Clear Sky Science · fr
Une approche indépendante de la maladie pour l’apprentissage par ensemble en prévision des maladies infectieuses
Pourquoi de meilleures prévisions de maladies sont importantes
Lorsqu’une nouvelle maladie infectieuse apparaît, les responsables de santé publique doivent prendre rapidement des décisions sur les vaccins, la capacité hospitalière et les mesures sociales en ne disposant que de quelques semaines de données. Les prévisions issues de modèles mathématiques et informatiques guident ces décisions, mais aucun modèle unique n’est fiable dans toutes les situations. Cet article présente une manière de combiner de nombreuses approches de prévision en une prévision plus intelligente capable de fonctionner même lorsqu’une maladie est nouvelle et que les données historiques sont rares.
Mélanger de nombreux outils de prévision
Les scientifiques améliorent souvent les prédictions en formant un ensemble, une prévision combinée à partir de plusieurs modèles individuels. Une méthode simple donne à chaque modèle la même influence, ce qui est sûr mais peut être inefficace lorsque certains modèles sont clairement meilleurs que d’autres. Des méthodes plus sophistiquées cherchent à apprendre quels modèles méritent plus de poids à partir des performances passées, mais elles requièrent généralement des années de données détaillées pour une même maladie. Cela les rend peu adaptées aux flambées rapides comme la COVID-19, où de tels historiques n’existent pas encore.
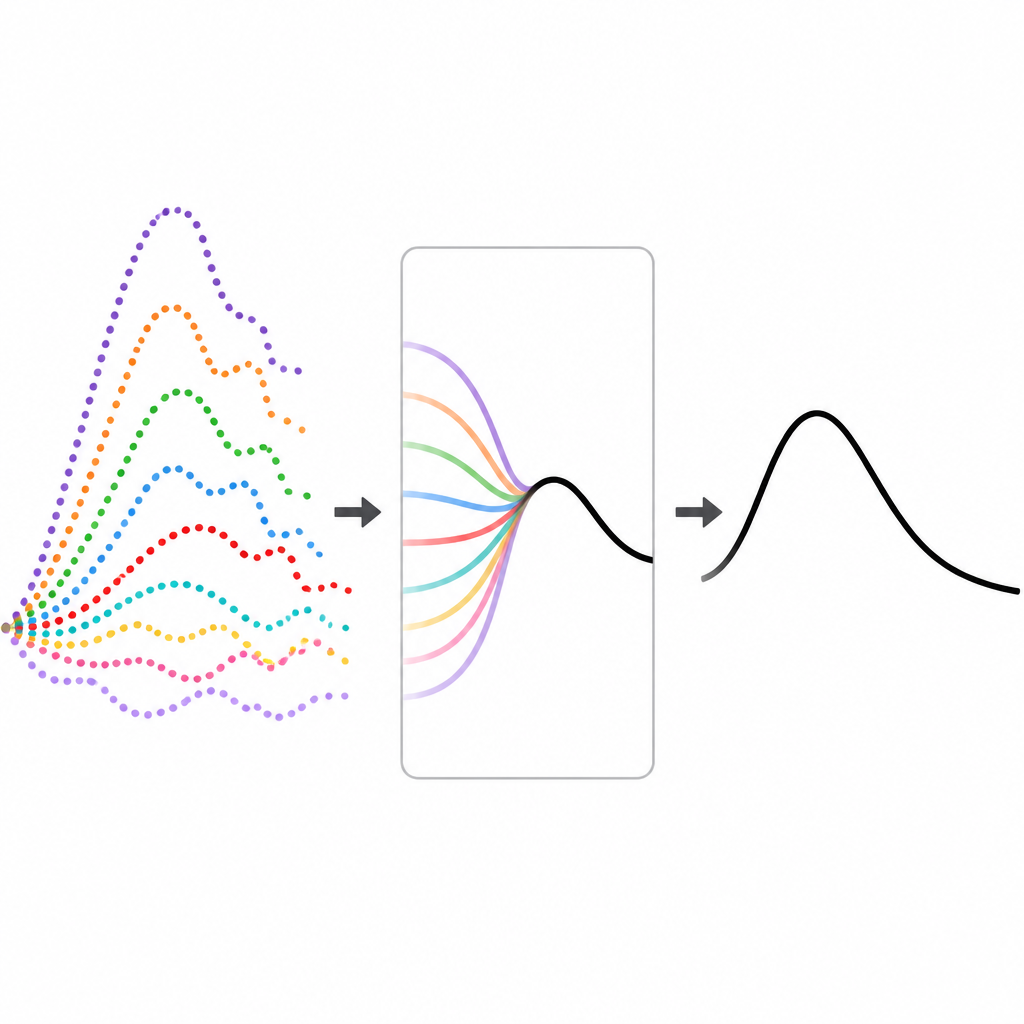
Un moyen sans données pour ajuster le mélange
