Clear Sky Science · en
S2SWCLIP: semantic-optimized prompts with spatial-wavelet synergy for zero-shot anomaly detection
Spotting Tiny Flaws Without Sharing Sensitive Data
Modern factories and hospitals increasingly rely on cameras to catch defects and disease, but collecting and labeling enough flawed examples is difficult—and in medicine, often restricted by privacy rules. This paper introduces S2SWCLIP, a technique that can spot unusual patterns in images, such as cracks in metal or suspicious areas in scans, even when it has never seen examples from that specific factory line or hospital before. It does this by combining smart use of language with a sophisticated way of looking at the shapes and textures inside images.
Why Finding Rare Problems Is So Hard
Anomaly detection is the task of telling whether an image, or even a single pixel, is normal or defective. On production lines and in medical imaging, true defects are rare and highly varied, so traditional systems are trained mostly on normal samples and learn what “looks right.” Many successful methods either reconstruct images and flag differences, or build a compact description of normal appearance and look for outliers. These approaches work well when some data from the target setting is available. But in privacy-sensitive or constantly changing environments, there may be no chance to retrain models for each new product or body part. Recent “zero-shot” methods based on CLIP—a powerful model that connects pictures and text—offer a way to detect anomalies just by describing them in words. However, existing approaches often rely on vague text prompts and coarse image features, which can blur the line between normal and abnormal patterns.
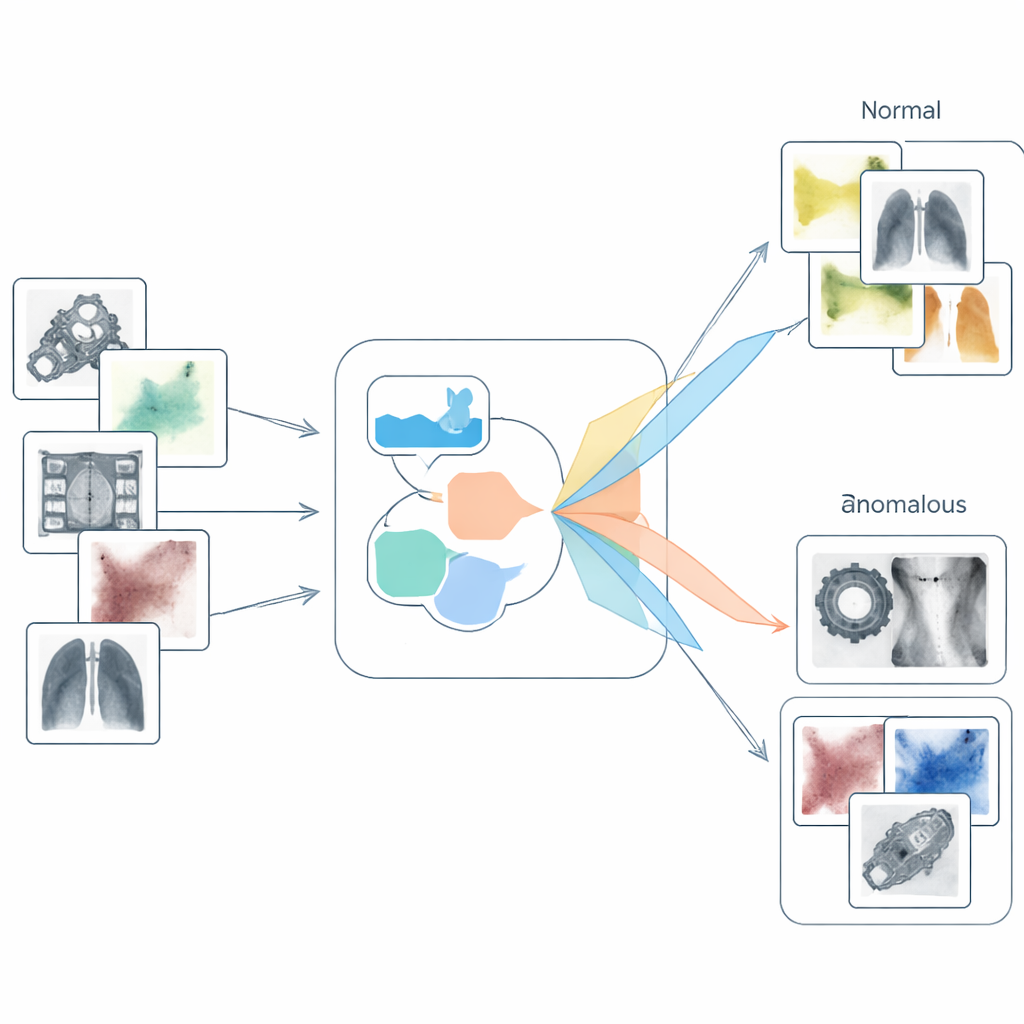
Sharpening the Language of Normal and Broken
S2SWCLIP tackles the language side first. Instead of using a single generic phrase like “a damaged object,” the method builds three families of prompts. One is object-agnostic, talking about an unnamed item being normal or damaged. A second contrasts clearly positive and negative states using emotionally charged words such as “perfectly” versus “severely,” along with sets of terms that imply flawless or faulty conditions. A third family mentions specific defect types—like cracks or scratches—to make the idea of damage more concrete. These different phrases are passed through the text part of CLIP, and a special fusion mechanism compares and combines their internal signals. By filtering out noisy components and emphasizing strongly correlated ones, the system produces a richer, better separated notion of what “normal” and “anomalous” mean before any image is even considered.
