Clear Sky Science · nl
Machine learning-schattingen van subnationale stedelijke GHG‑emissies in G20-landen van 2000–2020
Waarom stedelijke emissies iedereen aangaan
Steden en regio’s staan in de frontlinie van de klimaatverandering en beloven diepgaande verminderingen van broeikasgasvervuiling. Voor de meeste van hen weten we echter niet met zekerheid hoeveel ze elk jaar uitstoten. Deze studie pakt dat blinde vlak aan door moderne machine learning te gebruiken om jaarlijkse klimaatverhogende emissies te schatten voor duizenden stedelijke gebieden in ’s werelds grootste economieën, en biedt burgers, planners en beleidsmakers een helderder beeld van waar vooruitgang plaatsvindt — en waar niet.
De groeiende belofte en het gegevensgat
In het afgelopen decennium hebben duizenden lokale overheden zich gecommitteerd aan klimaatactie en velen hebben netto‑nuldoelen aangekondigd. Minder dan één op de tien rapporteert echter regelmatig gedetailleerde emissieinventarissen in de tijd. Wanneer steden wel rapporteren, verschillen hun methoden, variëren de sectoren die ze meenemen en tellen sommigen alleen emissies binnen hun grenzen terwijl anderen ook consumptie elders meenemen. Traditionele omwegen, zoals het simpelweg schalen van nationale emissietotalen naar steden op basis van bevolking of inkomen, missen lokale inspanningen en verhullen echte veranderingen. Andere gegroepeerde wereldwijde datasets bieden consistentie, maar sluiten niet aan op de feitelijke bestuurlijke grenzen waar lokale leiders beslissen, wat hun bruikbaarheid voor praktische planning beperkt.

Een nieuwe kaart gebouwd door machines
De auteurs bouwen een machine learning‑kader om jaarlijkse broeikasgasemissies te schatten van 2000 tot 2020 voor bijna 6.000 steden en meer dan 100 regio’s in de G20‑landen, die samen ongeveer 80% van de wereldwijde emissies vertegenwoordigen. Ze verzamelen duizenden zelfgerapporteerde inventarissen uit klimaatnetwerken en overheidsplatforms en schonen en standaardiseren die zorgvuldig — ze controleren op dubbele vermeldingen, onwaarschijnlijke per‑persoonwaarden, plotselinge pieken of dalen en inconsistente eenheden. Elke stad of regio wordt gekoppeld aan een officiële administratieve grens met behulp van de Global Administrative Areas Database, zodat voorspellingen overeenkomen met reële jurisdicties zoals provincies, staten, districten en gemeenten.
Het model voeden met aanwijzingen uit ruimte en samenleving
Om het model te leren hoe verschillende plaatsen uitstoten, haalt het team een breed scala aan publiek beschikbare gegevens binnen. Deze omvatten satellietgebaseerde schattingen van fossiele brandstofemissies, sectorspecifieke emissiekaarten, elektriciteitsgebruik en luchtverontreiniging zoals fijnstof en stikstofdioxide. Ze voegen sociaaleconomische indicatoren toe zoals bevolking en bruto binnenlands product, evenals klimaatgerelateerde maatstaven zoals verwarmings‑ en koelbehoeften afgeleid van weergegevens. Met zonale statistieken vatten ze al deze lagen samen binnen elke stedelijke of regionale grens en voeden ze in een geautomatiseerd machine learning‑systeem genaamd AutoGluon. Dit systeem test en combineert meerdere onderliggende modellen om het beste de emissies te voorspellen die steden zelf hebben gerapporteerd.
