Clear Sky Science · de
S2SWCLIP: semantisch-optimierte Prompts mit Raum-Wavelet-Synergie für Zero-Shot-Anomalieerkennung
Winzige Fehler erkennen, ohne sensible Daten zu teilen
Moderne Fabriken und Krankenhäuser verlassen sich zunehmend auf Kameras, um Defekte und Krankheiten zu erfassen. Es ist jedoch schwierig, genügend gefälschte Beispiele zu sammeln und zu annotieren — und in der Medizin ist das oft durch Datenschutzvorgaben eingeschränkt. Dieses Papier stellt S2SWCLIP vor, eine Technik, die ungewöhnliche Muster in Bildern erkennt, etwa Risse in Metall oder verdächtige Bereiche in Scans, selbst wenn sie zuvor nie Beispiele aus genau dieser Produktionslinie oder Klinik gesehen hat. Das erreicht sie durch die Kombination intelligenter Spracheingaben mit einer ausgefeilten Analyse von Formen und Texturen in Bildern.
Warum das Finden seltener Probleme so schwierig ist
Anomalieerkennung besteht darin zu entscheiden, ob ein Bild oder sogar ein einzelnes Pixel normal oder defekt ist. Auf Produktionslinien und in der medizinischen Bildgebung sind echte Fehler selten und sehr unterschiedlich, sodass traditionelle Systeme meist nur an normalen Beispielen trainiert werden und lernen, wie »richtig« aussieht. Viele erfolgreiche Methoden rekonstruieren Bilder und markieren Abweichungen oder bauen eine kompakte Beschreibung des normalen Aussehens und suchen nach Ausreißern. Diese Ansätze funktionieren gut, wenn einige Daten aus der Zielumgebung verfügbar sind. In datenschutzsensiblen oder sich ständig ändernden Umgebungen gibt es jedoch oft keine Möglichkeit, Modelle für jedes neue Produkt oder Körperareal nachzutrainieren. Neuere Zero-Shot-Methoden auf Basis von CLIP — einem leistungsfähigen Modell, das Bilder und Text verbindet — bieten einen Weg, Anomalien allein durch Beschreibungen in Worten zu erkennen. Bestehende Ansätze verwenden jedoch häufig vage Text-Prompts und grobe Bildmerkmale, was die Grenze zwischen normalen und abnormen Mustern verwischt.
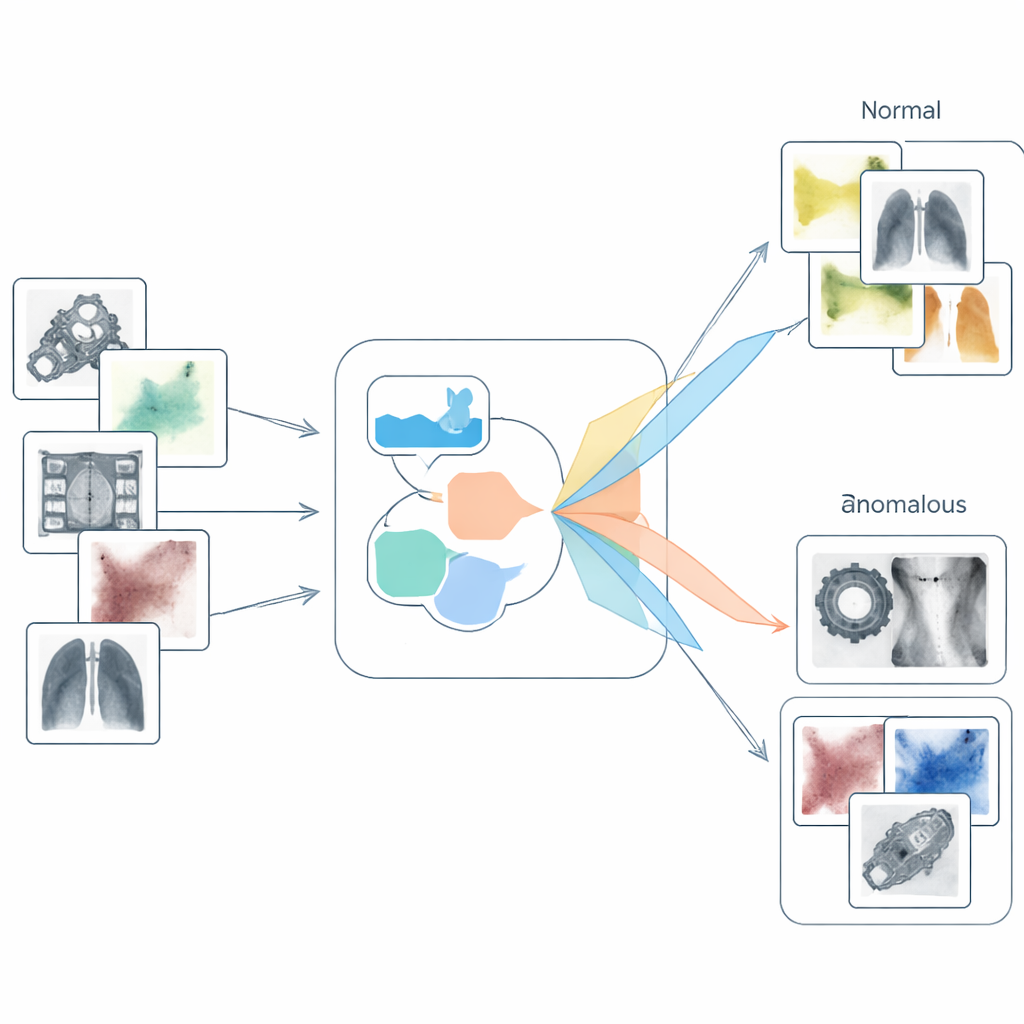
Die Sprache von Normal und Defekt schärfen
