Clear Sky Science · sv
S2SWCLIP: semantiskt optimerade prompts med rum-våglet-synergi för nollskotts detektion av anomalier
Upptäcka små fel utan att dela känsliga data
Moderna fabriker och sjukhus förlitar sig i allt högre grad på kameror för att upptäcka defekter och sjukdomar, men att samla in och märka tillräckligt många felaktiga exempel är svårt — och inom medicin ofta begränsat av sekretessregler. Denna artikel presenterar S2SWCLIP, en teknik som kan upptäcka ovanliga mönster i bilder, såsom sprickor i metall eller misstänkta områden i skanningar, även när den aldrig tidigare sett exempel från just den produktionslinjen eller det sjukhuset. Den gör detta genom att kombinera smart användning av språk med ett sofistikerat sätt att tolka former och texturer i bilder.
Varför det är så svårt att hitta sällsynta problem
Anomaliupptäckt är uppgiften att avgöra om en bild, eller till och med en enskild pixel, är normal eller defekt. På produktionslinjer och inom medicinsk bildhantering är verkliga fel sällsynta och mycket varierande, så traditionella system tränas oftast främst på normala exempel och lär sig vad som “ser rätt” ut. Många framgångsrika metoder rekonstruerar bilder och flaggar skillnader, eller bygger en kompakt beskrivning av normal utseende och letar efter avvikare. Dessa angreppssätt fungerar bra när viss data från målmiljön finns tillgänglig. Men i sekretesskänsliga eller ständigt föränderliga miljöer kan det saknas möjlighet att träna om modeller för varje ny produkt eller kroppsdel. Nyligen utvecklade ”nollskotts”-metoder baserade på CLIP — en kraftfull modell som kopplar samman bilder och text — erbjuder ett sätt att upptäcka anomalier bara genom att beskriva dem i ord. Befintliga tillvägagångssätt förlitar sig dock ofta på vaga textprompter och grova bildfunktioner, vilket kan sudda ut gränsen mellan normala och onormala mönster.
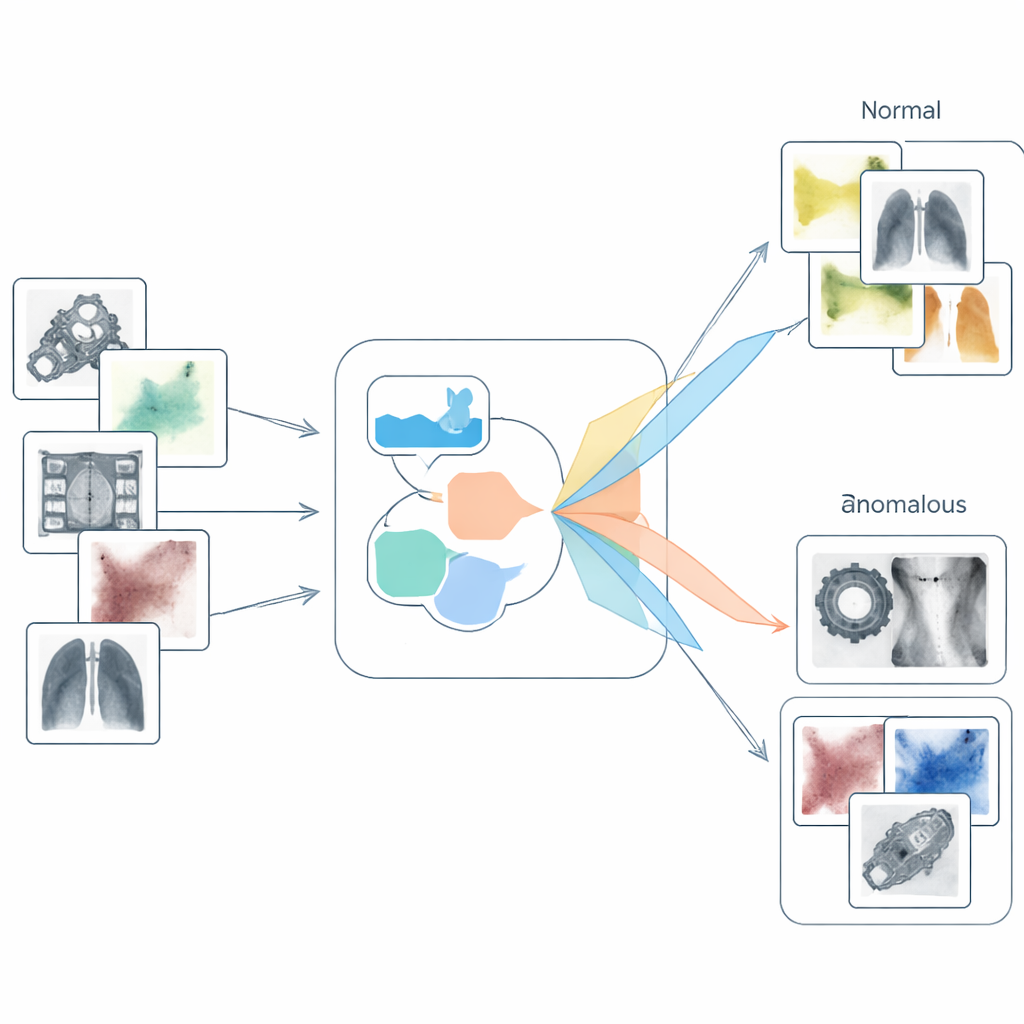
Skärpa språket för normalt och trasigt
