Clear Sky Science · sv
Identifiering av inflytelserika noder genom hierarkisk k-shell och utökad grannskapsintegration
Varför vissa förbindelser betyder mer än andra
Från sociala medier och flygrutter till elnät och sjukdomsutbrott är våra liv vävda in i stora nätverk av kopplingar. Men inom dessa nät spelar en liten andel punkter—människor, flygplatser, kraftstationer—en oproportionerligt viktig roll. Att hitta dessa ”gör-eller-ödes” punkter kan hjälpa till att förstärka användbar information, stoppa skadliga rykten, förhindra strömavbrott eller bromsa epidemier. Denna artikel presenterar ett nytt sätt, kallat HKEN, att identifiera de mest inflytelserika punkterna i sådana nätverk mer precist och effektivt än många befintliga tekniker.
Letar efter viktiga aktörer i invecklade nät
Forskare modellerar många verkliga system som nätverk: punkter (noder) förbundna med linjer (kanter) som representerar relationer eller interaktioner. En central fråga är vilka noder som spelar störst roll för att sprida något genom nätverket—vare sig det ”något” är nyheter, elektricitet eller ett virus. Tidigare metoder delar upp sig i två läger. Lokala metoder tittar bara på en nods omedelbara omgivning, vilket går snabbt men inte alltid kan skilja mellan noder som ser lika ut. Globala metoder skannar hela nätverksstrukturen, vilket ofta ger mer tillförlitliga rankningar men till hög beräkningskostnad och ibland mycket grova grupperingarna. Hybridmetoder försöker förena båda synsätten men kan bli komplicerade eller vara mycket beroende av justeringsparametrar. HKEN strävar efter att fånga det bästa från båda världar samtidigt som det förblir relativt enkelt och robust.
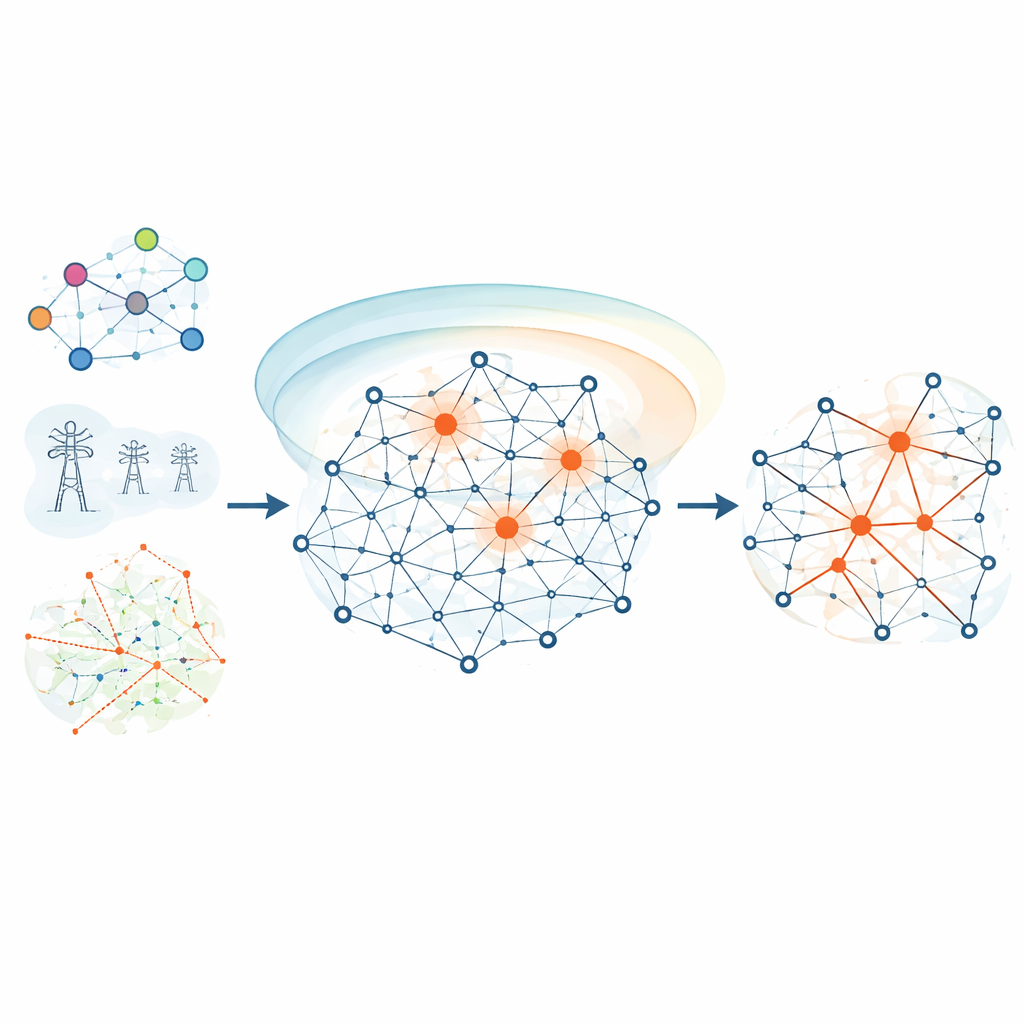
Att blanda närbild och vidvinkel
