Clear Sky Science · ru
Классификация Escherichia coli на основе данных с использованием языковой модели белков выявляет гены, определяющие O-серотип
Почему это важно для повседневного здоровья
Когда люди слышат про Escherichia coli, или E. coli, они часто думают об отравлениях пищей и загрязнённой воде. Но не все E. coli опасны, и даже вредоносные штаммы бывают множеством тонко отличающихся «типов», что влияет на их распространение и тяжесть болезни. В этом исследовании показано, как метод искусственного интеллекта, изначально созданный для понимания белков, способен точнее и справедливее разделять эти бактериальные типы, особенно редкие, которые традиционные инструменты часто упускают. Это может ускорить отслеживание вспышек и сделать проектирование вакцин более обоснованным.
Видеть микробы в разнообразии образов
Врачи и микробиологи разделяют E. coli на «серотипы» — как разные «лица», сформированные сахарами на поверхности клетки. Важной частью этого покрытия является O-антиген, который очень вариабелен между штаммами — известно более 180 вариантов. Определение O-типа в образце пациента или пищи помогает проследить источник инфекции и установить связь с предыдущими вспышками. Сегодня лаборатории обычно делают это либо смешиванием бактерий с антителами и наблюдением агглютинации, либо сравнением ДНК с референсными библиотеками. Но эти методы дают сбои, когда штамм необычен, его гены слегка отличаются или базы эталонов неполные.
Обучение компьютера «читать» белки
