Clear Sky Science · ja
タンパク質言語モデルを用いたデータ駆動型の大腸菌分類がO型を決定する遺伝子を確定する
日常の健康にとってなぜ重要か
Escherichia coli、いわゆるE. coliと聞くと、多くの人は食中毒や汚染水を思い浮かべます。しかしすべてのE. coliが危険というわけではなく、有害な株であっても感染の広がり方や引き起こす病状に影響する微妙に異なる「型」が多数存在します。本研究は、本来タンパク質の理解を目的に開発された人工知能技術が、従来の手法で見落とされがちな希少型を含め、これらの菌型をより正確かつ公平に分類できることを示しています。これにより、アウトブレイクの追跡が迅速になり、ワクチン設計にも有益な情報が得られる可能性があります。
多様な顔を持つ病原体としての理解
医師や微生物学者はE. coliを「血清型」に分類します。これは細胞表面を覆う糖鎖によって作られるさまざまな“顔”のようなものです。特に重要なのがO抗原と呼ばれる被覆成分で、株ごとに大きく異なり、180種類以上が知られています。患者や食品サンプルにどのO型が存在するかを同定することは、感染源の追跡や過去のアウトブレイクとの関連付けに役立ちます。現在、検査室では通常、抗体と混ぜて凝集を観察する方法か、DNAを参照ライブラリと比較する方法が使われますが、変わった株や遺伝子が微妙に異なる場合、あるいは参照データベースが不完全な場合にはこれらの手法が苦戦することがあります。
コンピュータにタンパク質を“読ませる”
