Clear Sky Science · zh
一种与疾病无关的集成学习方法用于传染病预测
为何更好的疾病预测很重要
当一种新的传染病出现时,公共卫生官员必须在只有数周数据的情况下迅速就疫苗、医院容量和社会措施做出决策。数学和计算模型的预测指导着这些决策,但没有单一模型能在所有情形下都可靠。本文介绍了一种将多种不同预测方法组合成更智能预测的方法,即便在疾病新发、历史数据稀缺时也能发挥作用。
融合多种预测工具
科学家常通过构建集成来改进预测,即从若干单独模型得出的组合预测。一种简单的方法是赋予每个模型相等的影响力,这种做法安全但在某些模型明显优于其他模型时可能效率低下。更复杂的方法试图从过去的表现中学习哪些模型应被赋予更高权重,但它们通常需要多年针对单一疾病的详尽数据记录。这使得它们不适合像 COVID-19 这样快速发展的暴发情形,因为此类记录尚未建立。
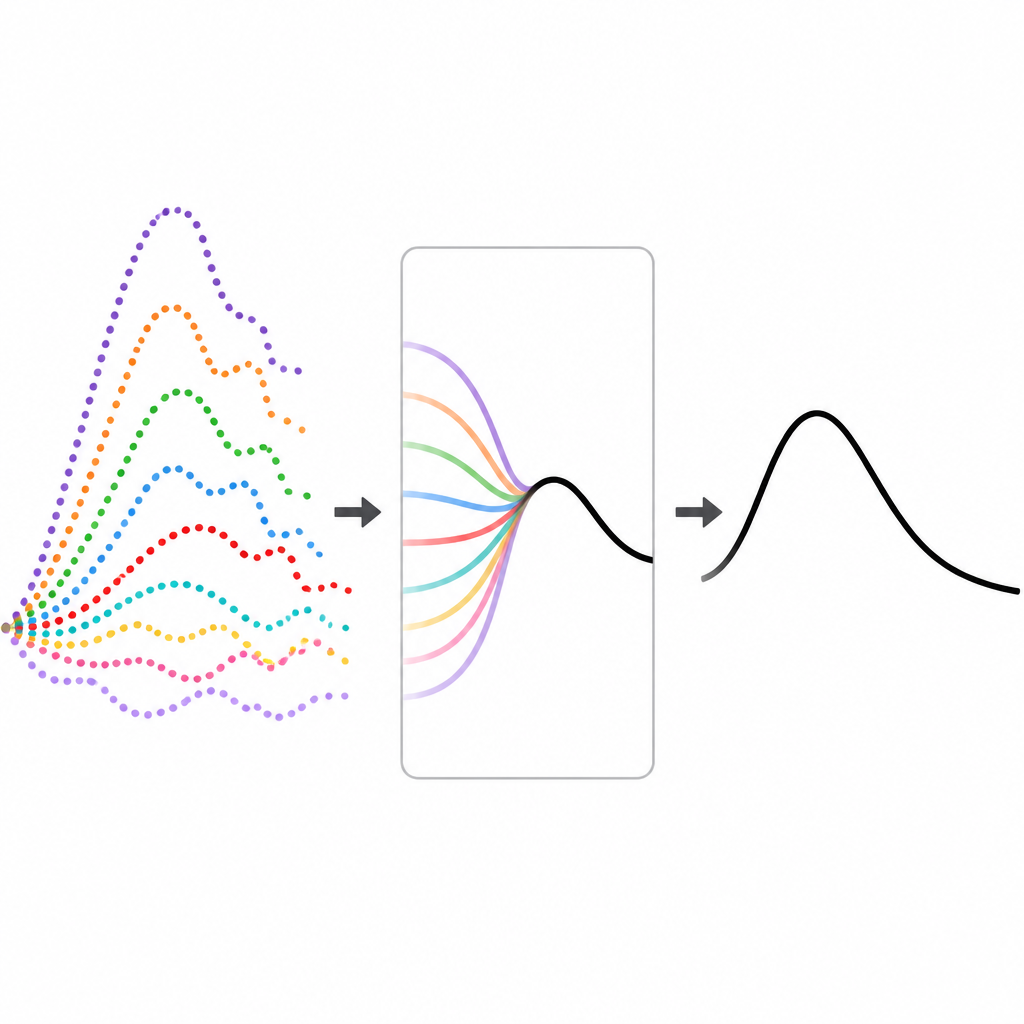
一种无需特定历史数据的调优方法
作者提出了一个名为 epiFFORMA 的新框架,它在不依赖特定疾病历史记录的情况下学习如何为模型加权。相反,他们使用标准的疾病传播方程生成大量现实但完全合成的暴发曲线库。对于每个合成暴发,他们运行九种常见的预测模型,并记录这些模型在轨迹不同阶段的表现。他们还将每条暴发曲线转换为一组简洁的描述性特征,例如病例变化速度、系列距离最近峰值的远近以及季节性模式的强弱等。
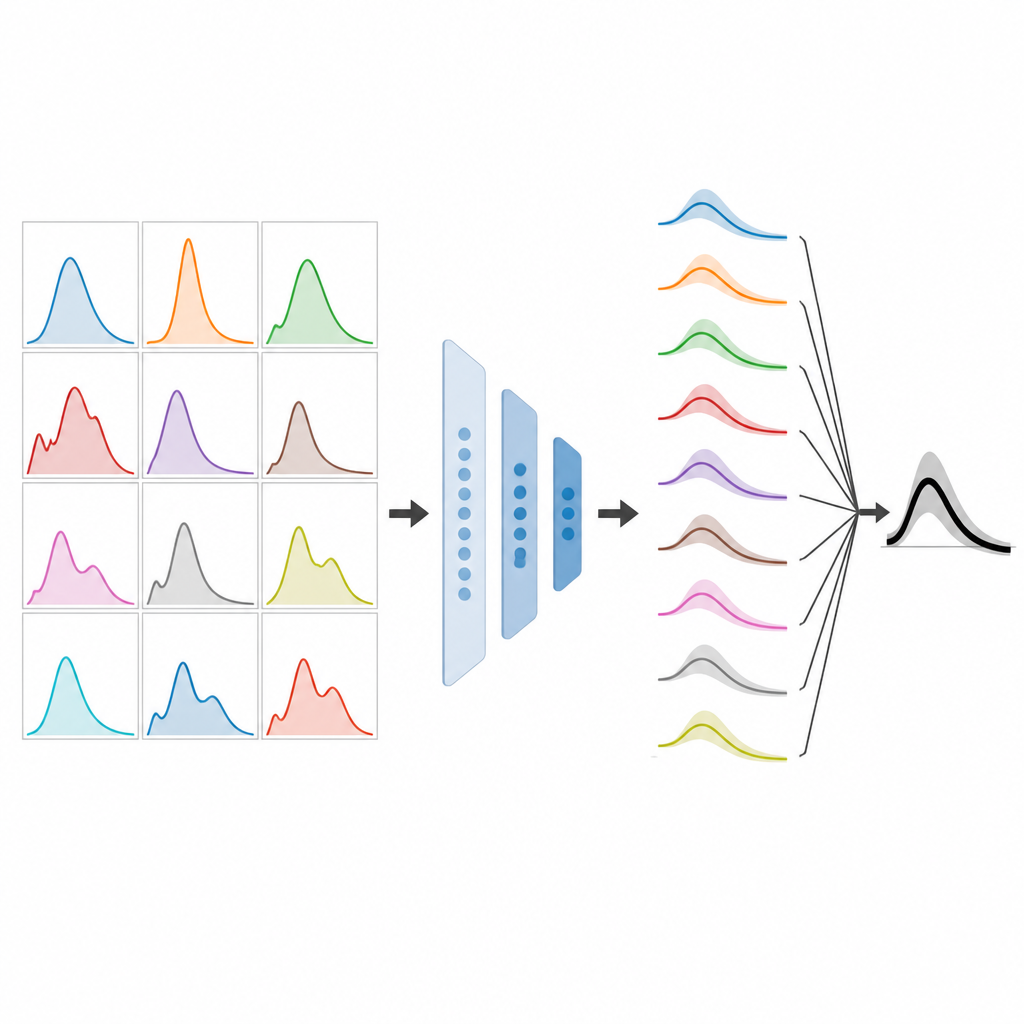
训练一个元模型来做选择
利用这个合成库,团队训练了一个单独的机器学习系统,将时间序列特征与合理的模型权重选择联系起来。epiFFORMA 并不是学习偏好特定命名模型,而是学习诸如何时信任接近所有模型预测中间值的预测、何时降低极端高或低预测的权重等模式。训练完成后,该元模型可应用于真实暴发:先从观测到的病例数计算特征,各组成模型生成短期预测,epiFFORMA 随后分配权重将它们融合为单一预测。
