Clear Sky Science · nl
Een ziekte-onafhankelijke aanpak voor ensembleleren bij de voorspelling van infectieziekten
Waarom betere ziektevoorspellingen ertoe doen
Wanneer een nieuwe besmettelijke ziekte opduikt, moeten volksgezondheidsfunctionarissen snel beslissingen nemen over vaccins, ziekenhuiscapaciteit en maatschappelijke maatregelen op basis van slechts enkele weken aan gegevens. Voorspellingen van wiskundige en computermodellen sturen die beslissingen, maar geen enkel model is in alle situaties betrouwbaar. Dit artikel introduceert een manier om veel verschillende voorspellingsbenaderingen te combineren tot één slimmer prognosemodel dat ook kan werken wanneer een ziekte nieuw is en historische gegevens schaars zijn.
Het mengen van veel voorspellingsinstrumenten
Wetenschappers verbeteren voorspellingen vaak door een ensemble te vormen, een gecombineerde voorspelling uit meerdere individuele modellen. Een eenvoudige methode geeft elk model gelijke invloed, wat veilig is maar inefficiënt kan zijn wanneer sommige modellen duidelijk beter presteren dan andere. Meer verfijnde methoden proberen te leren welke modellen meer gewicht verdienen op basis van vroegere prestaties, maar die vereisen doorgaans jaren aan gedetailleerde gegevens voor één enkele ziekte. Daardoor zijn ze slecht geschikt voor snel bewegende uitbraken zoals COVID-19, waar dergelijke dossiers nog niet bestaan.
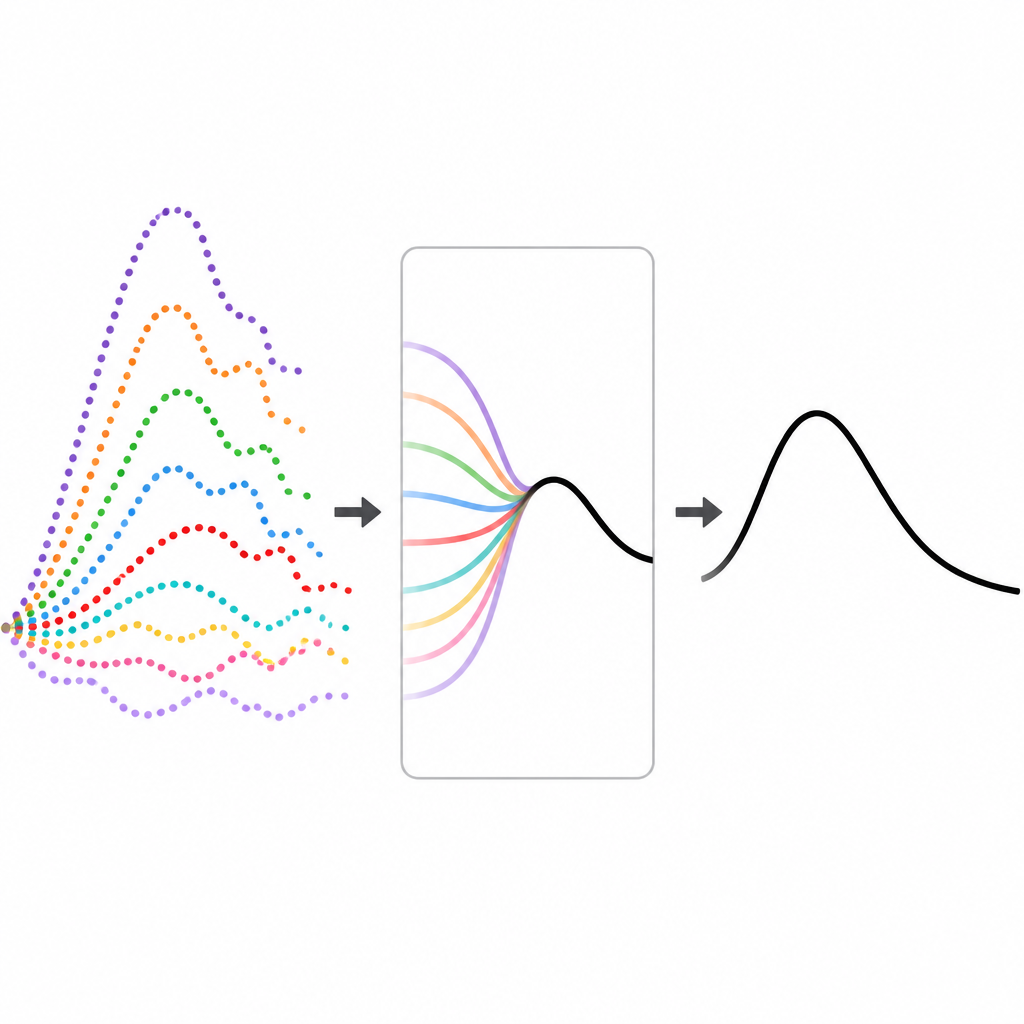
Een data-vrije manier om de mix af te stemmen
