Clear Sky Science · en
Data-driven classification of Escherichia coli using protein language model ascertains O-serotype determining genes
Why this matters for everyday health
When people hear about Escherichia coli, or E. coli, they often think of food poisoning outbreaks and contaminated water. But not all E. coli are dangerous, and even harmful strains come in many subtly different “types” that affect how they spread and how sick they make us. This study shows how an artificial intelligence technique originally built to understand proteins can sort these bacterial types more accurately and fairly, especially the rare ones that traditional tools often miss. That could make tracking outbreaks faster and vaccine design more informed.
Seeing germs as many different faces
Doctors and microbiologists divide E. coli into “serotypes,” which are like different faces made from sugars coating the cell’s surface. One important part of this coating, called the O-antigen, varies a lot between strains—over 180 known varieties. Identifying which O-type is present in a patient or food sample helps trace where an infection came from and whether it is linked to past outbreaks. Today, labs usually do this either by mixing bacteria with antibodies and watching for clumping, or by comparing their DNA to reference libraries. But these methods can struggle when a strain is unusual, its genes are slightly different, or the reference databases are incomplete.
Teaching a computer to read proteins
The researchers took a different approach inspired by language technology. Modern “protein language models” learn patterns from millions of protein sequences, much like text models learn from written sentences. Here, they used one such model, ESM-2, to turn each bacterial protein into a numerical fingerprint—a short vector that captures its biochemical and evolutionary quirks. Using more than 11,000 well-characterized E. coli genomes from a public database, they grouped related genes into families, converted their proteins into these fingerprints, and then trained machine-learning algorithms to predict the O-type directly from these patterns rather than from simple DNA matching.
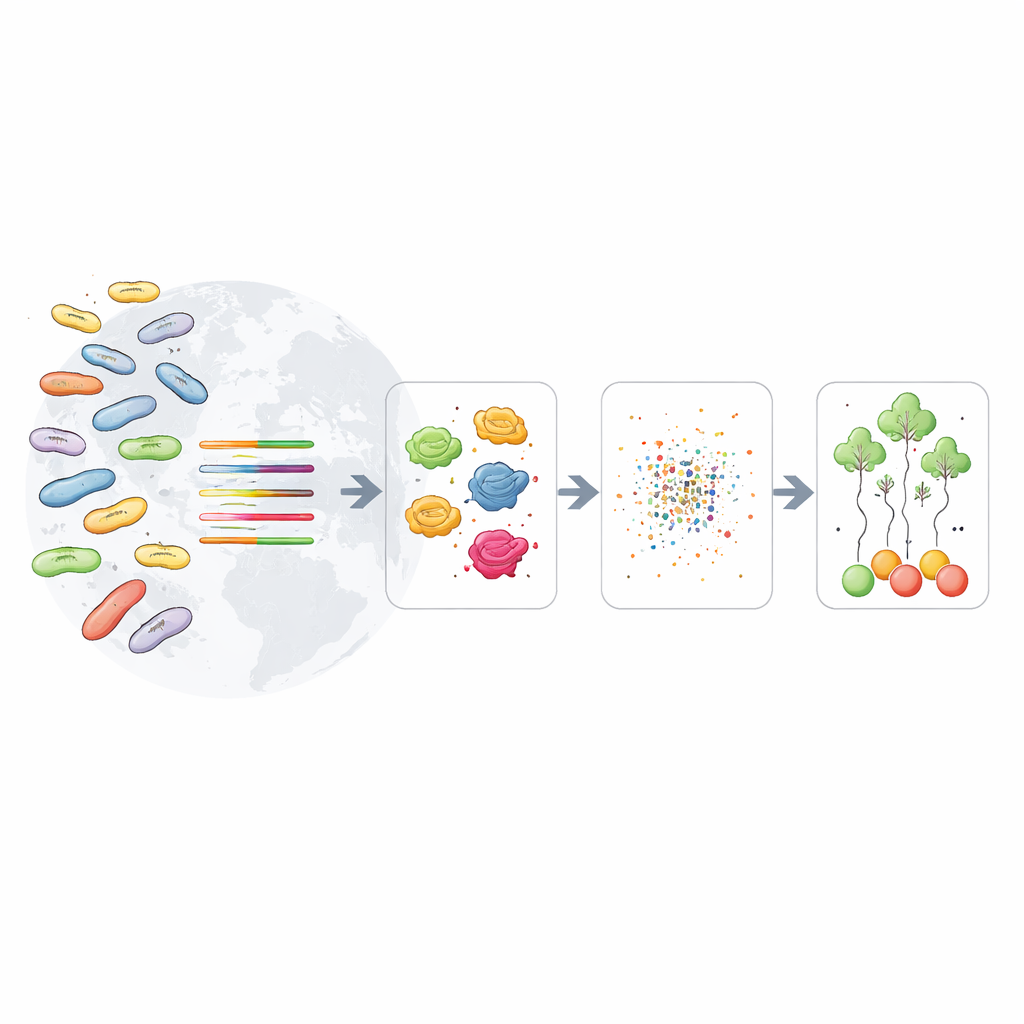
Finding the most telling genetic clues
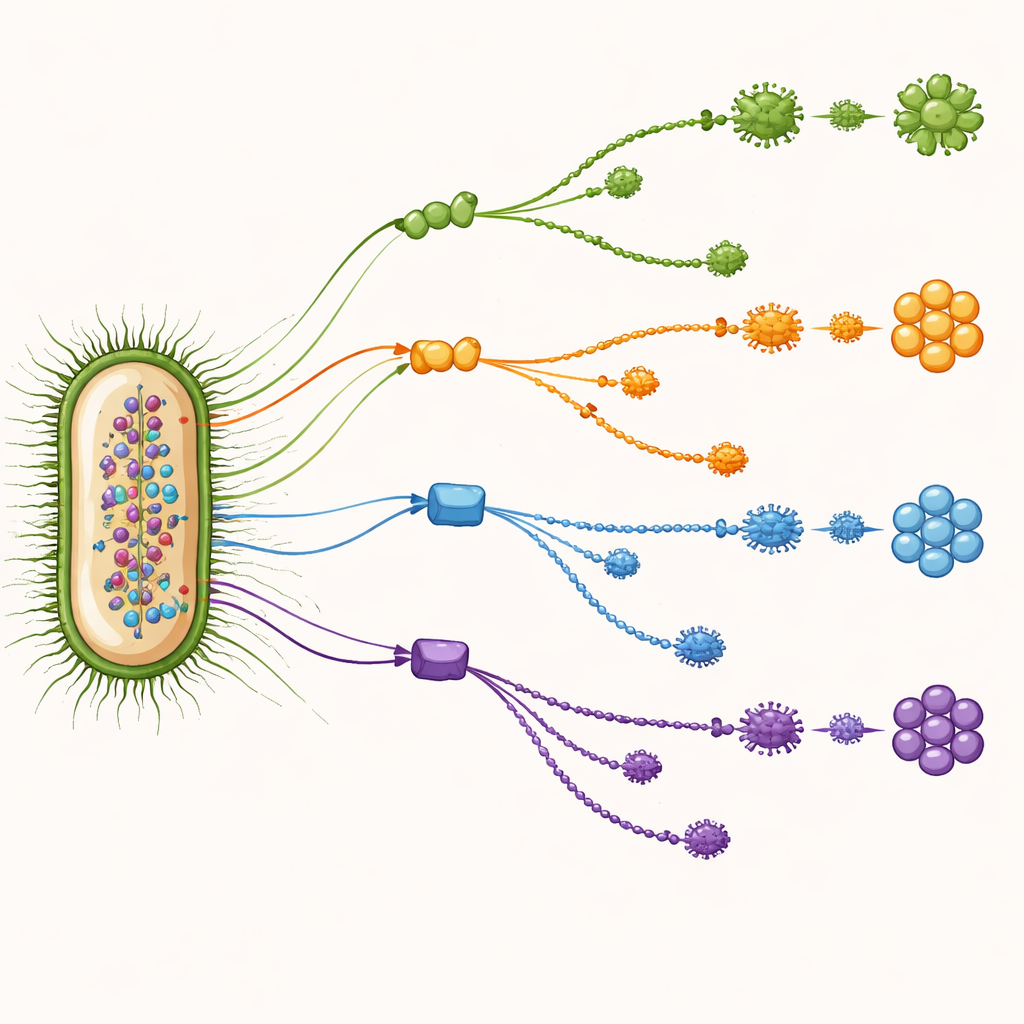
