Clear Sky Science · ru
Идентификация влиятельных узлов с помощью иерархической k-оболочки и интеграции расширённого окружения
Почему некоторые связи важнее других
От социальных сетей и авиамаршрутов до электросетей и вспышек болезней — наша жизнь переплетена в обширные сети связей. Тем не менее внутри этих сетей небольшая доля точек — люди, аэропорты, электростанции — непропорционально сильно влияет на работу системы. Нахождение таких «решающих» точек помогает усиливать полезную информацию, блокировать вредные слухи, предотвращать отключения или замедлять эпидемии. В этой работе предложен новый метод, называемый HKEN, который позволяет точнее и эффективнее выделять наиболее влиятельные точки в сетях по сравнению со многими существующими подходами.
В поисках ключевых игроков в запутанных сетях
Исследователи моделируют многие реальные системы как сети: точки (узлы), соединённые линиями (рёбрами), которые отражают отношения или взаимодействия. Центровой вопрос — какие узлы важнее всего для распространения чего-либо по сети — будь то новости, электричество или вирус. Ранние методы делятся на два лагеря. Локальные методы учитывают только ближайшее окружение узла — это быстро, но иногда не позволяет различать внешне похожие узлы. Глобальные методы анализируют всю структуру сети, часто давая более надёжные ранжирования, но с высокой вычислительной стоимостью и порой грубыми группировками. Гибридные подходы пытаются сочетать оба взгляда, но могут стать сложными или сильно зависеть от подбора параметров. HKEN стремится сохранить лучшее из обоих подходов, оставаясь при этом относительно простым и устойчивым.
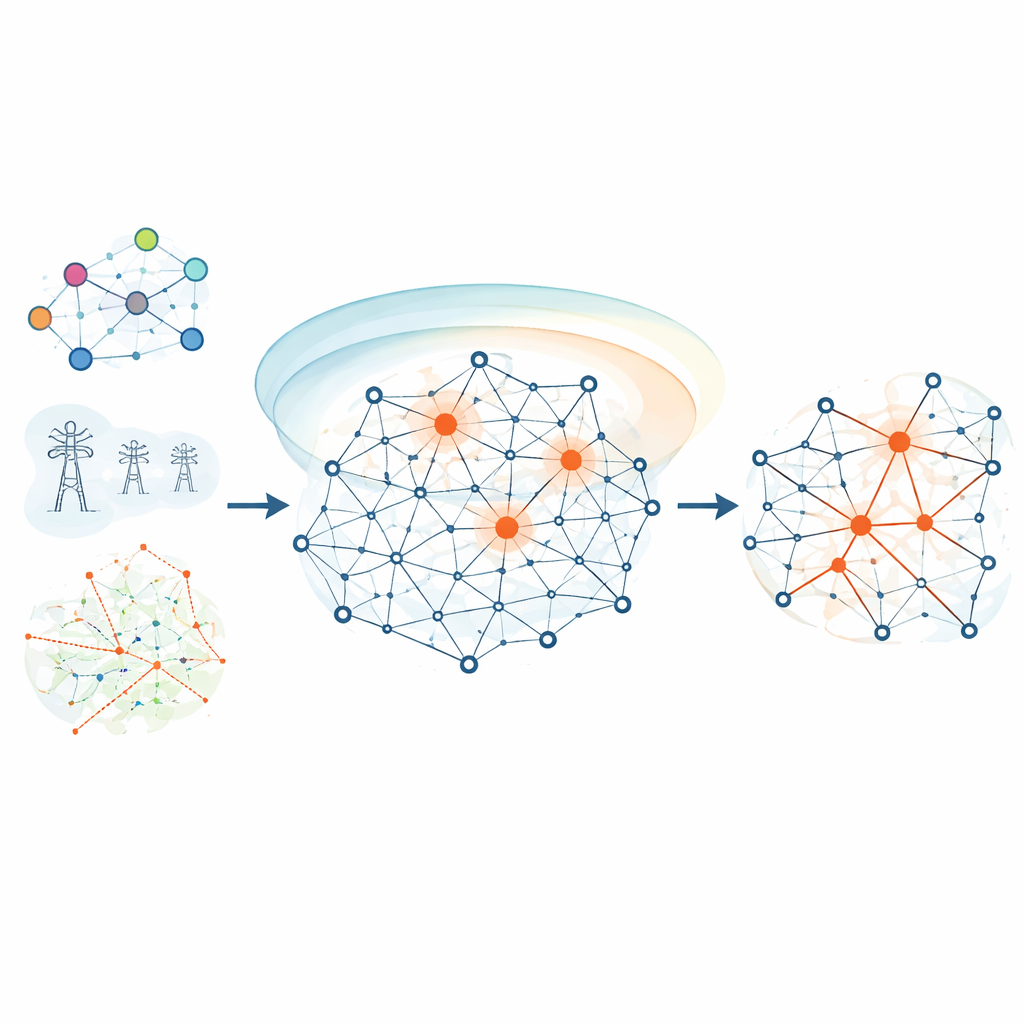
Смешение планов — крупный и широкий