De auteurs stellen een nieuw raamwerk voor, epiFFORMA, dat leert hoe modellen te wegen zonder te vertrouwen op historische gegevens voor een specifieke ziekte. In plaats daarvan genereren ze een grote bibliotheek van realistische maar volledig synthetische uitbraakkrommen met behulp van standaardvergelijkingen voor ziekteverspreiding. Voor elke synthetische uitbraak voeren ze negen veelgebruikte voorspellingsmodellen uit en noteren welke modellen op verschillende punten in de trajectorie het beste presteren. Ze vertalen elke uitbraakkromme ook naar een compacte set beschrijvende kenmerken, zoals hoe snel het aantal gevallen verandert, hoe dicht de reeks bij een recente piek ligt en hoe sterk seizoenspatronen aanwezig zijn.
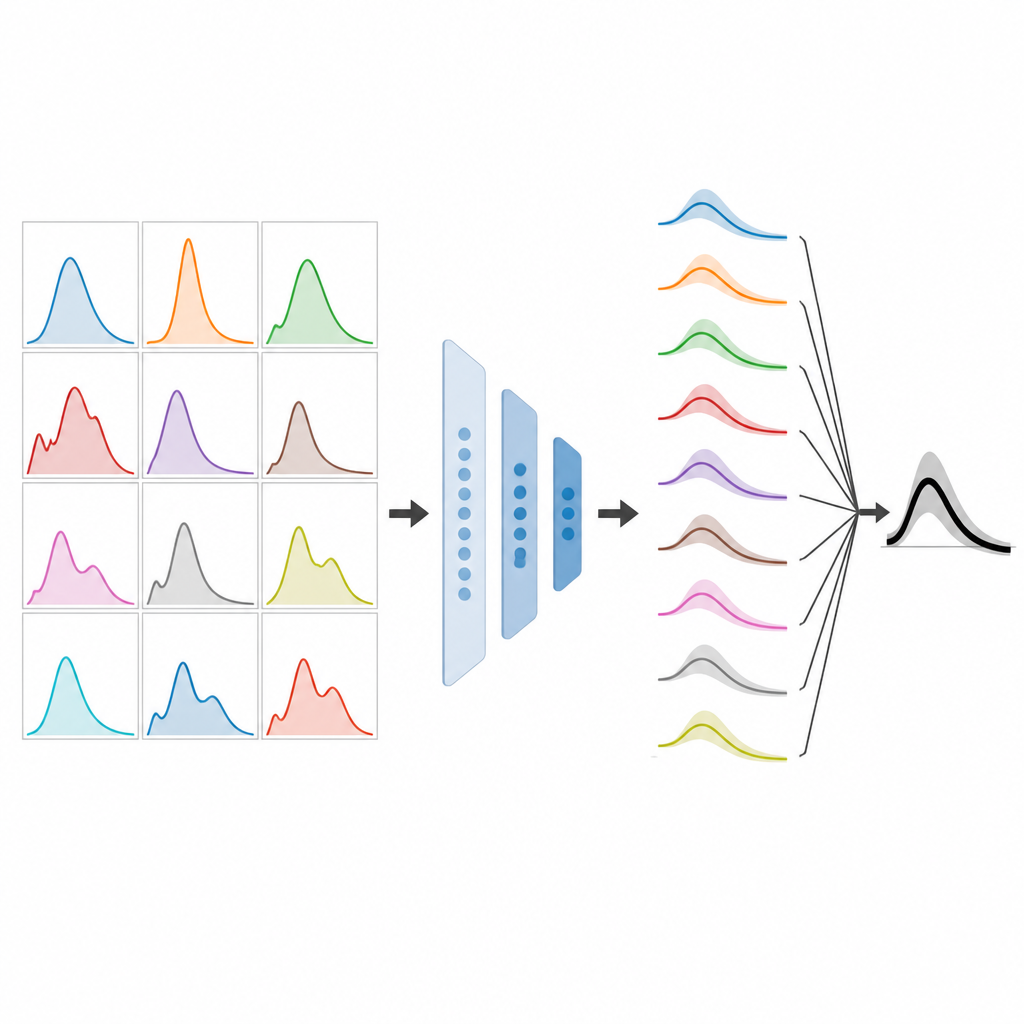
Een meta-model leren kiezen
Met deze synthetische bibliotheek traint het team een apart machine-learningsysteem om tijdreekskenmerken te koppelen aan goede keuzes voor modelgewichten. In plaats van te leren specifieke benoemde modellen te prefereren, leert epiFFORMA patronen zoals wanneer het vertrouwen gegeven moet worden aan voorspellingen die dicht bij het midden van alle modelvoorspellingen liggen of wanneer extreme hoge of lage voorspellingen afgeremd moeten worden. Eenmaal getraind kan dit meta-model op een echte uitbraak worden toegepast: kenmerken worden berekend uit de waargenomen casusreeks, elk componentmodel produceert een kortetermijnvoorspelling en epiFFORMA kent gewichten toe om ze samen te voegen tot één voorspelling.
Hoe goed de methode presteert
De onderzoekers testten epiFFORMA op 11 grote datasets die ziekten beslaan zoals COVID-19, influenza-achtige ziektebeelden, dengue, mazelen, bof, polio, rodehond, pokken en chikungunya, over vele regio’s en jaren. Ze vergeleken drie opties: elk individueel model afzonderlijk, een eenvoudige gemiddelde