Исследователи подошли иначе, вдохновившись языковыми технологиями. Современные «языковые модели белков» учатся на миллионах последовательностей белков, подобно тому как текстовые модели — на предложениях. Здесь использовали одну из таких моделей, ESM-2, чтобы превратить каждый бактериальный белок в числовой отпечаток — короткий вектор, улавливающий его биохимические и эволюционные особенности. На основе более чем 11 000 хорошо аннотированных геномов E. coli из общедоступной базы они сгруппировали родственные гены в семейства, перевели их белки в эти отпечатки и затем обучили алгоритмы машинного обучения предсказывать O-тип непосредственно по этим паттернам, а не по простому совпадению ДНК.
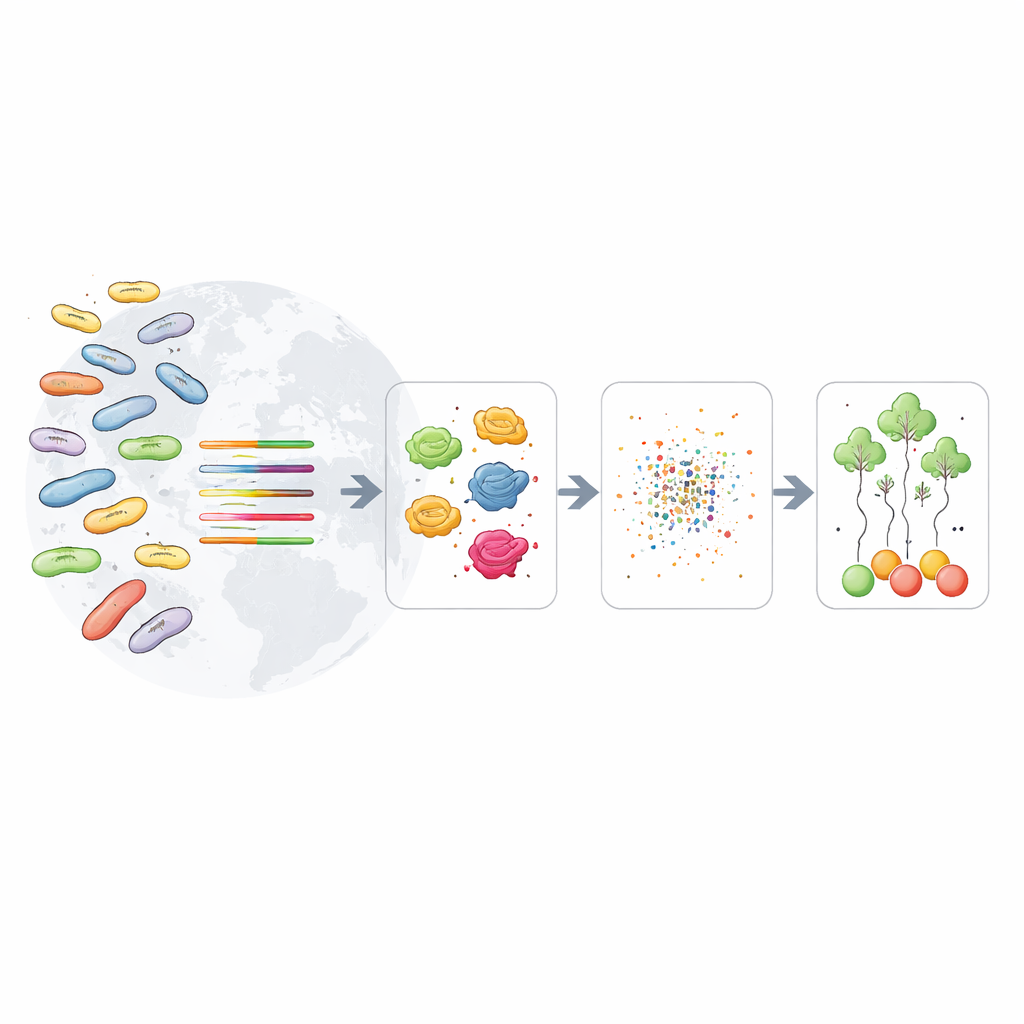
Поиск наиболее показательных генетических подсказок
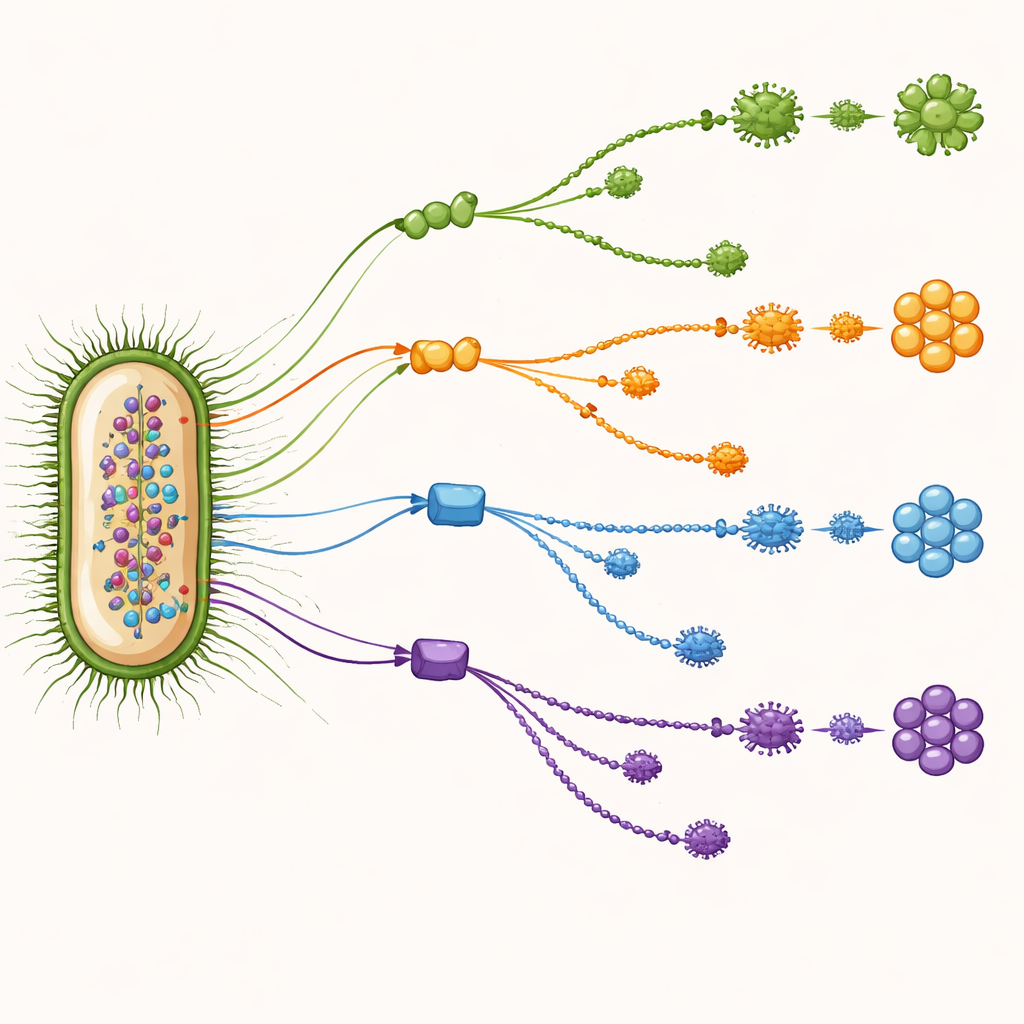
Просканировав тысячи семейств генов по одному, команда искала те, которые одновременно широко встречаются в геномах и дают много информации для различения O-серотипов. Этот поиск, управляемый данными, выделил девять ключевых генов. Некоторые уже были известны как участники сборки или формирования сахарного покрытия клетки, включая гены, участвующие в создании слизистой капсулы, и те, что контролируют длину сахарных цепочек. Другие были «домашними» генами, более известными ролями, например в синтезе аминокислот, но их последовательности оказались различными таким образом, что они плотно коррелировали с O-типом. В совокупности эти маркеры действовали как панель взаимодополняющих подсказок: когда один ген был менее надёжен для конкретного O-типа, другой часто заполнял пробел.
Лучше традиционных инструментов, особенно для редких типов
Используя только отпечатки этих девяти маркерных генов, метод машинного обучения Random Forest достиг примерно 93-процентной точности в классификации O-типов — выше, чем у широко применяемых референсных инструментов. Традиционные методы склонны к осторожности: