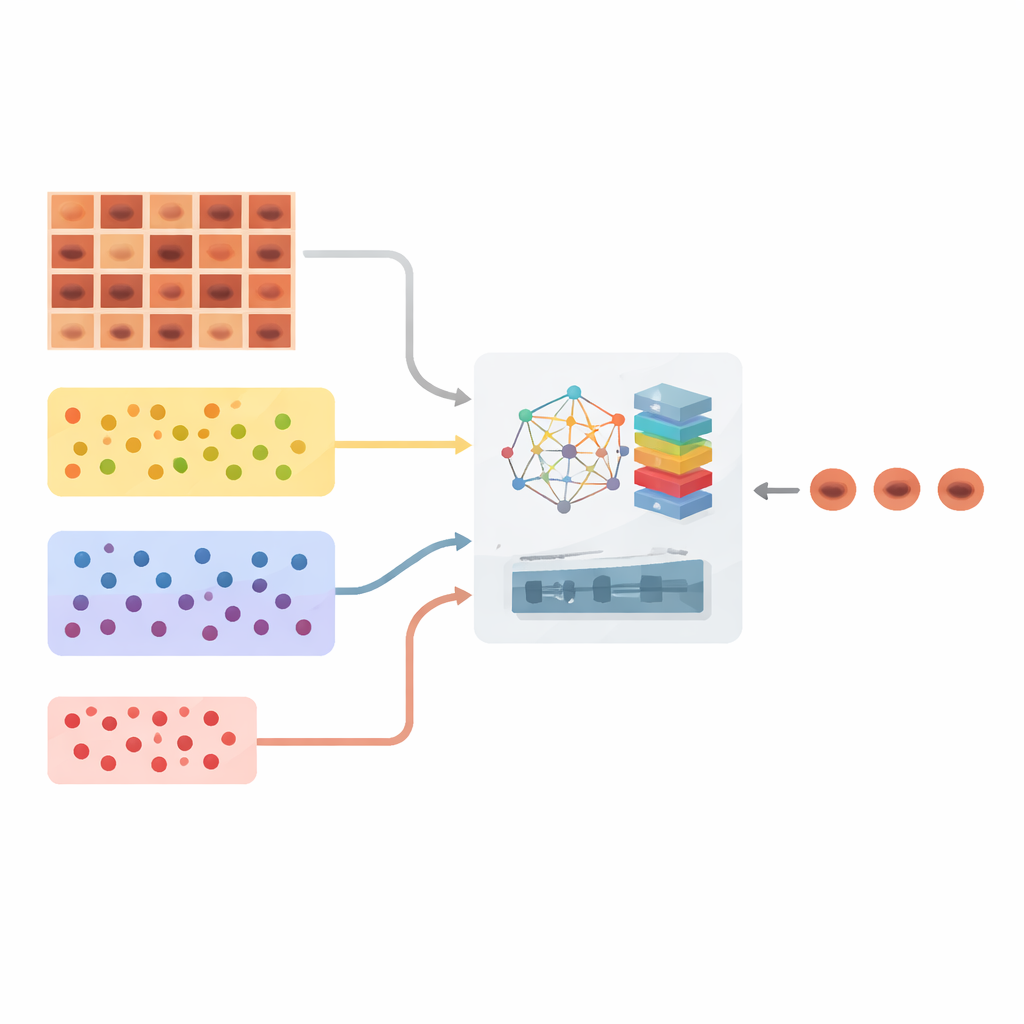
Bilanciare macchie cutanee comuni e rare
Un ostacolo importante nello screening automatizzato del cancro della pelle è lo squilibrio: alcune lesioni benigne compaiono migliaia di volte nei dataset, mentre tumori gravi o lesioni insolite possono apparire solo poche decine di volte. I modelli deep learning standard tendono a concentrarsi sulla maggioranza e a trascurare le classi rare, esattamente l’opposto di ciò che desiderano i medici. Gli autori affrontano questo problema riorganizzando innanzitutto il grande dataset dermoscopico HAM10000, che contiene più di diecimila immagini distribuite in sette tipi di lesioni cutanee. La loro strategia, chiamata Clustered Class‑Based Segmentation, raggruppa le immagini in tre cluster — lesioni molto comuni, moderately comuni e rare — e garantisce che, durante l’addestramento, l’algoritmo presti attenzione strutturata a ciascun gruppo anziché essere sopraffatto dai casi di maggioranza.
