Clear Sky Science · sv
Maskininlärningsuppskattningar av subnationella urbana växthusgasutsläpp i G20 från 2000–2020
Varför stadens utsläpp angår alla
Städer och regioner står i frontlinjen för klimatförändringarna och lovar omfattande nedskärningar av växthusgasutsläpp. För de flesta saknar vi dock tillförlitliga uppgifter om hur mycket de faktiskt släpper ut varje år. Denna studie tar sig an den blindfläcken genom att använda modern maskininlärning för att uppskatta årliga klimatpåverkande utsläpp för tusentals urbana områden i världens största ekonomier, och ger medborgare, planerare och beslutsfattare en tydligare bild av var framsteg sker — och var de uteblir.
Det växande löftet och datagapet
Under det senaste decenniet har tusentals lokala regeringar lovat klimatåtgärder och många har meddelat mål om nettonoll. Men färre än en av tio har regelbundet rapporterat detaljerade utsläppsinventarier över tid. När städer väl rapporterar skiljer sig metoderna åt, vilka sektorer som inkluderas varierar, och vissa räknar bara utsläpp inom sina gränser medan andra också inkluderar vad som konsumeras någon annanstans. Traditionella förenklingar, som att bara skala ned nationella utsläpp med hjälp av befolkning eller inkomst, missar lokala insatser och döljer verkliga förändringar. Andra rutnätsbaserade globala dataset erbjuder konsekvens men motsvarar inte de faktiska gränser där lokala beslutsfattare agerar, vilket begränsar deras användbarhet för praktisk planering.

En ny karta byggd av maskiner
Författarna bygger ett ramverk med maskininlärning för att uppskatta årliga växthusgasutsläpp från 2000 till 2020 för nästan 6 000 städer och mer än 100 regioner i G20-länderna, som tillsammans står för omkring 80 % av världens utsläpp. De samlar tusentals självrapporterade inventarier från klimatnätverk och myndighetsplattformar och rengör och standardiserar dem noggrant — kontrollerar för dubbletter, orimliga per person-värden, plötsliga toppar eller fall samt inkonsekventa enheter. Varje stad eller region matchas med en officiell administrativ gräns med hjälp av Global Administrative Areas Database, så att prognoserna stämmer överens med verkliga jurisdiktioner som provinser, delstater, län och kommuner.
Mata modellen med ledtrådar från rymden och samhället
För att lära modellen hur olika platser släpper ut tar teamet in ett brett spektrum av offentligt tillgängliga data. Dessa inkluderar satellitbaserade uppskattningar av fossila bränsleutsläpp, sektorspecifika utsläppskartor, elförbrukning och luftföroreningar såsom fina partiklar och kvävedioxid. De lägger till socioekonomiska indikatorer som befolkning och bruttonationalprodukt samt klimatrelevanta mått som uppvärmnings- och kylbehov härlett från väderdata. Med zonal statistik sammanfattar de alla dessa lager inom varje stads- eller regionsgräns och matar dem till ett automatiserat maskininlärningssystem kallat AutoGluon. Detta system testar och kombinerar flera underliggande modeller för att bäst förutsäga de utsläpp som städerna själva rapporterat.