HKEN начинается с присвоения каждому узлу начального веса, который сочетает две идеи. Первая — степень узла, число прямых связей, базовый показатель локальной важности. Вторая — положение в глобальной структуре сети, выраженное k-оболочкой, которая показывает, насколько глубоко узел погружён в ядро сети, а не находится на её периферии. Поскольку значения степеней могут быть значительно больше значений k-оболочки, HKEN масштабирует их так, чтобы ни одна из составляющих не доминировала. Это даёт более сбалансированную исходную оценку потенциальной влиятельности узла, учитывающую и его окрестность, и глобальное положение.
Услышать соседей близких и дальних
Далее HKEN смотрит дальше непосредственных соседей узла — на узлы, находящиеся на расстоянии двух шагов. Метод использует распределение начальных весов по сети, чтобы задать порог, разделяющий «сильных» и «слабых» соседей с точки зрения способности передавать влияние. Близкие соседи и те, у кого более высокие веса, вносят больший вклад. Вместе с тем метод оценивает, насколько плотно сконцентрировано окружение самого соседа: если локальный круг соседа очень плотный, информация скорее будет циркулировать локально, а не распространяться наружу, поэтому вклад такого соседа уменьшается. HKEN также проверяет схожесть соседских окружений двух узлов — с помощью стандартной меры перекрытия — так что узлы, погружённые в одну и ту же сообщественную структуру, сильнее усиливают друг друга.
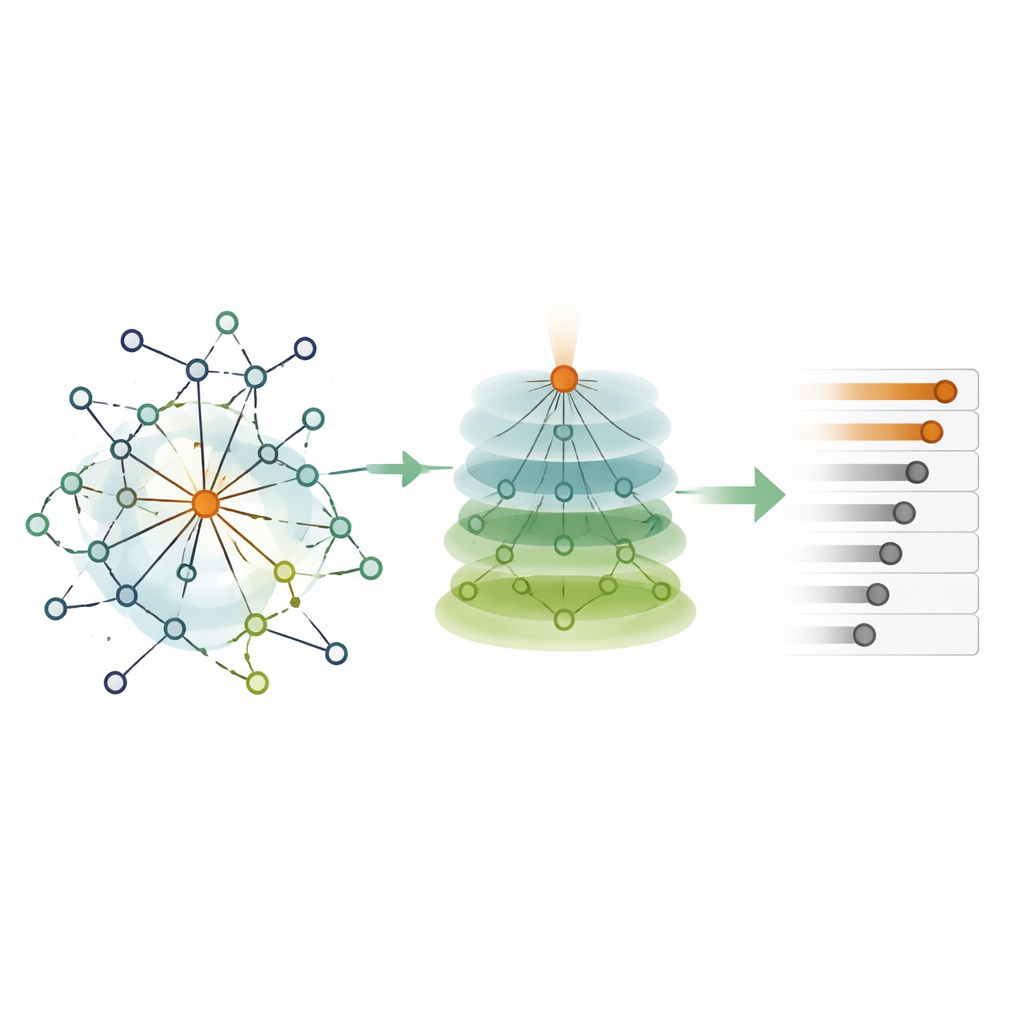
Преобразование сырой влиятельности в итоговый рейтинг
Соединив эти элементы, HKEN сначала вычисляет «начальную влиятельность» каждого узла, суммируя его собственный вес и отфильтрованные, зависящие от расстояния вклады соседей на расстоянии до двух шагов. Затем выполняется второй проход, в котором прямо связанных соседей разрешается усиливать оценки друг друга пропорционально степени совпадения их локальной среды. Во втором проходе целенаправленно сохраняется явный вклад самого узла, чтобы высокоцентральные узлы не были заглушены окружением. В результате получается итоговый балл влияния для каждого узла, который можно отсортировать для получения ранжирования наиболее критичных точек в сети.
Тестирование метода на реальных сетях
