Clear Sky Science · ru
Воспроизводимый бенчмарк алгоритмов обнаружения QRS на разнородных ЭКГ-датасетах и в условиях шума
Почему важно отслеживать каждое сердцебиение
Каждое сокращение сердца оставляет крошечный электрический след на электрокардиограмме (ЭКГ). Точное определение пика каждого удара необходимо для расчёта частоты сердечных сокращений и тонких вариаций между ударами, которые отражают стресс, качество сна и риск сердечных заболеваний. По мере того как ЭКГ-датчики переходят из больничных мониторов в наручные и грудные носимые устройства, исследователям нужно понимать, какие компьютерные методы способны надёжно находить эти пики, когда в реальной жизни добавляются движение, шум и нечёткие данные.
Задача: найти чистые пики в шумных сигналах
Исследование сосредоточено на обнаружении конкретной точки сигнала ЭКГ, называемой R-пиком — остром всплеске, отмечающем каждое сердцебиение. Эти пики служат точками отсчёта для частоты сердцебиения и для вариабельности сердечного ритма, показателя, применяемого в кардиологии, неврологии и исследованиях стресса. В идеальных условиях пики легко видны, но в реальных записях сигнал искажается движением тела, неплотно прилегающими электродами, электромагнитными помехами и индивидуальными особенностями, особенно у людей с нерегулярными ритмами. Даже один пропущенный или ошибочно отмеченный пик может исказить последующий анализ, поэтому важно не только то, как метод работает на чистых данных, но и насколько надёжно он действует у разных людей и в разных ситуациях записи.
Создание общей испытательной платформы для детекторов сердцебиения
Чтобы ответить на это, авторы собрали воспроизводимый бенчмарк из 17 методов обнаружения R-пиков. Они включают классические методы обработки сигналов с фильтрами и математическими правилами, а также модели машинного и глубокого обучения, которые извлекают закономерности из данных. Все методы оценивались одинаково на пяти открытых базах ЭКГ с платформы PhysioNet, охватывающих длительный мониторинг, записи в покое, движение при ходьбе и беге, нерегулярные сердечные ритмы и записи с добавленным искусственным шумом. Для методов на основе обучения исследователи обучали каждую модель только на отдельном публичном наборе данных и затем фиксировали её параметры, чтобы тесты отражали, насколько хорошо модели обобщаются на новых пациентах и условиях, которых они ранее не видели.
Кто выигрывает: вручную настроенные правила или обученные модели
На более чем миллионе сердечных сокращений проявились явные тенденции. Классические методы обработки сигналов, особенно подход «Blocks of Interest», показали наиболее стабильную производительность при объединении всех баз данных. Рекуррентная нейронная сеть, анализирующая последовательности ударов, превосходила в самых шумных записях, сохраняя высокую точность там, где сигнал был сильно загрязнён. Модели глубокого обучения могли показывать отличные результаты на отдельных наборах данных, особенно при сильном шуме, но их показатели чаще падали, когда новые данные отличались от обучающей выборки. Старые референсные методы, предполагающие очень регулярный ритм, испытывали трудности с записями пациентов с аритмиями, где ритм по определению нерегулярный.