met gelijke gewichten, en de epiFFORMA-combinatie. Over standaard foutmaten die in ziektevoorspelling worden gebruikt, was epiFFORMA gemiddeld nauwkeuriger dan gelijke weging en dan de meeste individuele modellen. Het verbeterde met name voorspellingen net nadat het aantal gevallen gepiekt had of wanneer het aantal gevallen begon te stijgen, situaties waarin sommige modellen systematisch te snel of te langzaam reageerden. Zelfs in de weinige ziektegevallen waar epiFFORMA niet de winnaar was, lag de prestatie zeer dicht bij het beste alternatief.
Wat dit betekent voor toekomstige uitbraken
Voor niet-experts is de belangrijkste boodschap dat de auteurs een manier hebben ontwikkeld om een uitbraak-"voorspellingscombinator" voor te trainen met gesimuleerde epidemieën zodat die klaarstaat wanneer de volgende echte dreiging verschijnt. Omdat epiFFORMA geen gedetailleerde historische data voor het specifieke pathogeen vereist, kan het vroeg in een opkomende epidemie worden ingezet en toch een voordeel bieden boven het eenvoudig middelen van bestaande modellen. Deze aanpak biedt gezondheidsinstanties een flexibeler en over het algemeen betrouwbaarder voorspellingsinstrument dat zich aan veel ziekten kan aanpassen en tegelijk de stabiliteit en veiligheid van traditionele ensemblevoorspellingen behoudt.
Bronvermelding: Murph, A.C., Beesley, L.J., Gibson, G.C. et al. A disease-agnostic approach to ensemble learning for infectious disease forecasting. Nat Commun 17, 4255 (2026). https://doi.org/10.1038/s41467-026-70937-8
Trefwoorden: voorspelling van infectieziekten, ensemblemodellering, synthetische uitbraakdata, opkomende epidemieën, machine learning