S2SWCLIP geht zunächst die sprachliche Seite an. Anstatt eine einzige generische Formulierung wie »ein beschädigtes Objekt« zu verwenden, erzeugt die Methode drei Prompt-Familien. Die erste ist objekt‑agnostisch und spricht allgemein von einem unbenannten Gegenstand, der normal oder beschädigt ist. Die zweite kontrastiert eindeutig positive und negative Zustände mit emotional aufgeladenen Worten wie »perfekt« versus »stark beschädigt« sowie mit Wortsätzen, die makellose oder fehlerhafte Zustände implizieren. Die dritte Familie nennt konkrete Defekttypen — etwa Risse oder Kratzer —, um den Begriff der Beschädigung zu konkretisieren. Diese unterschiedlichen Formulierungen werden durch den Textteil von CLIP geleitet, und ein spezieller Fusionsmechanismus vergleicht und kombiniert ihre internen Signale. Indem er rauschartige Komponenten herausfiltert und stark korrelierte betont, erzeugt das System eine reichere, besser getrennte Vorstellung davon, was »normal« und »anomal« bedeutet, noch bevor ein Bild betrachtet wird.
Sowohl Details als auch das große Ganze in Bildern sehen
Auf der visuellen Seite überarbeitet S2SWCLIP, wie CLIP Bilder betrachtet. Standardversionen tendieren dazu, breite Gesamteindrücke zu bevorzugen, wodurch dünne Risse oder subtile Schattierungen, die frühe Krankheit markieren, übersehen werden können. Um dem entgegenzuwirken, fügen die Autoren ein hierarchisches Fusionsmodul hinzu, das Informationen aus verschiedenen Auflösungen mischt und sowohl feine Details als auch große Strukturen erhält. Anschließend wenden sie eine doppelte Wavelet-Transformation an, ein klassisches Werkzeug der Signalverarbeitung, das ein Bild in glatte Hintergrundkomponenten sowie schärfere Kanten und Texturen aufteilt. Durch die Verwendung zweier Wavelet-Typen erfasst die Methode gleichzeitig sanfte globale Variationen und abrupte lokale Veränderungen und kombiniert sie dann zu frequenzbewussten Merkmalskarten. Diese »Raum‑Wavelet‑Synergie« verschafft dem Modell eine feinere Wahrnehmung winziger Defekte, die sich in Textur oder Frequenz abheben, aber mit bloßem Auge kaum sichtbar sind.
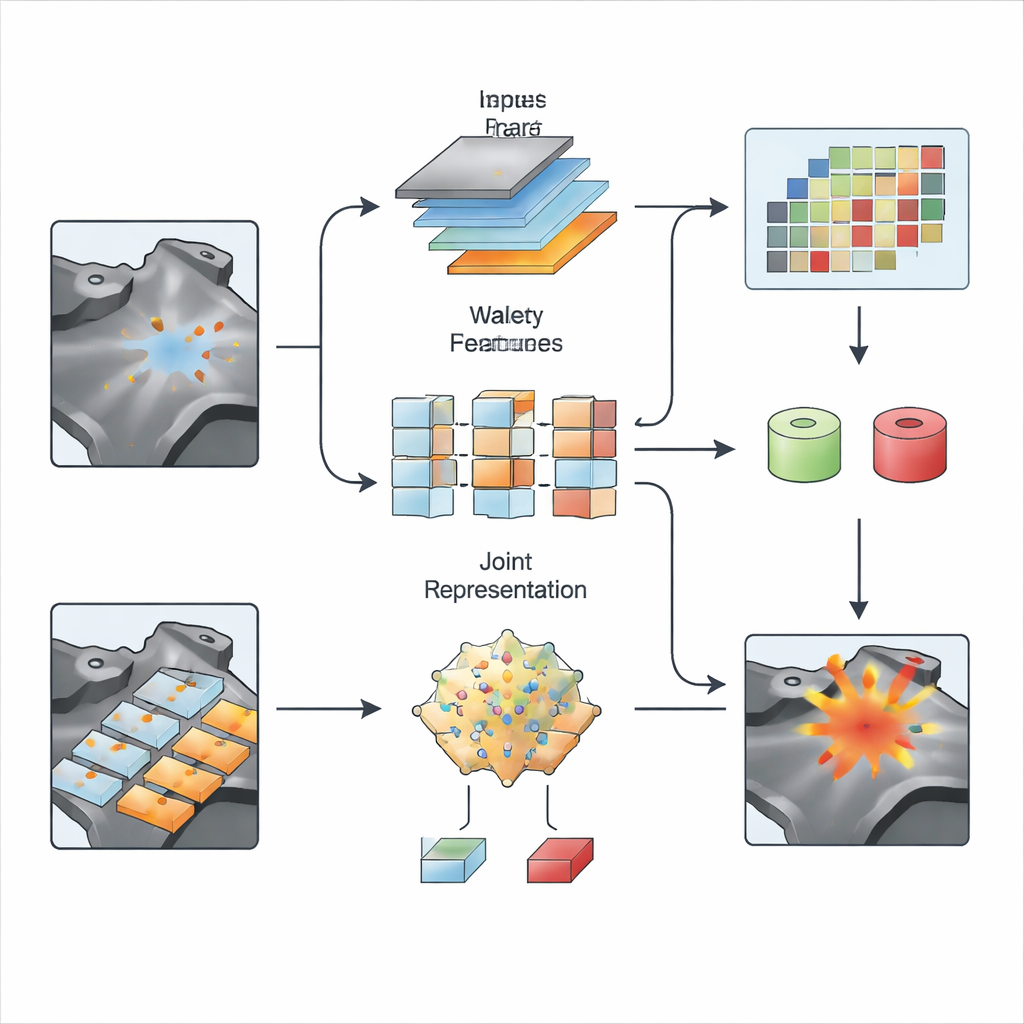
Was wir sagen mit dem was wir sehen abgleichen