Чтобы оценить эффективность HKEN, авторы протестировали его на десяти различных реальных сетях — от классического графа клуба карате до авиамаршрутов, взаимодействий белков и карт научного сотрудничества. Они сравнили HKEN с дюжиной хорошо известных методов ранжирования. Поскольку напрямую определить «истинно» наиболее влиятельные узлы сложно, авторы использовали стандартную модель распространения, позаимствованную из эпидемиологии — модель SIR — чтобы смоделировать, как инфекция будет двигаться по каждой сети при запуске с разных исходных узлов. Затем проверяли, насколько совпадают ранжирования алгоритмов с моделями распространения. В большинстве наборов данных и условий ранжирования HKEN лучше соответствовали симулированному распространению, а выбранные им топ-узлы вызывали более широкие и более быстрые каскады по сравнению с конкурирующими методами, при этом время выполнения оставалось приемлемым для больших сетей.
Что это значит для практики
Проще говоря, работа показывает: внимание и к положению узла в общей сети, и к тому, как ведут себя его непосредственные и вторичныесоседи, даёт более чёткое представление о том, кто действительно формирует влияние. Многоуровневый подход HKEN — баланс локальных связей, глобальной позиции и тонкого перекрытия окружений — позволяет надёжнее выявлять критичные узлы по сравнению со многими существующими инструментами. Это делает метод перспективным для задач вроде обнаружения лидеров мнений в социальных сетях, выявления уязвимых узлов в энергосистемах или транспортных сетях либо целевой организации вмешательств для замедления распространения болезней, причём достаточно эффективно для применения в современных больших и сложных сетях.
Цитирование: Wang, F., Sun, Z., Wang, G. et al. Identifying influential nodes through hierarchical k-shell and extended neighborhood integration. Sci Rep 16, 10215 (2026). https://doi.org/10.1038/s41598-026-40209-y
Ключевые слова: влиятельные узлы, сложные сети, распространение информации, центральность в сети, модель SIR