Clear Sky Science · pl
Powtarzalny benchmark algorytmów wykrywania zespołów QRS w różnych bazach danych ECG i warunkach szumowych
Dlaczego śledzenie każdego uderzenia ma znaczenie
Każde uderzenie serca zostawia niewielki ślad elektryczny na elektrokardiogramie (ECG). Precyzyjne wyznaczenie szczytu każdego załamka jest kluczowe do obliczania częstości rytmu serca oraz subtelnych różnic między uderzeniami, które informują o stresie, jakości snu i ryzyku chorób serca. W miarę jak czujniki ECG przenoszą się z monitorów szpitalnych na opaski na nadgarstek i pasy piersiowe, badacze muszą wiedzieć, które metody komputerowe nadal potrafią wiarygodnie odnaleźć te szczyty, gdy w realnym użyciu pojawiają się ruch, szum i nieuporządkowane dane.
Wyzwanie: znajdowanie czystych pików w zaszumionych sygnałach
Badanie koncentruje się na wykrywaniu punktu w sygnale ECG zwanego załamkiem R — ostrego pikowego zgrubienia, które oznacza każde uderzenie serca. Te piki stanowią punkty odniesienia dla pomiaru tętna i zmienności rytmu serca, mierzonej w kardiologii, neurologii i badaniach nad stresem. W idealnych warunkach piki są łatwe do zauważenia, ale w rzeczywistych zapisach sygnał bywa zniekształcony przez ruch ciała, luźne elektrody, zakłócenia elektryczne oraz naturalne różnice między osobami, zwłaszcza u pacjentów z nieregularnymi rytmami. Nawet jedno pominięte lub błędnie wykryte załamanie może wypaczyć dalsze analizy, dlatego pytanie brzmi nie tylko jak metoda radzi sobie na czystych danych, ale jak niezawodnie działa w różnych populacjach i warunkach nagrania.
Budowanie wspólnego środowiska testowego dla detektorów uderzeń
Aby to rozstrzygnąć, autorzy opracowali powtarzalny benchmark obejmujący 17 metod wykrywania załamka R. Obejmują one klasyczne techniki przetwarzania sygnału stosujące filtry i reguły matematyczne, a także modele uczące się — w tym uczenie maszynowe i głębokie — które wydobywają wzorce z danych. Wszystkie metody oceniono w jednakowy sposób, korzystając z pięciu otwartych baz ECG dostępnych na platformie PhysioNet, obejmujących monitorowanie długoterminowe, zapisy w spoczynku, ruch podczas chodzenia i biegania, nieregularne rytmy oraz zapisy z dodanym sztucznym szumem. Dla metod opartych na uczeniu badacze trenowali każdy model wyłącznie na odrębnym publicznym zestawie danych, a następnie utrwalili jego ustawienia, aby testy odzwierciedlały, jak dobrze modele uogólniają do nowych pacjentów i warunków, których wcześniej nie widziały.
Kto wygrywa: ręcznie dopracowane reguły czy modele uczone
Na ponad milionie uderzeń serca wyłoniły się wyraźne trendy. Klasyczne metody przetwarzania sygnału, w szczególności podejście zwane Blocks of Interest, zapewniły najbardziej konsekwentną wydajność przy łącznym rozpatrywaniu wszystkich baz danych. Recurrent neural network analizująca sekwencje uderzeń wyróżniła się w najbardziej zaszumionych zapisach, utrzymując wyższą dokładność niż większość konkurentów, gdy sygnał był silnie skażony. Modele głębokiego uczenia mogły osiągać znakomite wyniki na wybranych zestawach danych, szczególnie przy silnym szumie, ale ich wydajność zwykle spadała bardziej, gdy nowe dane różniły się od materiału treningowego. Starsze metody referencyjne zakładające bardzo regularne tętno miały trudności z nagraniami pacjentów z arytmiami, gdzie rytm z definicji jest nieregularny.
