Clear Sky Science · pl
Poprawa trafności i interpretowalności przewidywania ocen filmów dzięki multimodalnemu fuzowaniu zgodnemu z narracją
Dlaczego ważniejsze, inteligentniejsze oceny filmów mają znaczenie
Oceny w postaci gwiazdek w sieci wpływają na to, które filmy oglądamy, jednak bywają hałaśliwe, obarczone uprzedzeniami i trudne do zinterpretowania. W tym badaniu zaproponowano nowy sposób przewidywania ocen filmów, który nie tylko poprawia dokładność, lecz także wyjaśnia, które fragmenty opowieści i informacje kontekstowe są najważniejsze. Łącząc streszczenia fabuły ze szczegółami produkcyjnymi i śledząc niepewność ocen, podejście dąży do tego, by automatyczne oceny były bardziej wiarygodne i przejrzyste zarówno dla widzów, jak i badaczy. 
Patrząc dalej niż proste gwiazdki
Wiele narzędzi ocenia film za pomocą kilku liczb, takich jak gatunek, budżet czy średnia ocena. Inne czytają fabułę, ale używają ogólnych modeli językowych, które nie są dostrojone do struktury opowieści. Systemy te często ignorują też liczbę głosów — a przecież ocena oparta na kilku fanach jest mniej wiarygodna niż ta poparta tysiącami głosów. Nowy model, nazwany Narrative-Aligned Multimodal Rating Network (NAMRN), został zaprojektowany, by jednocześnie rozwiązać wszystkie trzy problemy: zwraca szczególną uwagę na narrację, uwzględnia niepewność każdej oceny oraz selektywnie łączy różne typy informacji zamiast bezkrytycznie mieszać wszystko razem.
Nauczanie modelu rozumienia opowieści
Główną ideą tej pracy jest dopasowanie pisemnych streszczeń fabuły do kluczowych atrybutów filmu przed przystąpieniem do przewidywania ocen. Autorzy stosują etap treningowy, w którym model uczy się parować każdą fabułę z jej metadanymi, takimi jak gatunek czy okres, jednocześnie odpychając niepasujące pary. Takie kontrastowe ustawienie zachęca system do dostrzegania motywów, tonu emocjonalnego i głównych wydarzeń, które konsekwentnie występują w pewnych rodzajach filmów. W efekcie powstaje zwięzła reprezentacja każdej historii, która wychwytuje więcej niż tylko słowa-klucze i może później posłużyć jako solidna podstawa do oceny, jak widzowie zareagują.
Radzenie sobie z chwiejnością ocen i mieszanymi sygnałami
Oceny widzów nie są jednakowo wiarygodne. Film kultowy z kilkoma spolaryzowanymi recenzjami bardzo różni się od hitu z dziesiątkami tysięcy głosów. NAMRN modeluje to bezpośrednio, przewidując nie tylko oczekiwaną ocenę filmu, lecz także jej niepewność. Proces treningowy karze błędy w sposób zależny od tej niepewności i od liczby głosów, tak aby pewne oceny ważyły więcej niż kruche. Jednocześnie model otrzymuje kilka kanałów wejściowych: tekst narracji, uporządkowane dane takie jak budżet, długość trwania, gatunek i inne metadane. Mechanizm rzadkiego bramkowania uczy się, jak silnie polegać na każdym z tych kanałów, łagodnie tłumiąc cechy wprowadzające szum i podkreślając te, które naprawdę pomagają. 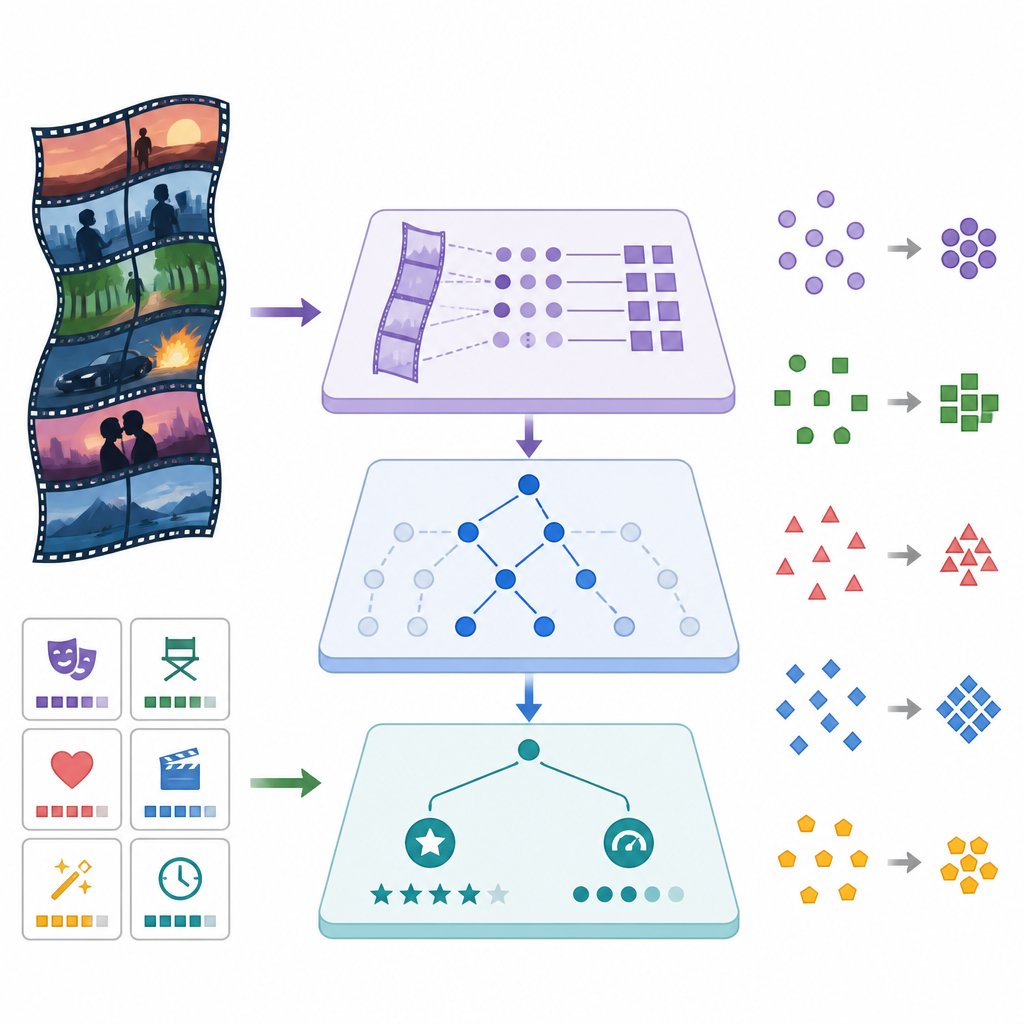
