Clear Sky Science · en
Identifying influential nodes through hierarchical k-shell and extended neighborhood integration
Why some connections matter more than others
From social media and airline routes to power grids and disease outbreaks, our lives are woven into vast webs of connections. Yet within these webs, a small fraction of points—people, airports, power stations—quietly play an outsized role. Finding these “make-or-break” points can help amplify useful information, block harmful rumors, prevent blackouts, or slow epidemics. This paper presents a new way, called HKEN, to pick out the most influential points in such networks more accurately and efficiently than many existing techniques.
Looking for key players in tangled webs
Researchers model many real systems as networks: dots (nodes) linked by lines (edges) that represent relationships or interactions. A central question is which nodes matter most for spreading something through the network—whether that “something” is news, electricity, or a virus. Earlier methods fall into two camps. Local methods look only at a node’s immediate surroundings, which is fast but can’t always tell similar-looking nodes apart. Global methods scan the whole network structure, often giving more reliable rankings but at high computational cost and sometimes with very rough groupings. Hybrid approaches try to mix both views but can become complicated or depend heavily on tuning parameters. HKEN aims to capture the best of both worlds while staying relatively simple and robust.
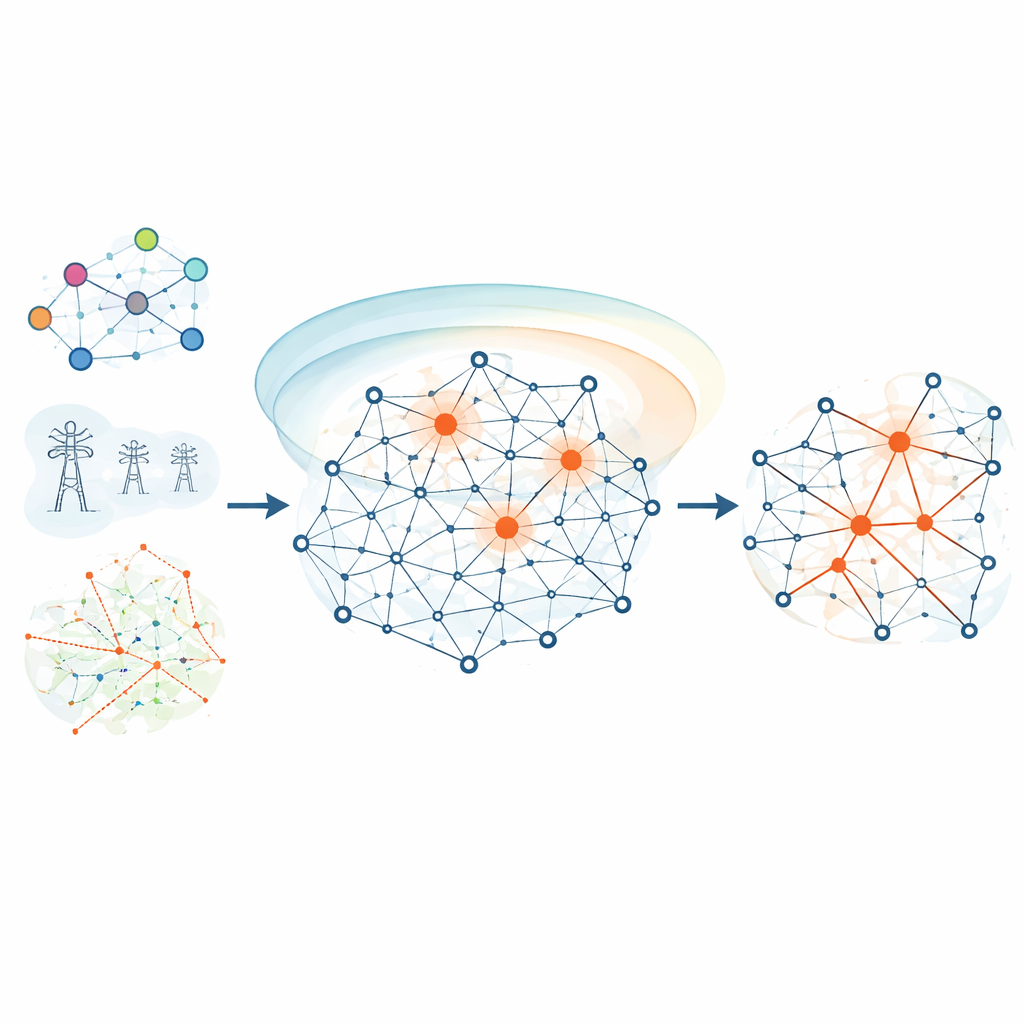
Blending close-up and wide-angle views
HKEN starts by giving each node an initial weight that blends two ideas. First is its degree, the number of direct connections it has—a basic sign of local importance. Second is its position in the broader network, captured by what the authors call a k-shell value, which reveals how deeply a node is embedded in the network’s core rather than sitting at the fringes. Because degrees can be much larger than k-shell values, HKEN rescales them so neither dominates. This produces a more balanced first guess of how potentially influential each node might be, based on both its neighborhood and its global placement.
Listening to neighbors near and far
Next, HKEN looks beyond each node’s immediate neighbors to those two steps away. It uses the spread of initial weights across the network to set a threshold that distinguishes “strong” and “weak” neighbors in terms of how easily they can transmit influence. Close-by neighbors and those with higher weights are allowed to contribute more. At the same time, the method measures how tightly clustered a neighbor’s own surroundings are. If a neighbor’s local circle is very dense, information may tend to circulate locally rather than travel outward, so its contribution is toned down. HKEN also checks how similar two nodes’ neighborhoods are—using a standard overlap measure—so that nodes embedded in the same community reinforce one another more strongly.