HKEN börjar med att ge varje nod en initial vikt som förenar två idéer. Först dess grad, antalet direkta kopplingar—en grundläggande indikation på lokal betydelse. För det andra dess position i det bredare nätverket, fångad av det författarna kallar ett k-shell-värde, vilket avslöjar hur djupt en nod är inbäddad i nätverkets kärna snarare än att ligga i periferin. Eftersom grader kan vara mycket större än k-shell-värden skalas de om i HKEN så att ingen av dem dominerar. Det ger en mer balanserad första uppskattning av hur potentiellt inflytelserik varje nod kan vara, baserad både på dess närmiljö och dess globala placering.
Lyssna på grannar nära och långt bort
Nästa steg tittar HKEN bortom varje nods omedelbara grannar till de som ligger två steg bort. Metoden använder spridningen av initiala vikter i nätverket för att sätta en tröskel som skiljer ”starka” och ”svaga” grannar i termer av hur lätt de kan överföra inflytande. Nära grannar och de med högre vikter tillåts bidra mer. Samtidigt mäter metoden hur tätt en grannes egen omgivning är klustrad. Om en grannes lokala cirkel är mycket tät kan information tendera att cirkulera lokalt snarare än att färdas utåt, så dess bidrag tonas ned. HKEN kontrollerar också hur lika två noders grannskap är—med en standard mått på överlappning—så att noder inbäddade i samma community stärker varandra mer.
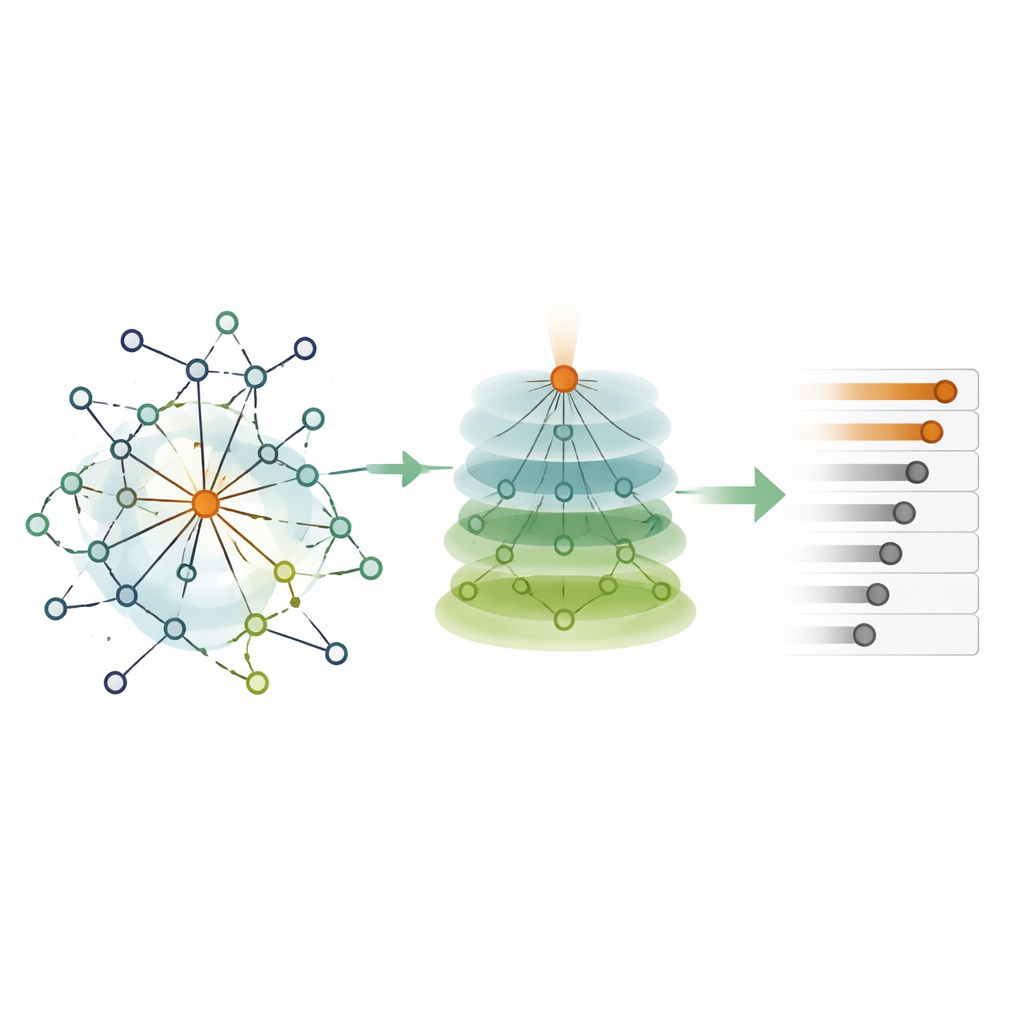
Från rått inflytande till slutlig rankning
Genom att sätta ihop dessa delar beräknar HKEN först ett ”initialt inflytande” för varje nod genom att addera dess egen vikt och de filtrerade, avståndsmedvetna bidragen från grannar upp till två steg bort. Sedan görs en andra genomgång som låter direkt kopplade grannar förstärka varandras poäng beroende på hur mycket av sin lokala omgivning de delar. Denna andra genomgång håller avsiktligt en nods eget bidrag framträdande så att starkt centrala noder inte överskuggas av sin omgivning. Slutresultatet är en slutlig inflytandepoäng för varje nod, som kan sorteras för att ge en rangordning av de mest kritiska punkterna i nätverket.
Test av metoden i verkliga nätverk
