Clear Sky Science · es
Modelado de la atención y la unión en el cerebro mediante compuertas recurrentes bidireccionales
Cómo sabe el cerebro dónde mirar
Cada momento, tus ojos bombardean al cerebro con mucha más información de la que podrías notar conscientemente. Aun así, puedes identificar sin esfuerzo a un amigo en una multitud, seguir un coche en movimiento o buscar las llaves en una mesa desordenada. Esta capacidad de centrarse en lo que importa, vincular las características correctas y ignorar distracciones se llama atención. El artículo aquí descrito presenta un nuevo modelo informático inspirado en el cerebro que pretende explicar cómo una amplia variedad de trucos atencionales podría surgir de un único mecanismo subyacente.
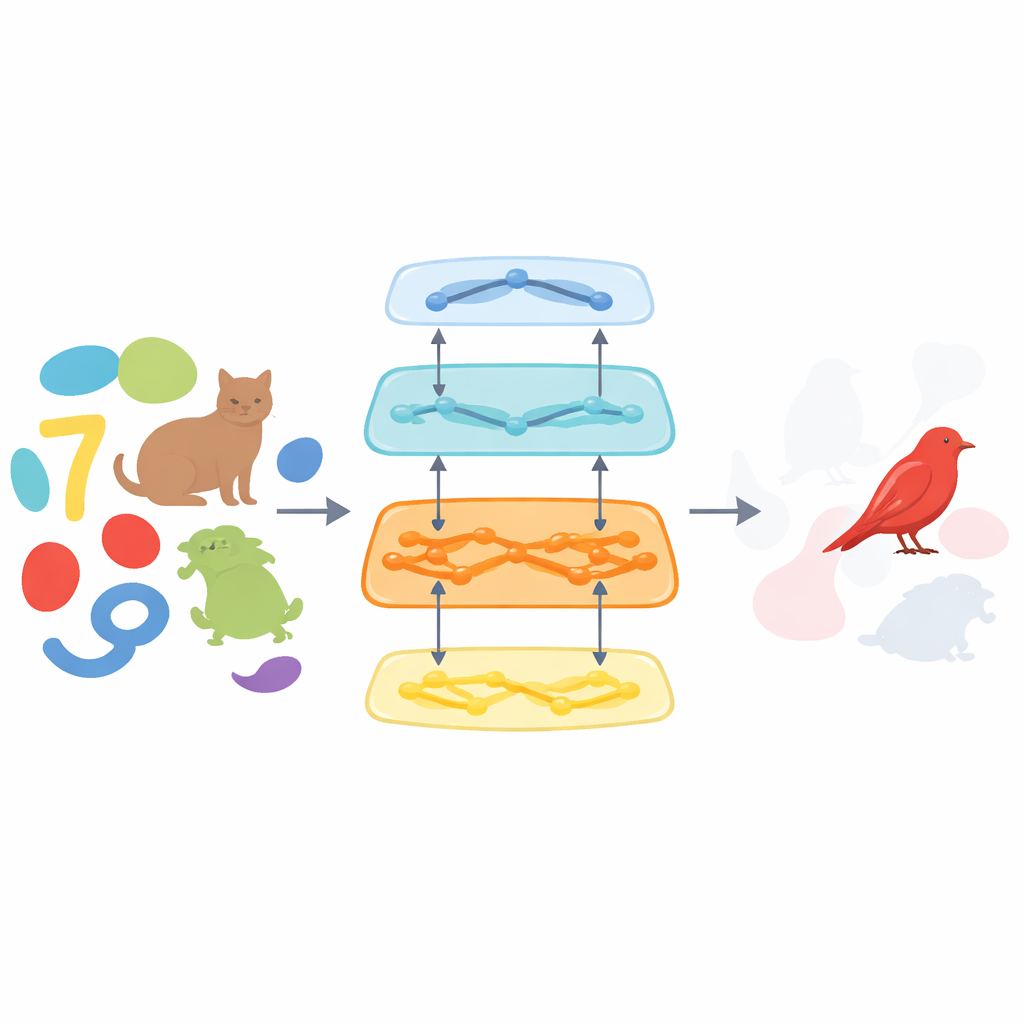
Un solo modelo para muchos tipos de enfoque
La atención no es una sola cosa. A veces nos enfocamos en un lugar del espacio, como un foco. A veces sintonizamos una característica, como un color concreto, y otras veces nos fijamos en objetos enteros, manteniendo sus partes unidas aunque se muevan o estén parcialmente ocultos. Los autores sostienen que, en vez de sistemas separados y con propósitos especiales, todas estas formas de atención pueden emerger de un patrón circulatorio común en la vía visual del cerebro. Construyen un modelo que imita la corriente visual ventral, el conjunto de regiones cerebrales que transforma los píxeles de la retina en objetos reconocibles. En su diseño, una vía mueve la información hacia arriba, extrayendo características visuales, mientras que otra envía señales hacia abajo para decidir qué características deben reforzarse o debilitarse.