By scanning thousands of gene families one by one, the team searched for those that were both common across many genomes and highly informative for telling O-types apart. This data-driven hunt highlighted nine standout genes. Some were already known to help build or shape the sugar coat on the cell surface, including genes that help assemble a slimy protective capsule and those that control the length of the sugar chains. Others were housekeeping genes better known for roles such as amino acid production, but whose sequences turned out to differ in ways that track closely with O-type. Together, these markers acted like a panel of complementary clues: when one gene was less reliable for a particular O-type, another often filled the gap.
Outperforming traditional tools, especially for rare types
Using only the fingerprints from these nine marker genes, a machine-learning method called Random Forest reached about 93 percent accuracy in classifying O-types—higher than widely used reference-based tools. Traditional tools tended to be very cautious: when they gave an answer it was usually right, but they often failed to classify unusual or underrepresented types at all. The new model, in contrast, maintained strong performance even on rare O-types that had few examples in the dataset. Detailed comparisons showed it could successfully flag types that the older methods completely missed, making its performance more balanced across both common and uncommon strains.
What this means for tracking and preventing disease
Put simply, the study shows that letting an AI “read” protein sequences can reveal subtle patterns that help separate one E. coli type from another, without depending so heavily on perfect matches to existing databases. While the authors stress that their markers still need laboratory confirmation and that the method is best suited for large-scale surveillance rather than bedside diagnosis, it offers a powerful new way to scan huge genome collections quickly. As genome sequencing becomes standard in hospitals and food-safety labs, such protein-aware models could make it easier to spot emerging variants, refine vaccines, and better understand why some E. coli strains turn deadly while others remain harmless.
Citation: Jeong, H., Shin, H.D., Jung, J. et al. Data-driven classification of Escherichia coli using protein language model ascertains O-serotype determining genes. Sci Rep 16, 14232 (2026). https://doi.org/10.1038/s41598-026-40783-1
Keywords: E. coli serotyping, protein language model, bacterial genomics, machine learning in microbiology, epidemiological surveillance