Les auteurs proposent un nouveau cadre, appelé epiFFORMA, qui apprend à pondérer les modèles sans s’appuyer sur des archives historiques d’une maladie spécifique. À la place, ils génèrent une vaste bibliothèque de courbes d’épidémies réalistes mais entièrement synthétiques en utilisant des équations standard de propagation des maladies. Pour chaque épidémie synthétique, ils exécutent neuf modèles de prévision courants et enregistrent lesquels performent le mieux à différents moments de la trajectoire. Ils traduisent aussi chaque courbe d’épidémie en un jeu compact de caractéristiques descriptives, telles que la rapidité d’évolution des cas, la proximité d’un pic récent, et la force des schémas saisonniers.
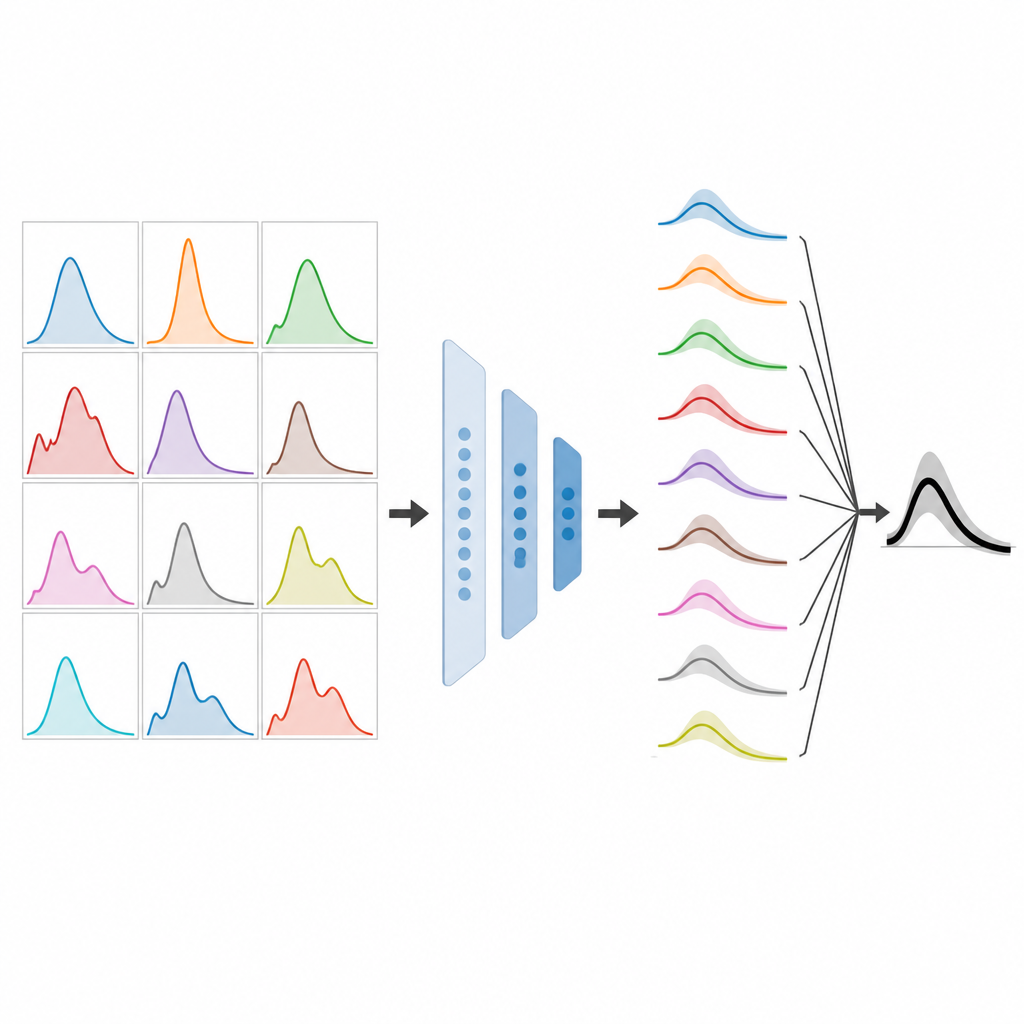
Apprendre à un méta-modèle à choisir
À l’aide de cette bibliothèque synthétique, l’équipe entraîne un système d’apprentissage automatique distinct pour relier les caractéristiques des séries temporelles aux bons choix de pondération des modèles. Plutôt que d’apprendre à favoriser des modèles nommés spécifiques, epiFFORMA apprend des schémas tels que quand faire confiance aux prévisions proches du centre des prédictions de tous les modèles ou quand sous-pondérer des prévisions extrêmes hautes ou basses. Une fois entraîné, ce méta-modèle peut être appliqué à une épidémie réelle : on calcule les caractéristiques à partir des comptes de cas observés, chaque modèle composant produit une prévision à court terme, et epiFFORMA attribue des poids pour les combiner en une seule prédiction.
Quelle est la performance de la méthode
Les chercheurs ont testé epiFFORMA sur 11 jeux de données importants couvrant des maladies comme la COVID-19, les syndromes grippaux, la dengue, la rougeole, les oreillons, la polio, la rubéole, la variole et le chikungunya, à travers de nombreuses régions et années. Ils ont comparé trois options : chaque modèle