Insegnare al sistema come i casi sono correlati
Piuttosto che limitarsi a inserire le immagini in una rete neurale e chiedere di memorizzare pattern, il framework costruisce una mappa astratta delle relazioni tra le immagini. Utilizzando un potente estrattore di feature (DenseNet201), ogni immagine di lesione viene convertita in un’impronta numerica. Queste impronte diventano nodi in un grafo in cui le connessioni mostrano quanto due lesioni siano simili nell’aspetto. Gli autori vanno oltre e impiegano un “ipergrafo”, che può connettere più immagini contemporaneamente, cogliendo pattern di gruppo più ricchi. Sopra questa struttura applicano uno schema di apprendimento contrastivo supervisionato: le immagini con la stessa diagnosi vengono avvicinate in questo spazio astratto, mentre quelle con diagnosi diverse vengono spinte lontane. Fondamentale è che questo processo sia guidato direttamente dalle etichette reali delle lesioni, non da forti distorsioni dell’immagine, così da preservare i colori e le texture sottili importanti per la diagnosi.
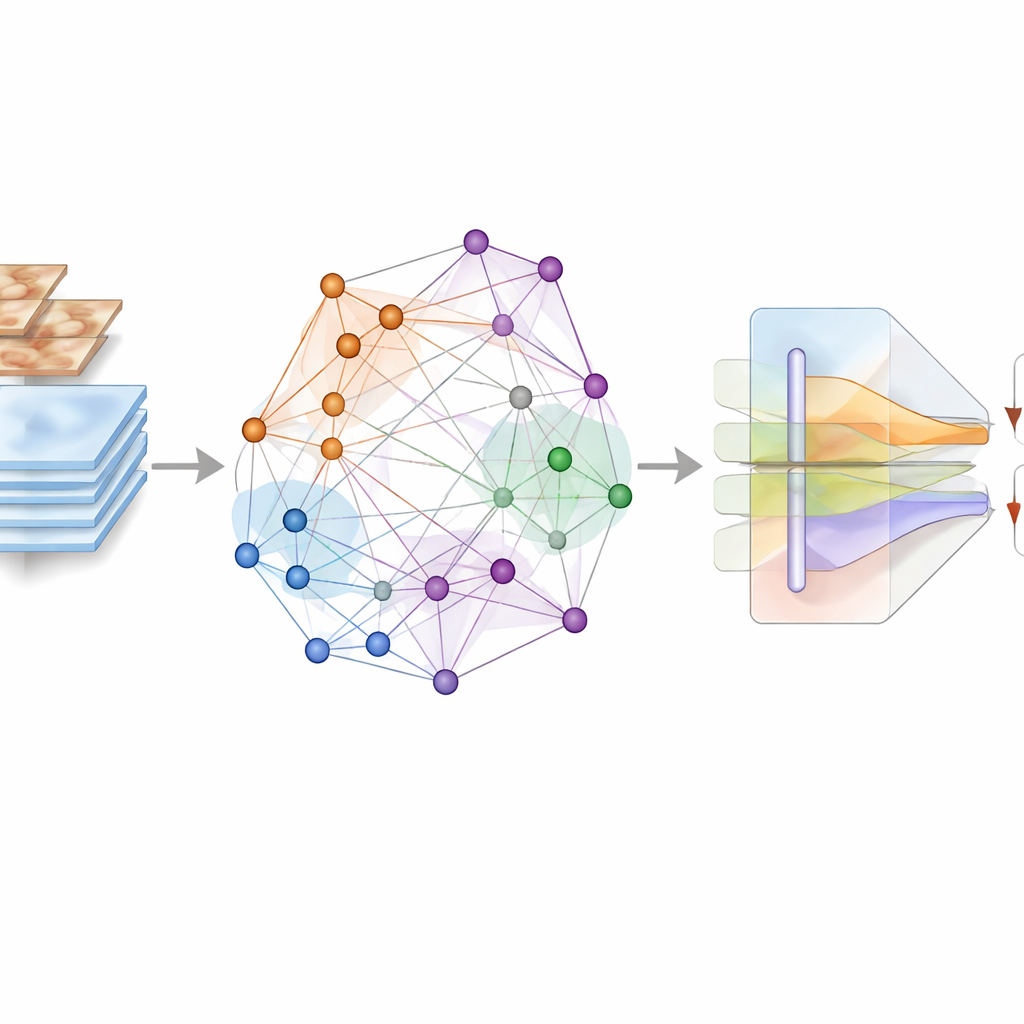
Lasciare che il significato guidi l’attenzione
Il secondo ingrediente principale è un modulo di fusione basato sull’attention che combina ciò che il grafo ha appreso con i dettagli visivi grezzi delle immagini. Le rappresentazioni derivate dal grafo, che codificano come ogni lesione si rapporta alle altre nel dataset, funzionano come una «domanda» di alto livello sull’identità della classe. Le feature a livello di pixel provenienti dalle immagini originali fungono da «prove». All’interno del blocco di attention multimodale, questi due flussi interagiscono: gli indizi semantici dal grafo orientano il modello a concentrare l’attenzione su regioni e pattern nell’immagine che contano maggiormente per distinguere lesioni difficili da separare. Connessioni residuali e processi multi‑scala aiutano a preservare dettagli fini, come lievi variazioni di pigmentazione, irregolarità del bordo o piccoli vasi sanguigni, che spesso separano una lesione pericolosa da una innocua.
Quanto bene si comporta il modello