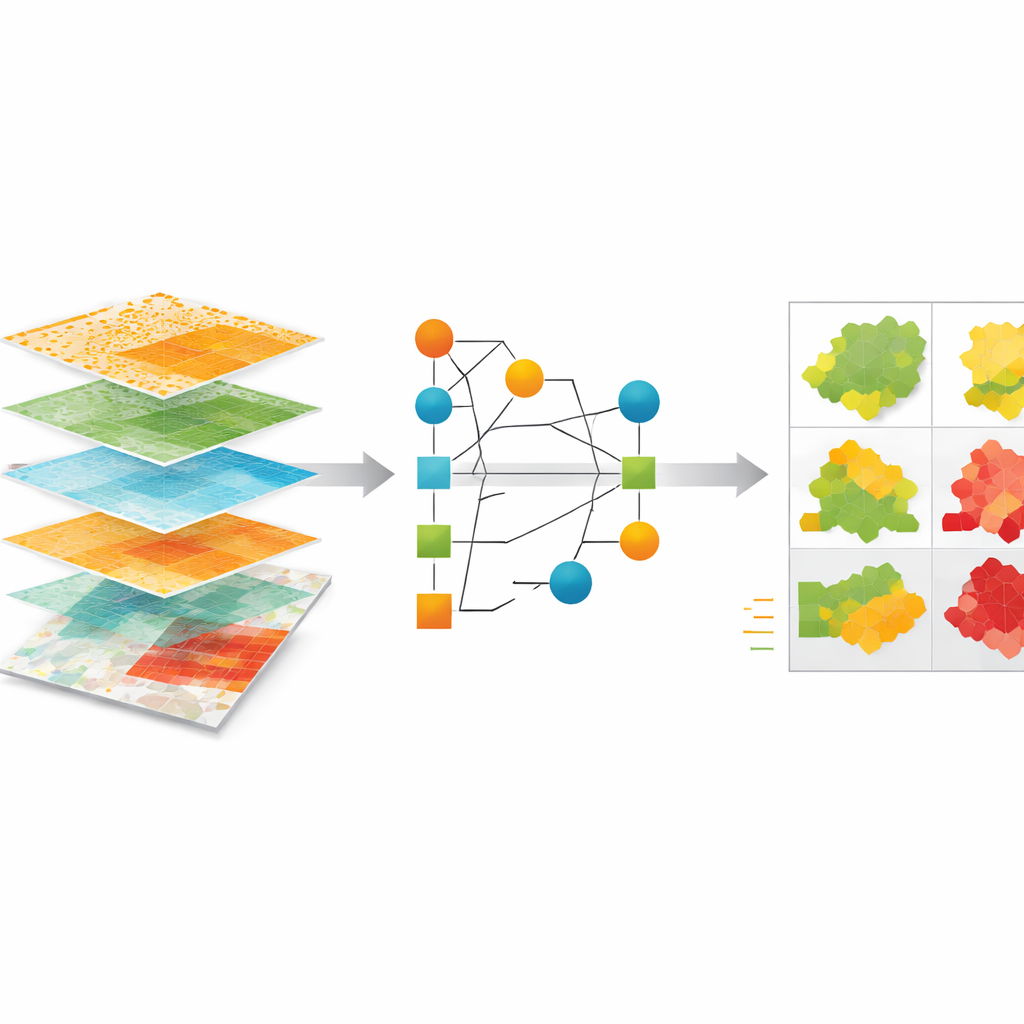
Hoe goed de schattingen presteren
Op de emissiegegevens die voor testen waren gereserveerd, verklaart het model het grootste deel van de variatie tussen verschillende plaatsen, waarbij bevolking en inkomen naar voren komen als de meest bepalende factoren, gevolgd door gebouwgebonden emissies en elektriciteitsgebruik. De onderzoekers vergelijken hun schattingen ook met twee onafhankelijke datasets die andere methoden gebruiken om stedelijke of gegroepeerde emissies af te leiden. De overeenstemming is het sterkst voor grotere administratieve gebieden en blijft redelijk goed op fijnere schaal, hoewel verschillen toenemen waar invoergegevens schaars zijn of de sectorale dekking incompleet is. Door onzekerheidsbereiken rond elke voorspelling op te bouwen en te onderzoeken hoe verschillende modelcomponenten van elkaar verschillen, tonen de auteurs aan dat de grootste onzekerheden geconcentreerd zijn in regio’s met de zwakste rapportage, met name delen van het mondiale Zuiden.
Wat dit betekent voor klimaatactie
Het eindproduct is een openbaar beschikbare dataset van jaarlijkse emissies voor duizenden subnationale overheden in G20‑landen van 2000 tot 2020, samen met het getrainde model zodat anderen het kunnen uitbreiden. Deze schattingen zijn niet bedoeld ter vervanging van lokale inventarissen die steden zelf opstellen, maar fungeren als een consistente basislijn waar dergelijke inventarissen ontbreken, onvolledig zijn of niet vergelijkbaar. Voor inwoners, voorvechters en besluitvormers betekent dit dat ze nu kunnen zien hoe emissies in twee decennia zijn veranderd voor specifieke steden en regio’s, hotspots kunnen identificeren en beter kunnen volgen of beloften zich vertalen in daadwerkelijke verminderingen van klimaatvervuiling.
Bronvermelding: Yu, Y., Wang, X., Manya, D. et al. Machine learning estimates for G20 subnational urban GHG emissions from 2000–2020. Sci Data 13, 487 (2026). https://doi.org/10.1038/s41597-026-06691-9
Trefwoorden: stedelijke broeikasgasemissies, machine learning, G20-steden, klimaatgegevens, subnationaal klimaatbeleid