когда они дают ответ, он обычно верен, но они часто не классифицируют необычные или слабо представленные типы вовсе. Новая модель, напротив, сохраняла высокую эффективность даже для редких O-типов с небольшим числом примеров в наборе данных. Подробные сравнения показали, что она способна помечать типы, которые старые методы полностью пропускали, делая производительность более сбалансированной как для общих, так и для редких штаммов.
Что это значит для отслеживания и предотвращения заболеваний
Говоря просто, исследование показывает, что позволив ИИ «читать» последовательности белков, можно раскрыть тонкие закономерности, помогающие отделять один тип E. coli от другого без сильной зависимости от идеальных совпадений с существующими базами данных. Авторы подчёркивают, что их маркеры требуют подтверждения в лаборатории и что метод лучше подходит для масштабного эпиднадзора, а не для диагностики у постели больного, но это даёт мощный новый инструмент для быстрой проверки огромных коллекций геномов. По мере того как секвенирование геномов становится стандартом в больницах и лабораториях по безопасности пищи, такие модели, учитывающие белковые признаки, могут облегчить обнаружение новых вариантов, уточнение вакцин и лучшее понимание того, почему одни штаммы E. coli становятся смертельно опасными, а другие остаются безвредными.
Цитирование: Jeong, H., Shin, H.D., Jung, J. et al. Data-driven classification of Escherichia coli using protein language model ascertains O-serotype determining genes. Sci Rep 16, 14232 (2026). https://doi.org/10.1038/s41598-026-40783-1
Ключевые слова: серотипирование E. coli, языковая модель белков, бактериальная геномика, машинное обучение в микробиологии, эпиднадзор