Clear Sky Science · sv
Förbättrad noggrannhet och tolkbarhet i filmratings med berättelseanpassad multimodal fusion
Varför smartare filmpoäng är viktiga
Stjärnbetyg på nätet påverkar vilka filmer vi ser, men de kan vara brusiga, partiska och svåra att tolka. Denna studie introducerar ett nytt sätt att förutsäga filmbetyg som inte bara förbättrar noggrannheten utan också förklarar vilka delar av en films berättelse och bakgrundsinformation som betyder mest. Genom att sammanföra sammanfattningar av handlingen med produktionsdetaljer och samtidigt spåra osäkerheten i betygen syftar tillvägagångssättet till att göra automatiska betyg mer tillförlitliga och transparenta för både tittare och forskare. 
Bortom enkla stjärnor
Många betygsverktyg behandlar en film som ett fåtal siffror, såsom genre, budget och genomsnittligt betyg. Andra läser handlingen men använder generella språkmodeller som inte är anpassade till berättelsestruktur. Dessa system bortser ofta från hur många som röstat, trots att ett betyg baserat på några få fans är mindre trovärdigt än ett som stöds av tiotusentals. Den nya modellen, kallad Narrative-Aligned Multimodal Rating Network (NAMRN), är utformad för att ta itu med alla tre problemen på en gång: den ägnar noggrann uppmärksamhet åt berättelsen, den tar hänsyn till hur osäkert varje betyg är, och den kombinerar olika typer av information selektivt istället för att blanda allt tillsammans utan distinktion.
Att lära en modell att förstå berättelser
En central idé i detta arbete är att anpassa skriftliga handlingstexter till viktiga filmattribut innan någon betygsprognos görs. Författarna använder ett träningssteg där modellen lär sig att para varje handling med dess metadata, såsom genre och tidsperiod, samtidigt som den skiljer ut felaktiga par. Denna kontrastiva uppställning uppmuntrar systemet att uppmärksamma teman, emotionell ton och stora händelser som konsekvent hör ihop med vissa typer av filmer. Resultatet är en kompakt representation av varje berättelse som fångar mer än bara nyckelord och senare kan fungera som en stabil grund för att uppskatta hur publiken kommer att reagera.
Hantera skakiga betyg och blandade signaler
Publikbetyg är inte lika tillförlitliga. En kultfilm med ett fåtal polariserade recensioner skiljer sig mycket från en storfilm med tiotusentals röster. NAMRN modellerar detta direkt genom att förutsäga inte bara ett films förväntade betyg utan också dess osäkerhet. Träningsprocessen bestraffar fel på ett sätt som beror på denna osäkerhet och på hur många röster en film har, så att säkra betyg väger tyngre än sköra. Samtidigt får modellen flera ingångskanaler: narrativ text, strukturerade detaljer som budget, speltid, genre och annan metadata. En gles styrmekanism lär sig hur starkt den ska förlita sig på varje kanal, dämpar försiktigt bort funktioner som tillför brus och framhäver de som verkligen hjälper. 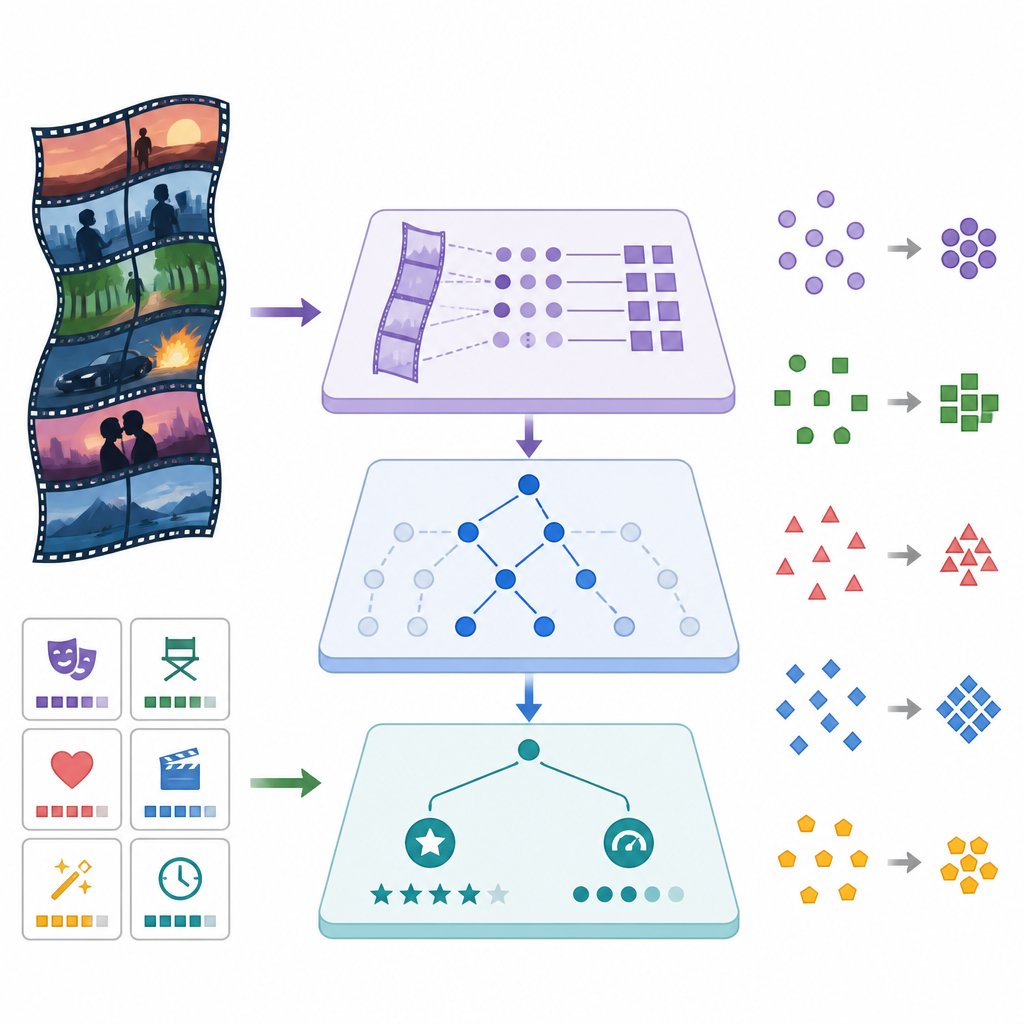