Testowanie na różnych platformach i przy zaszumionych fabułach
Naukowcy łączą trzy publiczne zbiory danych: duży katalog filmów ze streszczeniami i metadanymi, statystyki ocen z głównej witryny filmowej oraz osobną macierz ocen użytkownik–film. Po dokładnym oczyszczeniu, wyrównaniu i normalizacji skali ocen, trenują i testują NAMRN obok klasycznych metod, takich jak regresja wektorów nośnych i gradient boosting, a także współczesnych modeli neuronowych opartych na LSTM, Transformerach i mechanizmach uwagi. We wszystkich kluczowych miarach błędu NAMRN osiąga najlepsze wyniki i wykazuje mniejszą zmienność między uruchomieniami. Utrzymuje też podobną dokładność po przeniesieniu na niezależny zestaw danych, co sugeruje, że nie przeucza się do jednej platformy. Gdy autorzy celowo uszkadzają teksty fabuł przez usunięcia, zamiany i literówki, wydajność spada — jak można się spodziewać — ale pozostaje konkurencyjna, wykazując rozsądną odporność na nieporządne opisy z prawdziwego świata.
Widzimy, dlaczego model podejmuje decyzje
Ponad surową dokładność, badanie kładzie nacisk na interpretowalność. Śledząc, jak drobne zmiany każdego tokena lub cechy wejściowej zmieniałyby przewidywaną ocenę, autorzy generują mapy cieplne dla słów i metadanych. Te mapy pokazują, że model koncentruje się na emocjonalnie naładowanych terminach w opowieści oraz na cechach produkcyjnych, takich jak budżet i długość trwania, w sposób zgodny z intuicją ludzką, a jego wzorce uwagi zmieniają się między filmami o niskich i wysokich ocenach. Te same narzędzia pokazują też, jak mechanizm bramkowania przesuwa wagę między narracją a danymi strukturalnymi w zależności od filmu. Razem te widoki dają rzadkie okno w to, jak złożony model przekłada elementy fabuły i informacje kontekstowe na pojedynczą przewidywaną ocenę.
Co to oznacza dla przyszłych wyborów filmowych
Dla czytelnika niebędącego specjalistą wniosek jest taki, że dziś można zbudować systemy ocen, które robią więcej niż tylko liczyć średnie. Poprzez uczenie bogatszych reprezentacji opowieści, traktowanie niektórych ocen jako bardziej niepewnych niż innych oraz ostrożne łączenie wielu źródeł danych, NAMRN oferuje prognozy filmowe, które są zarówno dokładniejsze, jak i łatwiejsze do zaufania. Ramy te można rozszerzyć o ocenę konkretnych aspektów filmów, dodać wskazówki wizualne lub dźwiękowe albo wspierać sprawiedliwsze rekomendacje, dając jaśniejszy obraz, dlaczego niektóre filmy trafiają na szczyt naszych list do obejrzenia.
Cytowanie: Peng, D., Yue, K. & Zhou, Z. Improving movie rating prediction accuracy and interpretability with narrative-aligned multimodal fusion. Sci Rep 16, 14892 (2026). https://doi.org/10.1038/s41598-026-45472-7
Słowa kluczowe: predykcja ocen filmów, model multimodalny, analiza narracyjna, szacowanie niepewności, systemy rekomendacyjne