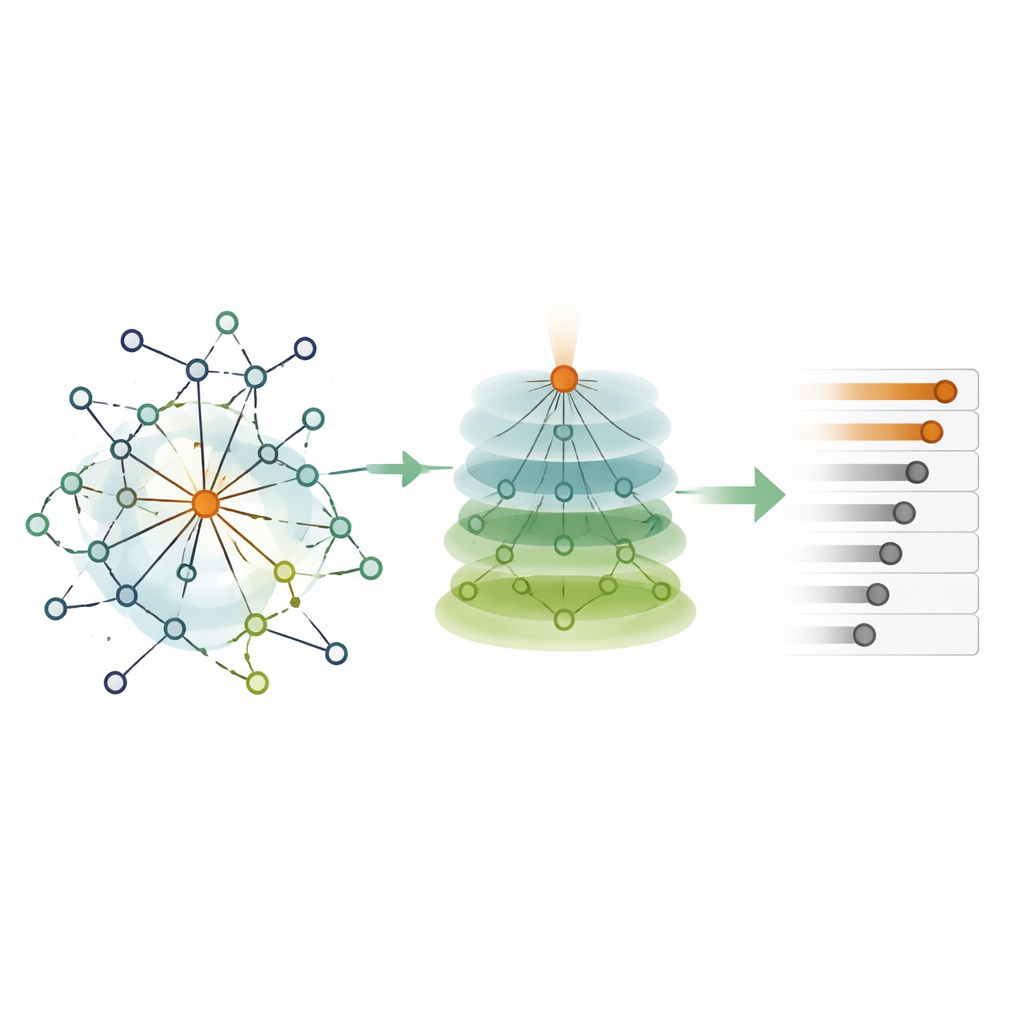
Turning raw influence into a final ranking
Putting these pieces together, HKEN first computes an “initial influence” for each node by adding up its own weight and the filtered, distance-aware contributions from neighbors up to two steps away. Then it performs a second pass that lets directly connected neighbors boost each other’s scores according to how much of their local environment they share. This second pass deliberately keeps a node’s own contribution prominent so that highly central nodes are not overshadowed by their surroundings. The end result is a final influence score for every node, which can be sorted to produce a ranking of the most critical points in the network.
Testing the method in real networks
To see how well HKEN works, the authors tested it on ten diverse real-world networks, ranging from a classic karate club social graph to airline routes, protein interactions, and scientific collaboration maps. They compared HKEN against a dozen well-known ranking methods. Because it is difficult to know the “true” most influential nodes directly, they used a standard spreading model borrowed from epidemiology, called SIR, to simulate how an infection would move through each network starting from different seed nodes. They then checked how closely each algorithm’s ranking matched the infection patterns. Across most datasets and conditions, HKEN’s rankings agreed more strongly with the simulated spread, and the top nodes it selected triggered broader and faster cascades than those chosen by competing methods, all while keeping running times manageable on large networks.
What this means for the real world
In simple terms, this work shows that paying attention both to where a node sits in the overall web and to how its immediate and second-ring neighbors behave leads to a sharper picture of who really drives influence. HKEN’s layered approach—balancing local connections, global position, and the subtle overlap between neighborhoods—helps pick out critical nodes more reliably than many existing tools. That makes it a promising aid for tasks such as pinpointing opinion leaders in social media, identifying vulnerable hubs in power or transport systems, or targeting interventions to slow the spread of disease, all while remaining efficient enough to run on today’s large, complex networks.
Citation: Wang, F., Sun, Z., Wang, G. et al. Identifying influential nodes through hierarchical k-shell and extended neighborhood integration. Sci Rep 16, 10215 (2026). https://doi.org/10.1038/s41598-026-40209-y
Keywords: influential nodes, complex networks, information spreading, network centrality, SIR model