Compuertas que se comunican en ambos sentidos
El núcleo del modelo es algo que los autores llaman compuertas recurrentes bidireccionales. Imagina una pila de etapas de procesamiento visual, desde bordes simples hasta formas complejas. En cada etapa, la señal que avanza transporta lo que hay en la imagen, mientras que una señal que va hacia atrás y en paralelo transporta lo que es actualmente relevante para la tarea. Estas señales se encuentran en “compuertas” que multiplicativamente aumentan o disminuyen la actividad de las características a lo largo de varios pasos temporales. Debido a que las conexiones son recurrentes, el modelo puede refinar su enfoque con el tiempo, del mismo modo que tú lo haces cuando al principio vislumbras una escena desordenada y luego te concentras gradualmente en un objetivo. Esta arquitectura se entrena con técnicas estándar de aprendizaje automático en dos objetivos básicos—clasificar qué está presente y segmentar dónde está—sin que se le indique explícitamente cómo implementar la atención.
Aprender a buscar, seguir e ignorar distracciones
Una vez entrenado, el modelo se pone a prueba en una batería de tareas clásicas de atención que suelen administrarse a humanos y animales. Usando imágenes construidas a partir de dígitos manuscritos y de fotografías naturales de animales, aprende a reconocer objetos en el desorden, agrupar elementos que son señalados, seguir ítems en movimiento y realizar búsquedas visuales basadas tanto en pistas visuales como en señales simbólicas, como flechas. Puede resaltar un único elemento discordante en una cuadrícula, cambiar la atención de un objeto a otro sin quedarse “atrapado” en el mismo, y seguir un objetivo a lo largo del tiempo mientras ignora distractores. De forma notable, muchos de estos comportamientos aparecen incluso cuando el modelo solo recibe retroalimentación sobre la respuesta final, no sobre dónde debería haber mirado, lo que sugiere que las estrategias atencionales pueden surgir como un efecto secundario de aprender a resolver tareas relevantes.
Reflejando la percepción humana y las señales cerebrales
Los autores se preguntan entonces si el modelo se comporta como los humanos en formas más sutiles. En pruebas controladas con parches de patrones simples, el modelo muestra una mayor sensibilidad cuando una pista apunta a la ubicación correcta, y su rendimiento cae cuando hay muchos distractores—paralelamente a los hallazgos humanos sobre sensibilidad al contraste y carga perceptual. También “cae” en una ilusión perceptual clásica en la que un oclusor visible hace que una forma fragmentada sea más fácil de reconocer, lo que sugiere que representa figura y fondo de manera similar al cerebro. Al mirar dentro de la red, unidades en capas más profundas muestran aumentos de respuesta cuando su objeto preferido es atendido, sin cambiar su afinación básica, de forma parecida a las neuronas en la corteza visual de primates. Grupos distintos de unidades se comportan como detectores de características y como células de “pertenencia al borde” que ayudan a decidir qué lado de un borde pertenece a la figura y cuál al fondo.

Por qué esto importa para cerebros y máquinas
El trabajo sugiere que muchas características distintivas de la atención biológica—orientarse hacia pistas, filtrar el desorden irrelevante, buscar objetivos, unir características en objetos coherentes e incluso algunas fallas de la conciencia—pueden surgir de un único principio arquitectónico: el engrasado recurrente entre una vía de características y una vía de atención. En términos simples, el modelo muestra cómo un sistema que repondera repetidamente lo que ve, en función de metas y contexto actuales, puede aprender a “prestar atención” sin estar programado explícitamente para ello. Esto ofrece a los neurocientíficos un marco concreto y comprobable para entender la atención y la unión en el cerebro, y brinda a los investigadores de inteligencia artificial una alternativa inspirada biológicamente frente a los diseños actuales, en gran parte feedforward.
Cita: Salehi, S., Lei, J., Benjamin, A.S. et al. Modeling attention and binding in the brain through bidirectional recurrent gating. Nat Commun 17, 4072 (2026). https://doi.org/10.1038/s41467-026-72146-9
Palabras clave: atención visual, unión de características, redes neuronales recurrentes, neurociencia computacional, IA inspirada en el cerebro