Seeing Both Details and the Big Picture in Images
On the visual side, S2SWCLIP reworks how CLIP looks at images. Standard versions tend to favor broad, overall impressions, which can miss the thin lines of a crack or the subtle shading that marks early disease. To address this, the authors add a hierarchical fusion module that mixes information from different resolutions, preserving both fine details and large structures. They then apply a dual wavelet transform, a classic tool from signal processing that splits an image into smooth background components and sharper edges or textures. Using two wavelet types, the method captures gentle global variations and abrupt local changes at once, and then recombines them into frequency-aware feature maps. This “space-wavelet synergy” gives the model a more sensitive view of tiny defects that stand out in texture or frequency but may be nearly invisible to the naked eye.
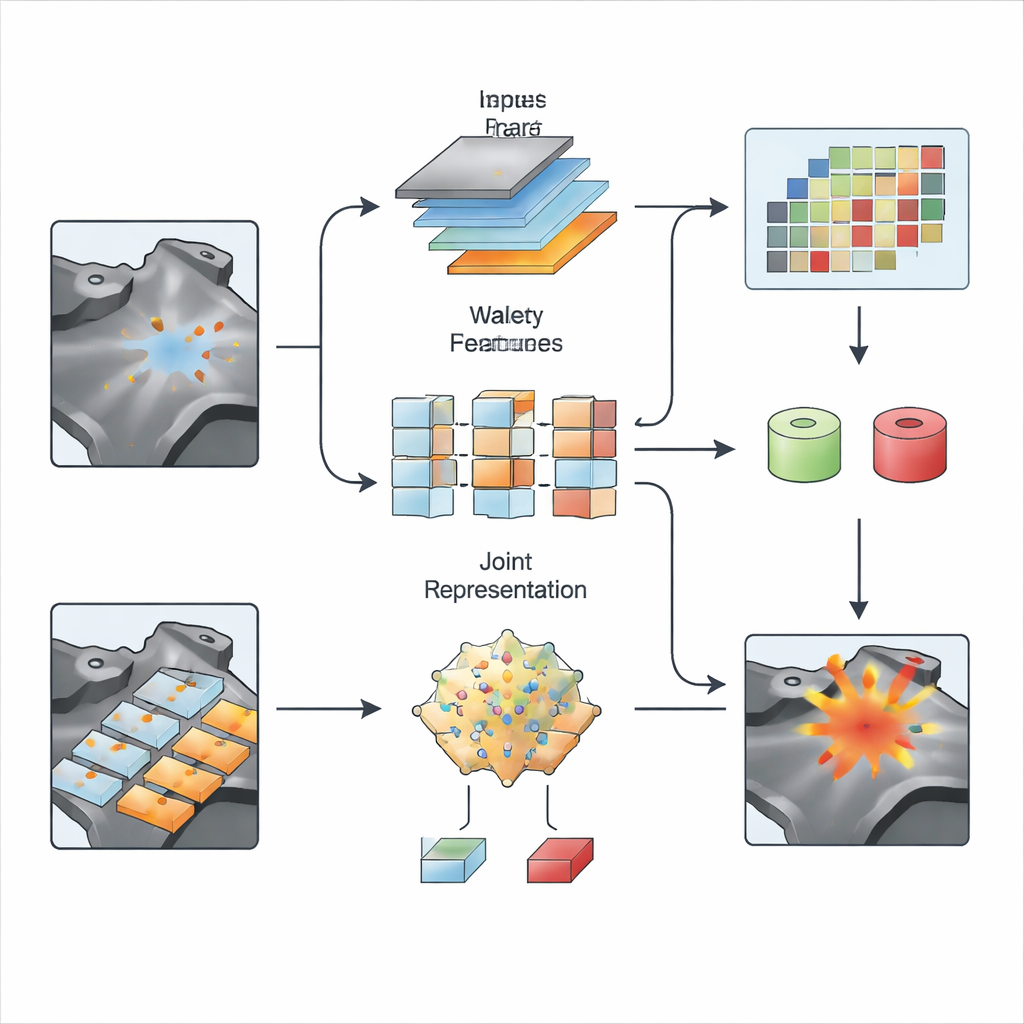
Aligning What We Say With What We See
The final step is to match these enhanced image features with the optimized text prompts. For whole images, S2SWCLIP measures how closely each prompt’s representation lines up with the global image description. For pixel-wise maps, it introduces an entropy-based similarity score that examines how much information is carried by each local region compared with the text features. Regions whose statistics closely resemble the anomaly prompts but differ from the normal prompts are highlighted as suspicious. The model is fine-tuned on a single industrial benchmark and then tested, without retraining, across 14 diverse datasets covering manufactured parts, textures, and medical imagery. Across most of these tests, S2SWCLIP outperforms earlier zero-shot methods in both image-level classification and pixel-level localization, while keeping computation time and the number of trainable parameters modest.
What This Means for Real-World Inspection
To a non-specialist, the core message is that S2SWCLIP moves beyond simple “is it broken?” wording and coarse viewing, instead combining nuanced language with a microscope-like look at image structure. By reinforcing the contrast between normal and faulty descriptions, and by dissecting images into multi-scale, frequency-based components, the method more reliably flags defects without needing examples from every new setting. Although it can still struggle with extremely subtle anomalies that blend into complex backgrounds, the authors outline future directions—such as more localized analysis and advanced geometry—that may close this gap. Overall, S2SWCLIP provides a promising step toward flexible, privacy-aware inspection systems that can adapt to new industries and medical contexts with minimal additional data.
Citation: Zhang, H., Wu, C., Lu, J. et al. S2SWCLIP: semantic-optimized prompts with spatial-wavelet synergy for zero-shot anomaly detection. Sci Rep 16, 13062 (2026). https://doi.org/10.1038/s41598-026-43044-3
Keywords: zero-shot anomaly detection, vision-language models, industrial inspection, medical image analysis, wavelet image features