研究者たちは言語技術に着想を得た別のアプローチをとりました。現代の「タンパク質言語モデル」は、文章モデルが文から学ぶのと同じように、何百万ものタンパク質配列からパターンを学習します。本研究では、そのようなモデルの一つであるESM-2を用い、各細菌タンパク質を生化学的・進化的特徴を捉えた数値的な指紋(短いベクトル)に変換しました。公開データベースから得た11,000を超えるよく注釈されたE. coliゲノムを用い、関連する遺伝子をファミリーごとにまとめてタンパク質を指紋化し、これらのパターンから直接O型を予測するよう機械学習アルゴリズムを訓練しました。従来の単純なDNA一致による手法とは異なるアプローチです。
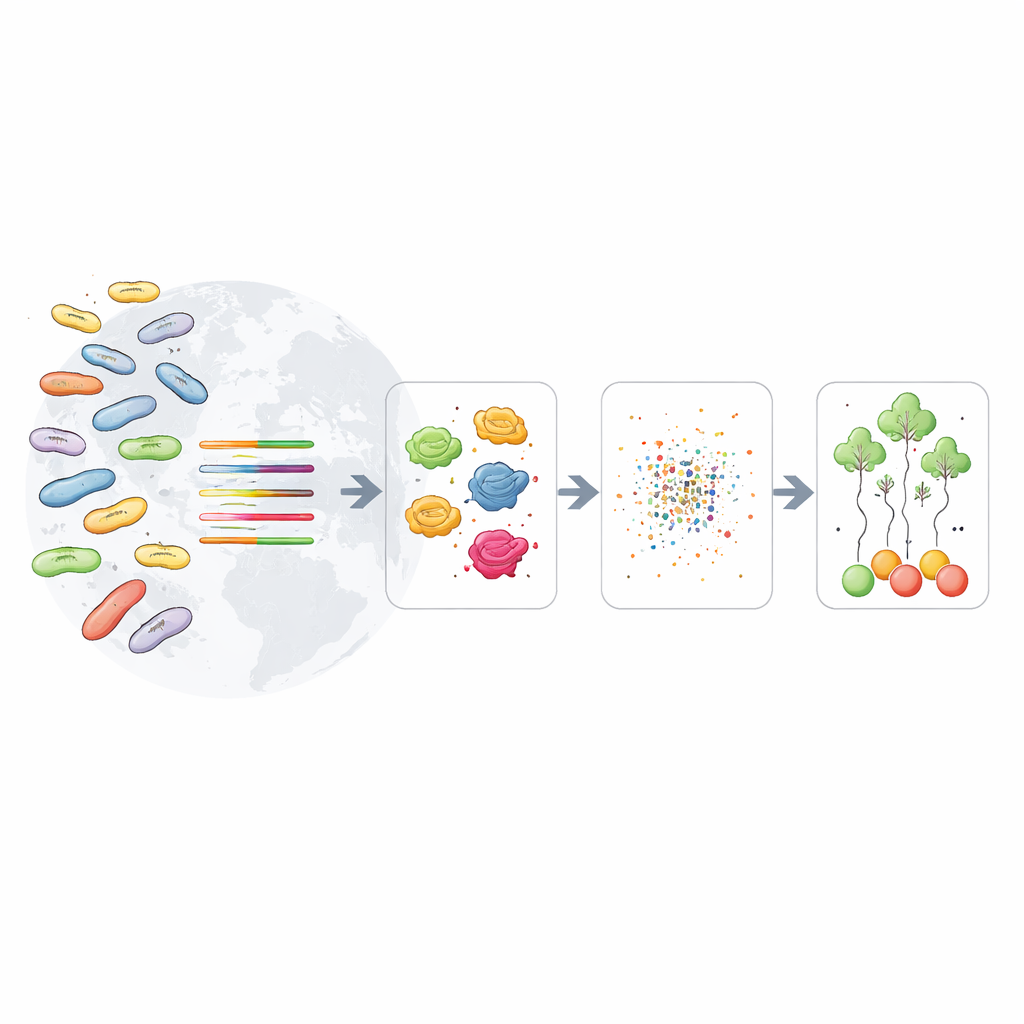
最も手がかりになる遺伝子を見つける
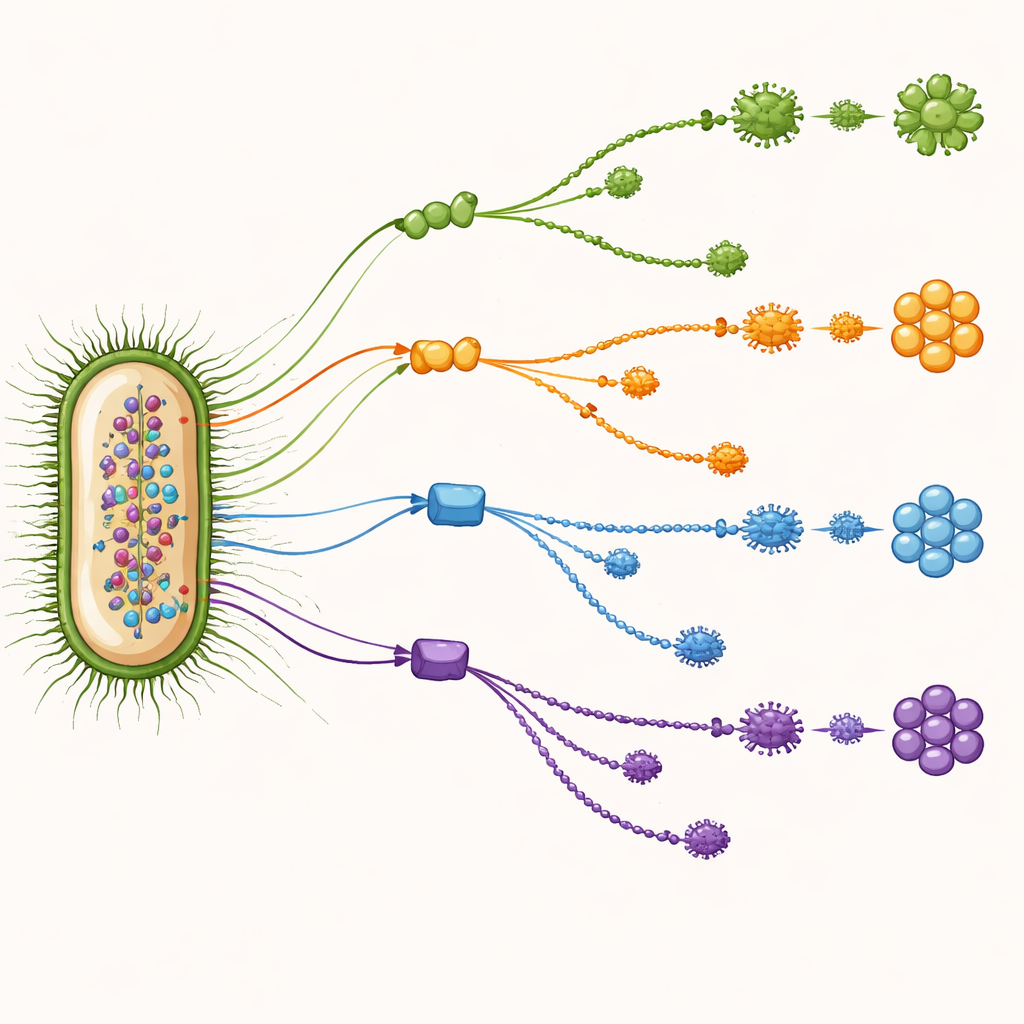
研究チームは数千の遺伝子ファミリーを順にスキャンし、多くのゲノムに共通しつつO型の識別に有益なものを探しました。このデータ駆動の探索により、特に有力な9つの遺伝子が浮かび上がりました。中には細胞表面の糖被覆の合成や形作りに既に関与が知られている遺伝子(粘性カプセルの組み立てに関与する遺伝子や糖鎖の長さを制御する遺伝子など)もありました。一方で、アミノ酸生合成などのハウスキーピング機能で知られる遺伝子も含まれており、これらの配列がO型と密接に対応する違いを示すことが分かりました。これらのマーカーは相補的な手がかりのパネルとして機能し、ある遺伝子が特定のO型では信頼できない場合でも、別の遺伝子がその穴を埋めることがよくありました。
特に希少型で従来ツールを上回る性能
これら9つのマーカー遺伝子から得た指紋だけを用いて、Random Forestと呼ばれる機械学習手法がO型分類で約93%の精度に到達しました。これは広く使われている参照ベースのツールより高い結果です。従来ツールは一般に慎重で、回答を出した場合はたいてい正しかったものの、変わった型やデータセットで少数しか存在しない型については分類できないことが多かったのです。