individuel seul, une moyenne simple à poids égaux, et la combinaison epiFFORMA. Selon les mesures d’erreur standard utilisées en prévision des maladies, epiFFORMA a été en moyenne plus précis que la pondération égale et que la plupart des modèles individuels. Il a particulièrement amélioré les prévisions juste après le pic des cas ou lorsque les cas commençaient à repartir à la hausse, des situations où certains modèles réagissaient systématiquement trop ou trop peu. Même dans les quelques contextes où epiFFORMA n’a pas été le meilleur, sa performance était très proche de la meilleure alternative.
Ce que cela signifie pour les futures épidémies
Pour un non-expert, le message principal est que les auteurs ont construit un moyen de préentraîner un « combineur » de prévisions d’épidémie en utilisant des épidémies simulées afin qu’il soit prêt lorsque la prochaine menace réelle apparaîtra. Parce qu’epiFFORMA ne nécessite pas de données passées détaillées pour le pathogène spécifique, il peut être déployé tôt dans une épidémie émergente et offrir malgré tout un avantage par rapport à la simple moyenne des modèles existants. Cette approche fournit aux agences de santé un outil de prévision plus flexible et généralement fiable, capable de s’adapter à de nombreuses maladies tout en conservant la stabilité et la sûreté des prévisions d’ensemble traditionnelles.
Citation: Murph, A.C., Beesley, L.J., Gibson, G.C. et al. A disease-agnostic approach to ensemble learning for infectious disease forecasting. Nat Commun 17, 4255 (2026). https://doi.org/10.1038/s41467-026-70937-8
Mots-clés: prévision des maladies infectieuses, modélisation en ensemble, données d’épidémies synthétiques, épidémies émergentes, apprentissage automatique