Testning över plattformar och med brusiga handlingar
Forskarlaget kombinerar tre offentliga datamängder: en stor filmkatalog med handlingar och metadata, betygsstatistik från en större filmsajt och en separat användar–film-betygsmatris. Efter noggrann rensning, anpassning och normalisering av betygsskalorna tränar och testar de NAMRN tillsammans med klassiska metoder såsom support vector regression och gradient boosting, liksom moderna neurala modeller baserade på LSTM, Transformers och attention. På alla centrala felmått uppnår NAMRN de bästa resultaten och visar mindre variation mellan körningar. Den bibehåller också liknande noggrannhet när den flyttas till den oberoende datamängden, vilket tyder på att den inte överanpassar sig till en enskild plattform. När författarna medvetet korruptar handlingstexten med borttagningar, substitutioner och stavfel sjunker prestandan som förväntat men förblir konkurrenskraftig, vilket visar rimlig robusthet mot röriga verklighetsbeskrivningar.
Se varför modellen beslutar som den gör
Utöver rå noggrannhet betonar studien tolkbarhet. Genom att spåra hur små förändringar i varje ingångstoken eller egenskap skulle ändra det förutsagda betyget skapar författarna värmekartor över ord och metadata. Dessa kartor visar att modellen fokuserar på emotionellt laddade termer i berättelsen och på produktionsattribut som budget och speltid på sätt som stämmer med mänsklig intuition, och att dess uppmärksamhetsmönster skiftar mellan lågt och högt betygsatta filmer. Samma verktyg visar också hur styrmekanismen flyttar viktningen mellan narrativa och strukturerade ingångar över filmer. Tillsammans ger dessa vyer ett ovanligt fönster in i hur en komplex modell översätter berättelseelement och bakgrundsdetaljer till ett enda förutsagt poäng.
Vad detta innebär för framtida filmtips
För en lekmannaläsare är slutsatsen att det nu är möjligt att bygga betygssystem som gör mer än att räkna ut medelvärden. Genom att lära sig rikare berättelserepresentationer, behandla vissa betyg som mer osäkra än andra och noggrant blanda flera datakällor erbjuder NAMRN filmbedömningar som både är mer precisa och lättare att lita på. Ramverket kan utvidgas för att betygsätta specifika aspekter av filmer, lägga till visuella eller audiella signaler eller stödja mer rättvisa rekommendationer, vilket ger en tydligare bild av varför vissa filmer hamnar högst upp på våra titta-listor.
Citering: Peng, D., Yue, K. & Zhou, Z. Improving movie rating prediction accuracy and interpretability with narrative-aligned multimodal fusion. Sci Rep 16, 14892 (2026). https://doi.org/10.1038/s41598-026-45472-7
Nyckelord: förutsägelse av filmbetyg, multimodal modell, berättelseanalys, osäkerhetsuppskattning, rekommendationssystem