Clear Sky Science · sv
Modellering av uppmärksamhet och bindning i hjärnan genom bidirektionell återkopplad grindning
Hur hjärnan vet vad den ska titta på
Varje ögonblick översköljer dina ögon hjärnan med mycket mer information än du någonsin skulle kunna uppfatta medvetet. Ändå kan du utan ansträngning plocka ut en vän i en folkmassa, följa en rörlig bil eller leta efter nycklar på ett stökigt bord. Denna förmåga att fokusera på det som betyder något, koppla ihop rätt egenskaper och ignorera distraktioner kallas uppmärksamhet. Artikeln som beskrivs här presenterar en ny hjärninspirerad datorsmodell som syftar till att förklara hur en så mångfald av uppmärksamhetsbeteenden kan uppstå från en enda underliggande mekanism.
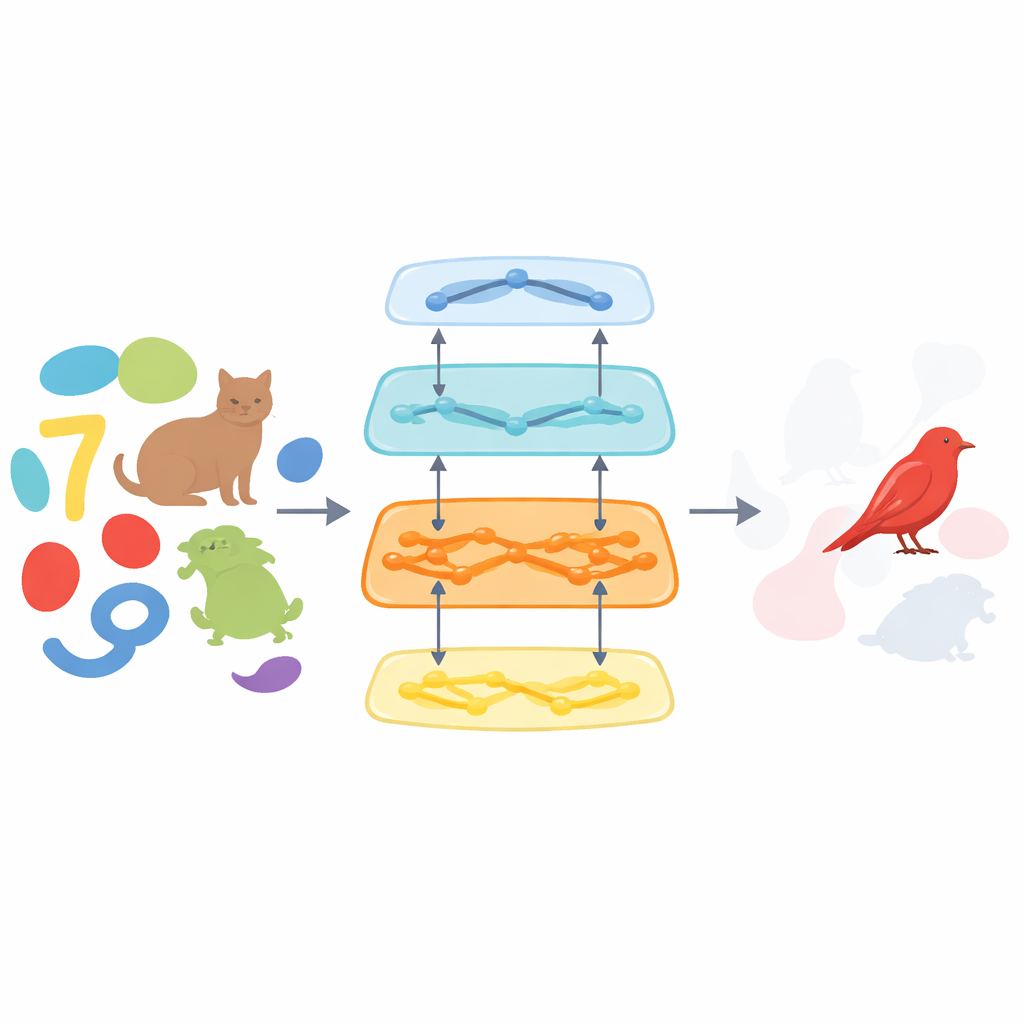
En modell för många typer av fokus
Uppmärksamhet är inte bara en sak. Ibland fokuserar vi på en plats i rummet, som en strålkastare. Ibland ställer vi in oss på en egenskap, som en viss färg, och ibland låser vi oss på hela objekt och håller deras delar samman även när de rör sig eller delvis är dolda. Författarna argumenterar för att istället för separata, särskilda system kan alla dessa former av uppmärksamhet uppstå ur ett gemensamt kretsmönster i hjärnans visuella bana. De bygger en modell som efterliknar den ventrala visuella strömmen, de hjärnområden som omvandlar råa pixlar på näthinnan till igenkännbara objekt. I deras design rör sig en bana information uppåt och extraherar visuella egenskaper, medan en annan bana skickar signaler nedåt och avgör vilka egenskaper som ska förstärkas eller försvagas.