该方法的表现如何
研究人员在 11 个大型数据集上测试了 epiFFORMA,涵盖 COVID-19、类流感疾病、登革热、麻疹、腮腺炎、小儿麻痹、风疹、天花和基孔肯雅热等疾病,横跨多个地区和年份。他们比较了三种方案:各单一模型自身、简单的等权平均以及 epiFFORMA 的组合。在疾病预测常用的标准误差度量上,epiFFORMA 的平均准确性优于等权加权和大多数单一模型。它在病例数刚达到峰值之后或病例开始激增时尤其能提升预测精度,这些情形中一些模型通常会系统性地反应过度或不足。即便在少数 epiFFORMA 未能获得绝对最佳表现的疾病设置中,其表现也非常接近最佳方案。
这对未来暴发意味着什么
对非专家而言,主要信息是作者构建了一种能够通过模拟流行病预训练的暴发“预测合成器”,以便在下一次真实威胁出现时即可投入使用。因为 epiFFORMA 不需要针对特定病原体的详尽既往数据,它可以在新兴流行病早期部署,并仍比简单地对现有模型取平均值更有优势。这一方法为卫生机构提供了一种更灵活、总体可靠的预测工具,能够适应多种疾病,同时保留传统集成预测的稳定性与安全性。
引用: Murph, A.C., Beesley, L.J., Gibson, G.C. et al. A disease-agnostic approach to ensemble learning for infectious disease forecasting. Nat Commun 17, 4255 (2026). https://doi.org/10.1038/s41467-026-70937-8
关键词: 传染病预测, 集成建模, 合成暴发数据, 新兴流行病, 机器学习