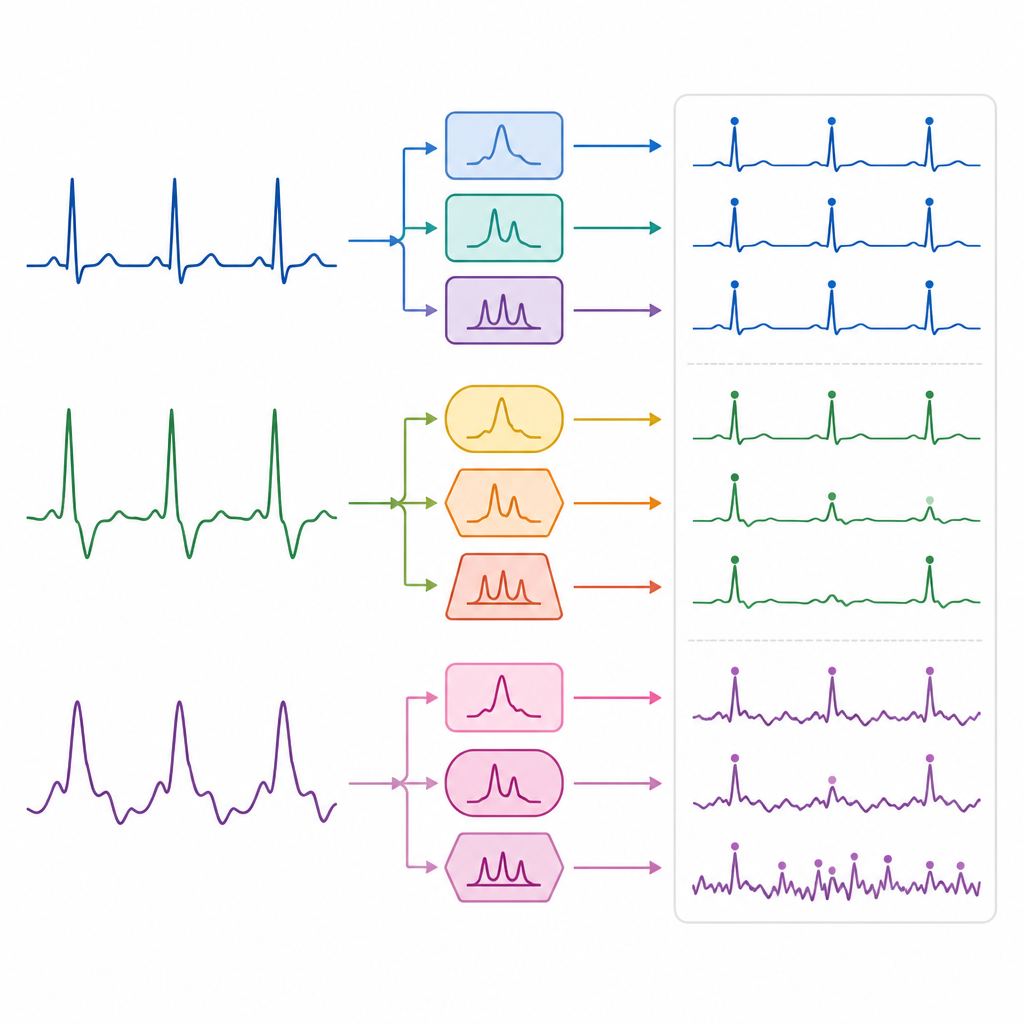
Как шум и движение влияют на показатели
Сравнение условий показало, как разные источники помех влияют на работу алгоритмов. Все алгоритмы работали очень хорошо на расслабленных записях в покое и на данных движения от сидящих испытуемых. Как только участники начинали ходить или бежать, качество обнаружения чуть снижалось практически у каждого метода, что отражает воздействие движения на носимые датчики. В экстремальном случае специализированной базы с шумовыми нагрузками общие показатели падали для всех подходов, но рекуррентная сеть оставалась относительно стабильной, намекая, что учёт контекста нескольких последовательных ударов помогает ей «видеть» сквозь помехи. Эти закономерности показывают, что не существует универсального детектора, который был бы лучшим во всём, и что комбинирование методов или переключение стратегий в зависимости от оценённого уровня шума может быть полезным.
Что это значит для врачей, устройств и исследователей
Для клиницистов и разработчиков носимых устройств ключевой практический вывод таков: если нужен алгоритм, который хорошо работает «из коробки» на многих типах ЭКГ, проверенные подходы обработки сигналов всё ещё остаются безопасным выбором, тогда как методы глубокого обучения могут потребовать тщательно подобранных и разнообразных обучающих данных, чтобы избежать сюрпризов в новых условиях. Авторы также предоставляют полный код, ссылки на данные и скрипты оценки в открытом виде, чтобы будущие команды могли подключать новые алгоритмы и тестировать их в тех же условиях. Вместо провозглашения одного победителя работа картирует сильные и слабые стороны ведущих методов и побуждает сообщество создавать более надёжные и удобные для обмена инструменты для чтения ритмов сердца.
Цитирование: Wolf, S.M., Rahlmeier, T., Lustfeld, S. et al. A reproducible benchmark of QRS detection algorithms across diverse ECG datasets and noise conditions. Sci Rep 16, 15748 (2026). https://doi.org/10.1038/s41598-026-53724-9
Ключевые слова: ЭКГ, обнаружение R-пиков, вариабельность сердечного ритма, обработка сигналов, глубокое обучение