S2SWCLIP tar först itu med språkdelen. Istället för att använda en enda generisk fras som “ett skadat objekt” bygger metoden tre familjer av prompts. Den ena är objekt-agnostisk och talar om ett namnlöst föremål som är normalt eller skadat. En andra kontrasterar tydligt positiva och negativa tillstånd med känsloladdade ord som “perfekt” kontra “svårt skadat”, tillsammans med ordset som antyder fläckfritt respektive felaktigt tillstånd. En tredje familj nämner specifika defekttyper — som sprickor eller repor — för att konkretisera idén om skada. Dessa olika fraser bearbetas i CLIPs textkomponent, och en särskild fusionsmekanism jämför och kombinerar deras interna signaler. Genom att filtrera bort brusiga komponenter och framhäva starkt korrelerade sådana, producerar systemet en rikare, bättre åtskild uppfattning av vad “normalt” och “anomalt” betyder innan någon bild överhuvudtaget beaktas.
Se både detaljerna och helheten i bilder
På den visuella sidan omarbetar S2SWCLIP hur CLIP ser på bilder. Standardversioner tenderar att favorisera breda, övergripande intryck, vilket kan missa tunna linjer i en spricka eller subtil skuggning som signalerar tidig sjukdom. För att åtgärda detta lägger författarna till en hierarkisk fusionsmodul som blandar information från olika upplösningar och bevarar både fina detaljer och stora strukturer. De tillämpar sedan en dubbel våglet-transform, ett klassiskt verktyg från signalbehandling som delar en bild i jämn bakgrundskomponenter och skarpare kanter eller texturer. Genom att använda två typer av våglet fångar metoden både milda globala variationer och abrupta lokala förändringar samtidigt, för att sedan återskapa dem till frekvensmedvetna funktionskartor. Denna ”rum-våglet-synergi” ger modellen en känsligare blick för små defekter som framträder i textur eller frekvens men som kan vara nästintill osynliga för blotta ögat.
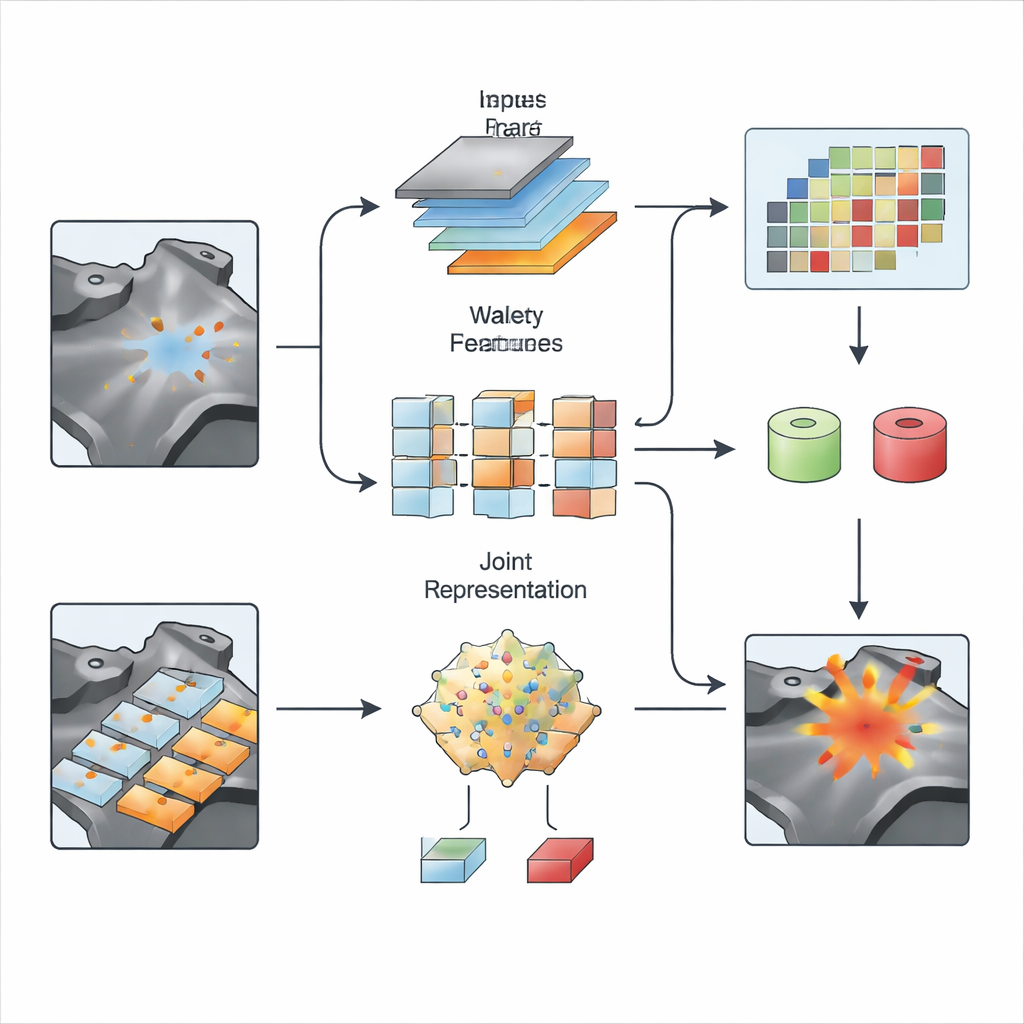
Justera vad vi säger med vad vi ser