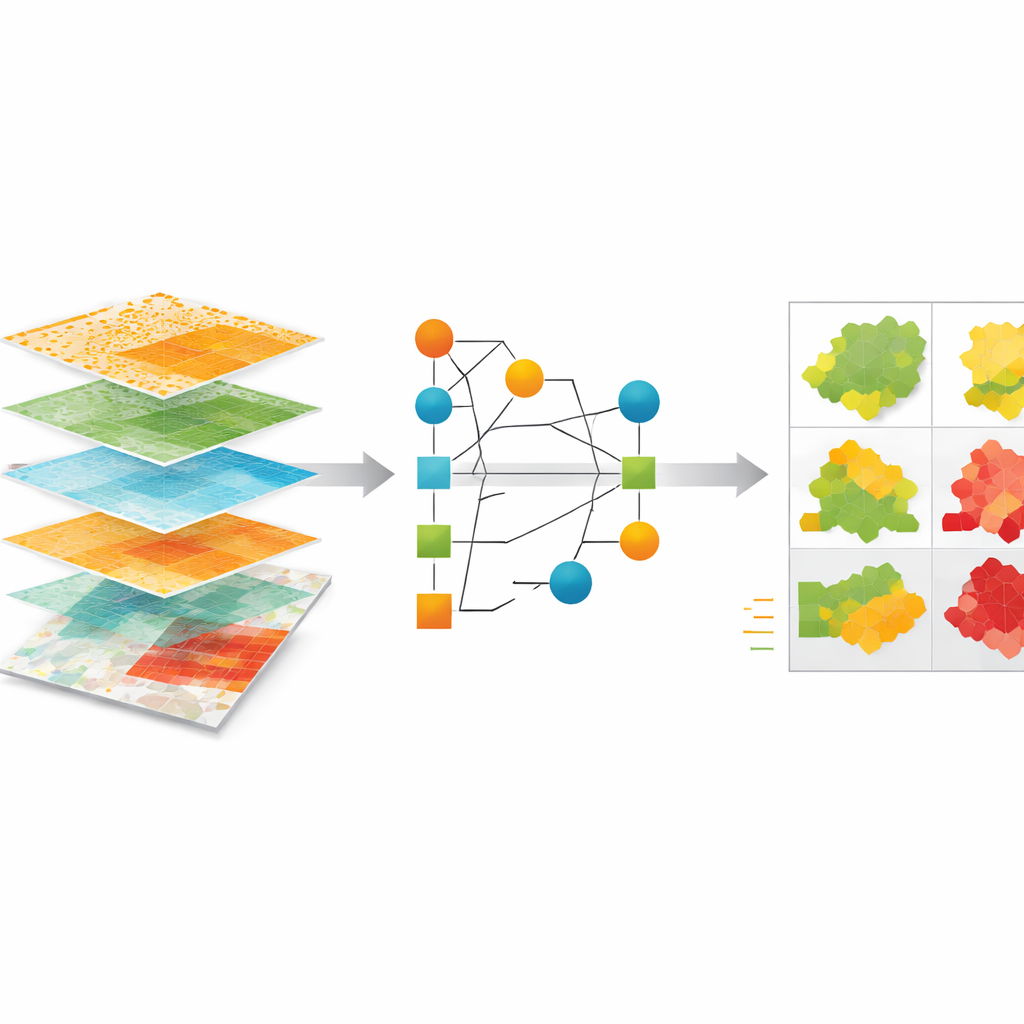
Hur väl uppskattningarna presterar
På de utsläppsdata som reserverats för test förklarar modellen majoriteten av variationen mellan olika platser, där befolkning och inkomst framträder som de mest inflytelserika drivkrafterna, följt av byggnadsutsläpp och elförbrukning. Forskarna jämför också sina uppskattningar med två oberoende dataset som använder andra metoder för att härleda stadsnivå- eller rutnätsbaserade utsläpp. Överensstämmelsen är starkast för större administrativa områden och förblir relativt god på finare skala, även om skillnaderna ökar där indata är glesa eller sektorsbevakningen ofullständig. Genom att konstruera osäkerhetsintervall kring varje prediktion och undersöka hur olika modellkomponenter är oense visar författarna att de största osäkerheterna samlas i regioner med svagast rapportering, särskilt delar av det globala syd.
Vad detta betyder för klimatåtgärder
Slutprodukten är ett öppet dataset med årliga utsläpp för tusentals subnationella myndigheter i G20-länderna från 2000 till 2020, tillsammans med den tränade modellen så att andra kan bygga vidare på den. Dessa uppskattningar är inte avsedda att ersätta lokala inventarier som städerna själva producerar, utan att fungera som en konsekvent referens där sådana inventarier saknas, är ofullständiga eller inte jämförbara. För invånare, förespråkare och beslutsfattare innebär detta att de nu kan se hur utsläppen förändrats över två decennier för specifika städer och regioner, identifiera hetpunkter och bättre spåra om löften omvandlas till verkliga minskningar av klimatpåverkande föroreningar.
Citering: Yu, Y., Wang, X., Manya, D. et al. Machine learning estimates for G20 subnational urban GHG emissions from 2000–2020. Sci Data 13, 487 (2026). https://doi.org/10.1038/s41597-026-06691-9
Nyckelord: urbana växthusgasutsläpp, maskininlärning, G20-städer, klimatdata, subnationell klimatpolitik