新しいモデルはこれに対し、データ中で例が少ない希少なO型に対しても強い性能を維持しました。詳細な比較により、古い手法が完全に見落としていた型を新たに検出できることが示され、一般的な株とあまり見られない株の双方で性能がより均衡していることが示されました。
感染の追跡と予防にとっての意義
簡潔に言えば、本研究はAIにタンパク質配列を“読ませる”ことで、既存データベースとの完全一致に過度に依存せずに微妙なパターンを明らかにし、E. coliの型を分けるのに役立つことを示しています。著者らは、これらのマーカーは依然として実験室での確認が必要であり、この手法は病床での診断よりも大規模な監視に向いていると強調していますが、大量のゲノムコレクションを迅速にスキャンする強力な新しい手段を提供します。ゲノム配列解析が病院や食品安全のラボで標準となるにしたがい、このようなタンパク質を考慮するモデルは、新たに出現する変異株の検出、ワクチンの改良、あるE. coli株がなぜ致死的になるのか、あるいは無害のままでいるのかをより深く理解するのに役立つでしょう。
引用: Jeong, H., Shin, H.D., Jung, J. et al. Data-driven classification of Escherichia coli using protein language model ascertains O-serotype determining genes. Sci Rep 16, 14232 (2026). https://doi.org/10.1038/s41598-026-40783-1
キーワード: 大腸菌血清型判定, タンパク質言語モデル, 細菌ゲノミクス, 微生物学における機械学習, 疫学的監視