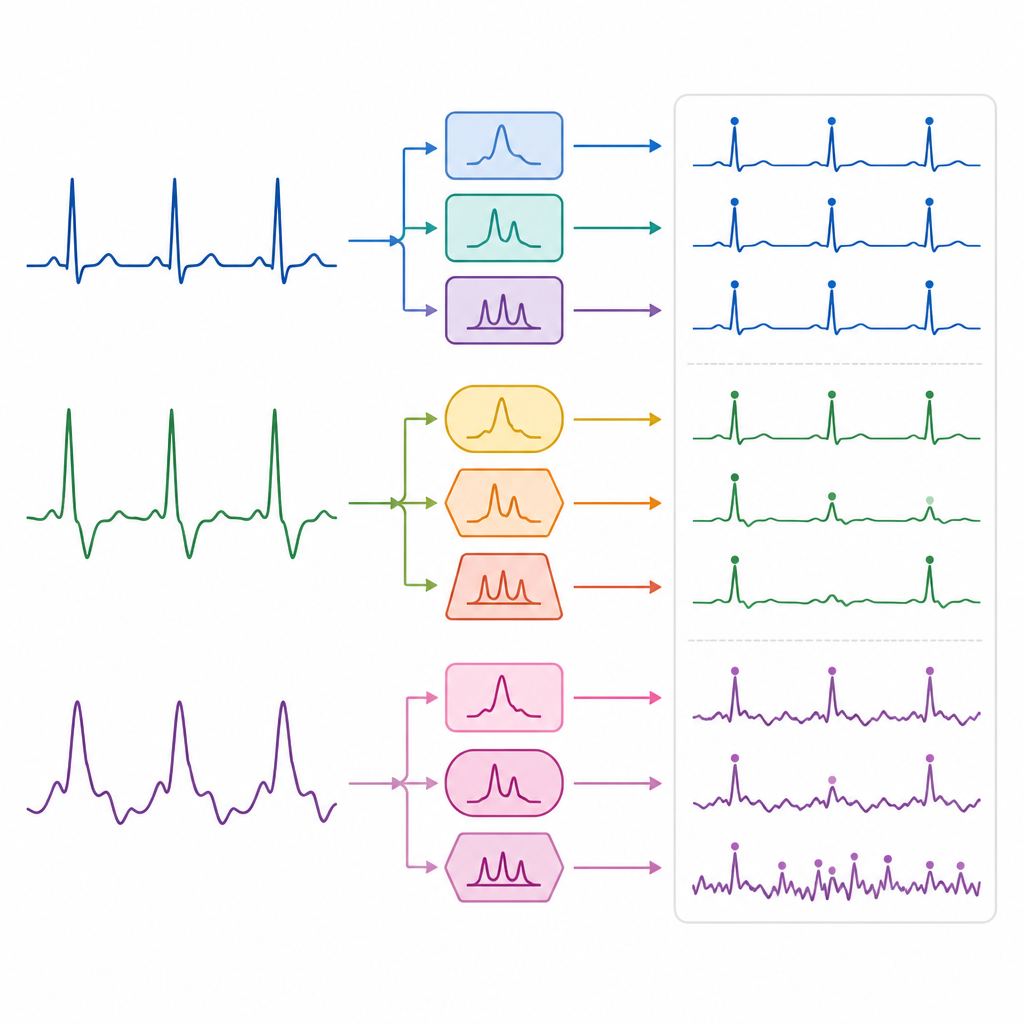
Co robią szumy i ruch z wynikami
Porównując różne warunki, autorzy pokazali, jak źródła zakłóceń wpływają na skuteczność. Wszystkie algorytmy działały bardzo dobrze na odprężonych zapisach w spoczynku oraz na danych ruchowych od osób siedzących. Gdy uczestnicy zaczęli chodzić lub biegać, jakość wykrywania nieznacznie, ale konsekwentnie spadała dla niemal każdej metody, co odzwierciedla wpływ ruchu na czujniki noszone na ciele. W skrajnym przypadku dedykowanej bazy danych obciążonej szumem, ogólne wyniki spadły dla wszystkich podejść, lecz sieć rekurencyjna pozostała stosunkowo stabilna, sugerując, że wykorzystanie kontekstu z kilku kolejnych uderzeń pomaga jej przebić się przez zakłócenia. Te wzorce wskazują, że nie istnieje jeden detektor najlepszy we wszystkich sytuacjach i że łączenie metod lub zmiana strategii w zależności od szacowanego poziomu szumu może być korzystna.
Co to oznacza dla lekarzy, urządzeń i badaczy
Dla klinicystów i twórców urządzeń noszonych główne przesłanie jest praktyczne: jeśli potrzebujesz algorytmu, który dobrze działa od razu na wielu rodzajach zapisów ECG, sprawdzone podejścia z zakresu przetwarzania sygnału wciąż są bezpiecznym wyborem, podczas gdy metody głębokiego uczenia mogą wymagać starannie dobranych i zróżnicowanych danych treningowych, aby uniknąć niespodzianek w nowych warunkach. Autorzy udostępniają także pełny kod, linki do danych i skrypty oceniające jako otwarty framework, aby przyszłe zespoły mogły podłączać nowe algorytmy i testować je w tych samych warunkach. Zamiast koronować jednego zwycięzcę, praca mapuje mocne i słabe strony wiodących metod oraz zachęca społeczność do tworzenia bardziej odpornych, łatwych do udostępniania narzędzi do odczytu rytmów serca.
Cytowanie: Wolf, S.M., Rahlmeier, T., Lustfeld, S. et al. A reproducible benchmark of QRS detection algorithms across diverse ECG datasets and noise conditions. Sci Rep 16, 15748 (2026). https://doi.org/10.1038/s41598-026-53724-9
Słowa kluczowe: ECG, wykrywanie załamka R, zmienność rytmu serca, przetwarzanie sygnałów, uczenie głębokie