Grindar som talar åt båda håll
Kärnan i modellen är något författarna kallar bidirektionell återkopplad grindning. Föreställ dig ett staplat antal visuella bearbetningsstadier, från enkla kanter till komplexa former. Vid varje stadium bär den framåtriktade signalen vad som finns i bilden, medan en bakåtriktad och sidledes signal bär vad som för närvarande är relevant för uppgiften. Dessa signaler möts vid “grindar” som multiplicativt höjer eller sänker aktivitetsnivån för egenskaper över flera tidssteg. Eftersom kopplingarna är återkopplade kan modellen förfina sitt fokus över tid, ungefär som när du först skymtar en rörig scen och sedan gradvis zoomar in på ett mål. Denna arkitektur tränas med standardtekniker inom maskininlärning på två grundläggande mål—klassificera vad som finns och segmentera var det finns—men den får inte explicit besked om hur den ska implementera uppmärksamhet.
Lära sig söka, spåra och ignorera distraktioner
När modellen har tränats testas den i en rad klassiska uppmärksamhetsuppgifter som vanligen ges till människor och djur. Med bilder byggda av handskrivna siffror och från naturliga fotografier av djur lär den sig att känna igen objekt i röra, gruppera element som cue:as, följa rörliga föremål och utföra visuell sökning baserad på antingen visuella vinkar eller symboliska signaler som pilar. Den kan markera ett enda udda objekt i en matris, skifta uppmärksamheten från ett objekt till nästa utan att fastna på samma, och spåra ett mål över tid samtidigt som den ignorerar störande objekt. Anmärkningsvärt är att många av dessa beteenden framträder även när modellen endast får feedback om slutliga svaret, inte om vart den borde ha tittat, vilket antyder att uppmärksamhetsstrategier kan uppstå som en bieffekt av att lära sig lösa relevanta uppgifter.
Spegling av mänsklig perception och hjärnsignaler
Författarna frågar sedan om modellen beter sig som människor i mer subtila avseenden. I kontrollerade tester med enkla mönstrade fläckar visar modellen förbättrad känslighet när en cue pekar mot rätt plats, och dess prestanda sjunker när många distraktorer är närvarande—parallellt med mänskliga fynd om kontrastkänslighet och perceptuell belastning. Den ”går också på” en klassisk perceptuell illusion där en synlig ockluderare gör en fragmenterad form lättare att känna igen, vilket antyder att den representerar figur och bakgrund på ett hjärnliknande sätt. När man tittar in i nätverket visar enheter i djupare lager responsförstärkningar när deras föredragna objekt uppmärksammas, utan att deras grundläggande avstämning ändras, liknande neuroner i primaters visuella cortex. Skilda grupper av enheter beter sig som funktionsdetektorer och som celler för ”gränsägarskap” som hjälper till att avgöra vilken sida av en kant som tillhör figuren och vilken som tillhör bakgrunden.

Varför detta är viktigt för hjärnor och maskiner
Arbetet tyder på att många karakteristiska drag hos biologisk uppmärksamhet—orientering mot cues, filtrering av irrelevant röra, sökande efter mål, bindning av egenskaper till sammanhängande objekt och till och med vissa medvetandebrister—alla kan uppstå från en enda arkitektonisk princip: återkommande grindning mellan en egenskapsbana och en uppmärksamhetsbana. Enkelt uttryckt visar modellen hur ett system som upprepade gånger omviktar vad det ser, baserat på aktuella mål och kontext, kan lära sig att ”uppmärksamma” utan att bli explicit programmerat för det. Detta ger neurovetare en konkret, testbar ram för att förstå uppmärksamhet och bindning i hjärnan, och erbjuder artificiella intelligensforskare ett biologiskt inspirerat alternativ till dagens i stor utsträckning framåtriktade konstruktioner.
Citering: Salehi, S., Lei, J., Benjamin, A.S. et al. Modeling attention and binding in the brain through bidirectional recurrent gating. Nat Commun 17, 4072 (2026). https://doi.org/10.1038/s41467-026-72146-9
Nyckelord: visuell uppmärksamhet, funktionsbindning, rekurrenta neurala nätverk, beräkningsneurovetenskap, hjärninspirerad AI