För att se hur väl HKEN fungerar testade författarna den på tio olika verkliga nätverk, från en klassisk karateklubbs sociala graf till flygrutter, proteininteraktioner och kartor över vetenskapligt samarbete. De jämförde HKEN med ett dussin välkända rankningsmetoder. Eftersom det är svårt att direkt veta vilka som är de ”verkligt” mest inflytelserika noderna använde de en standardmodell för spridning lånad från epidemiologi, kallad SIR, för att simulera hur en infektion skulle sprida sig genom varje nätverk med olika startnoder. De kontrollerade sedan hur väl varje algoritms rangordning stämde överens med infektionsmönstren. I de flesta datamängder och förhållanden överensstämde HKEN:s rangordningar starkare med den simulerade spridningen, och de toppnoder den valde utlöste bredare och snabbare kaskader än de som valdes av konkurrerande metoder, samtidigt som körtiderna förblev hanterbara för stora nätverk.
Vad detta betyder i verkligheten
Enkelt uttryckt visar detta arbete att uppmärksamhet både på var en nod ligger i det övergripande nätet och på hur dess omedelbara och sekundära grannar beter sig ger en skarpare bild av vem som verkligen driver inflytande. HKEN:s lager-på-lager-ansats—som balanserar lokala kopplingar, global position och den subtila överlappningen mellan grannskap—hjälper till att mer pålitligt identifiera kritiska noder än många befintliga verktyg. Det gör metoden lovande för uppgifter som att peka ut opinionsledare i sociala medier, identifiera sårbara knutpunkter i kraft- eller transportsystem eller rikta insatser för att bromsa sjukdomsspridning, samtidigt som den är tillräckligt effektiv för att köras på dagens stora, komplexa nätverk.
Citering: Wang, F., Sun, Z., Wang, G. et al. Identifying influential nodes through hierarchical k-shell and extended neighborhood integration. Sci Rep 16, 10215 (2026). https://doi.org/10.1038/s41598-026-40209-y
Nyckelord: inflytelserika noder, komplexa nätverk, informationsspridning, nätverkscentralitet, SIR-modell