I ricercatori hanno valutato il loro framework sul dataset HAM10000 usando protocolli sperimentali rigorosi, inclusa la validazione incrociata a cinque fold e ampi confronti con oltre 30 modelli popolari basati su convoluzioni e transformer. Il loro metodo ha raggiunto circa il 93% di accuratezza complessiva e un F1‑score simile, superando di gran lunga tutti i baseline. È importante notare che i miglioramenti sono stati più marcati per i tipi di lesione rari con cui la maggior parte dei sistemi fatica. Test aggiuntivi hanno mostrato che ogni componente — il clustering basato sulle classi, l’embedding contrastivo su ipergrafo e la fusione tramite attention — ha contribuito in modo misurabile alle prestazioni. Strumenti visuali come t‑SNE, UMAP e mappe di calore Grad‑CAM hanno rivelato che il nuovo metodo produce cluster di tipi di lesione più chiari e focalizza l’attenzione su regioni dell’immagine di rilevanza medica, come bordi irregolari nel melanoma o aree di cheratina densa in alcune lesioni precancerose.
Cosa significa per i controlli cutanei futuri
In termini semplici, questo studio presenta un framework di IA che è allo stesso tempo più equo e più discriminante nell’esaminare lesioni cutanee. Bilanciando esplicitamente casi comuni e rari, mappando le relazioni tra le immagini e lasciando che tali relazioni guidino dove il modello «guarda» in ogni immagine, C2G‑HFMTA migliora sostanzialmente la diagnosi computerizzata del cancro della pelle. Sebbene il sistema debba ancora essere validato su raccolte cliniche più ampie e più diverse, indica la strada verso strumenti futuri che potrebbero aiutare i dermatologi — e persino app per lo screening domestico — a individuare tumori cutanei pericolosi prima e con maggiore fiducia, senza perdere di vista i casi rari che contano di più.
Citazione: Banerjee, T., Chhabra, P., Kumar, M. et al. Hypergraph-based contrastive embedding and attention fusion for detection of skin cancer. Sci Rep 16, 12808 (2026). https://doi.org/10.1038/s41598-026-43351-9
Parole chiave: rilevamento del cancro della pelle, dermoscopia IA, apprendimento contrastivo, squilibrio di classi, analisi di immagini mediche