Der letzte Schritt besteht darin, diese verbesserten Bildmerkmale mit den optimierten Textprompts abzugleichen. Für ganze Bilder misst S2SWCLIP, wie eng die Repräsentation jedes Prompts mit der globalen Bildbeschreibung übereinstimmt. Für pixelgenaue Karten führt es einen entropiebasierten Ähnlichkeitswert ein, der untersucht, wie viel Information jede lokale Region im Vergleich zu den Textmerkmalen trägt. Regionen, deren Statistiken den Anomalie-Prompts stark ähneln, sich aber von den Normal-Prompts unterscheiden, werden als verdächtig hervorgehoben. Das Modell wird an einem einzigen industriellen Benchmark feinabgestimmt und anschließend ohne Nachtrainieren über 14 verschiedene Datensätze getestet, die gefertigte Teile, Texturen und medizinische Bilddaten abdecken. In den meisten dieser Tests übertrifft S2SWCLIP frühere Zero-Shot-Methoden sowohl bei der Bildklassifikation auf Bildebene als auch bei der Lokalisierung auf Pixelebene, bei zugleich moderatem Rechenaufwand und einer überschaubaren Anzahl trainierbarer Parameter.
Was das für reale Inspektionen bedeutet
Für Nichtfachleute lautet die Kernbotschaft: S2SWCLIP geht über einfache Formulierungen wie »ist es kaputt?« und grobe Betrachtung hinaus, indem es nuancierte Sprache mit einem mikroskopähnlichen Blick auf die Bildstruktur kombiniert. Durch die Verstärkung des Kontrasts zwischen normalen und fehlerhaften Beschreibungen und durch die Zerlegung von Bildern in mehrskalige, frequenzbasierte Komponenten markiert die Methode zuverlässiger Defekte, ohne Beispiele aus jeder neuen Umgebung zu benötigen. Zwar hat sie weiterhin Probleme mit extrem subtilen Anomalien, die sich in komplexe Hintergründe einfügen, doch die Autoren skizzieren künftige Richtungen — etwa stärker lokalisierte Analysen und verbesserte Geometrieverarbeitung —, die diese Lücke schließen könnten. Insgesamt stellt S2SWCLIP einen vielversprechenden Schritt zu flexiblen, datenschutzfreundlichen Inspektionssystemen dar, die sich mit minimalen zusätzlichen Daten an neue Industrien und medizinische Kontexte anpassen lassen.
Zitation: Zhang, H., Wu, C., Lu, J. et al. S2SWCLIP: semantic-optimized prompts with spatial-wavelet synergy for zero-shot anomaly detection. Sci Rep 16, 13062 (2026). https://doi.org/10.1038/s41598-026-43044-3
Schlüsselwörter: Zero-Shot-Anomalieerkennung, Vision-Language-Modelle, industrielle Inspektion, medizinische Bildanalyse, Wavelet-Bildmerkmale