Sista steget är att matcha dessa förbättrade bildfunktioner med de optimerade textprompterna. För hela bilder mäter S2SWCLIP hur väl varje promts representation linjerar med den globala bildbeskrivningen. För pixelvisa kartor introducerar den en entropibaserad likhetspoäng som undersöker hur mycket information varje lokalt område bär jämfört med textfunktionerna. Regioner vars statistik liknar anomali-prompterna men skiljer sig från normalprompterna markeras som misstänkta. Modellen finjusteras på ett enda industriellt riktmärke och testas sedan, utan omlärning, över 14 olika dataset som täcker tillverkade delar, texturer och medicinska bilder. I majoriteten av dessa tester överträffar S2SWCLIP tidigare nollskottsmetoder både vad gäller bildnivåklassificering och pixelnivålokalisering, samtidigt som beräkningstid och antalet träningsbara parametrar hålls måttliga.
Vad detta innebär för verklig inspektion
För en icke-specialist är kärnbudskapet att S2SWCLIP går bortom enkla ”är det trasigt?”-formuleringar och grov visning, och istället kombinerar nyanserat språk med ett mikroskopliknande fokus på bildstruktur. Genom att förstärka kontrasten mellan normala och felaktiga beskrivningar, och genom att dissekera bilder i flerskaliga, frekvensbaserade komponenter, flaggar metoden defekter mer pålitligt utan att behöva exempel från varje ny miljö. Även om den fortfarande kan ha svårt med extremt subtila anomalier som smälter in i komplexa bakgrunder, skisserar författarna framtida riktningar — såsom mer lokaliserad analys och avancerad geometri — som kan stänga denna lucka. Sammantaget erbjuder S2SWCLIP ett lovande steg mot flexibla, sekretessvänliga inspektionssystem som kan anpassas till nya industrier och medicinska sammanhang med minimal ytterligare data.
Citering: Zhang, H., Wu, C., Lu, J. et al. S2SWCLIP: semantic-optimized prompts with spatial-wavelet synergy for zero-shot anomaly detection. Sci Rep 16, 13062 (2026). https://doi.org/10.1038/s41598-026-43044-3
Nyckelord: nollskotts detektion av anomalier, vision-language-modeller, industriell inspektion, medicinsk bildanalys, vågletsbildfunktioner