Clear Sky Science · pt
Redes adversariais generativas multimodais para correção de dedilhado ao piano e modelagem da expressividade de performance por fusão de recursos áudio-visuais
Prática mais inteligente para pianistas do dia a dia
Aprender piano geralmente significa anos de aulas com um professor atento que escuta cada nota e observa todo movimento das mãos. Esta pesquisa explora como a inteligência artificial pode compartilhar parte dessa carga, transformando um piano comum, um microfone e uma câmera em um treinador digital que identifica dedilhados desconfortáveis e execução mecânica e monótona, oferecendo correções suaves quase em tempo real. 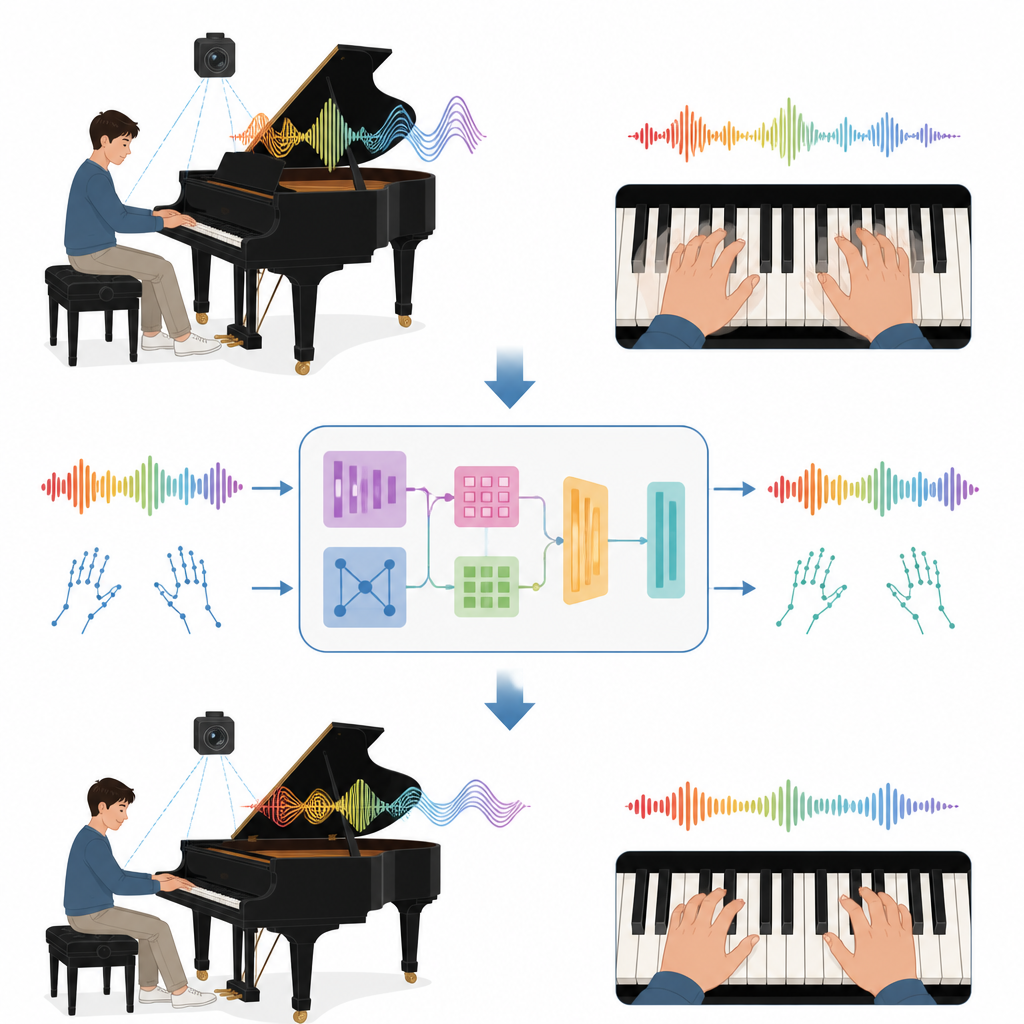
Por que observar importa tanto quanto ouvir
A maior parte dos softwares musicais foca apenas no som, julgando quais notas você acertou e quão preciso é o seu ritmo. Professores humanos, em contraste, se importam igualmente com como você se move: qual dedo você escolhe, como o pulso se desloca sobre as teclas e como o toque molda o timbre. Os autores argumentam que um assistente de piano útil precisa fazer ambos ao mesmo tempo. O sistema deles escuta o áudio enquanto também analisa o vídeo das mãos, aprendendo como gestos físicos e sons resultantes se alinham. Essa visão dupla permite ao computador notar, por exemplo, quando você toca a nota correta, mas usa um dedo desconfortável que pode limitar velocidade, conforto ou expressão no futuro.
Como o treinador digital vê e ouve você
Nos bastidores, o sistema divide som e vídeo em fatias minúsculas e então aprende padrões ao longo do tempo. Do áudio, ele extrai impressões digitais ricas de cada instante, capturando altura, intensidade e brilho do timbre. Do vídeo, rastreia as posições de 21 pontos em cada mão, seguindo como os dedos se deslocam sobre o teclado. Uma etapa especial de alinhamento liga o som de cada nota ao instante em que um dedo pressiona a tecla. Um módulo central de "fusão" então decide quanto confiar em cada fonte a cada momento, dando mais peso à câmera quando as mãos estão claras, ou ao som quando os dedos estão escondidos ou o vídeo está ruidoso. Essa imagem combinada torna-se a melhor estimativa do sistema sobre o que o intérprete está realmente fazendo. 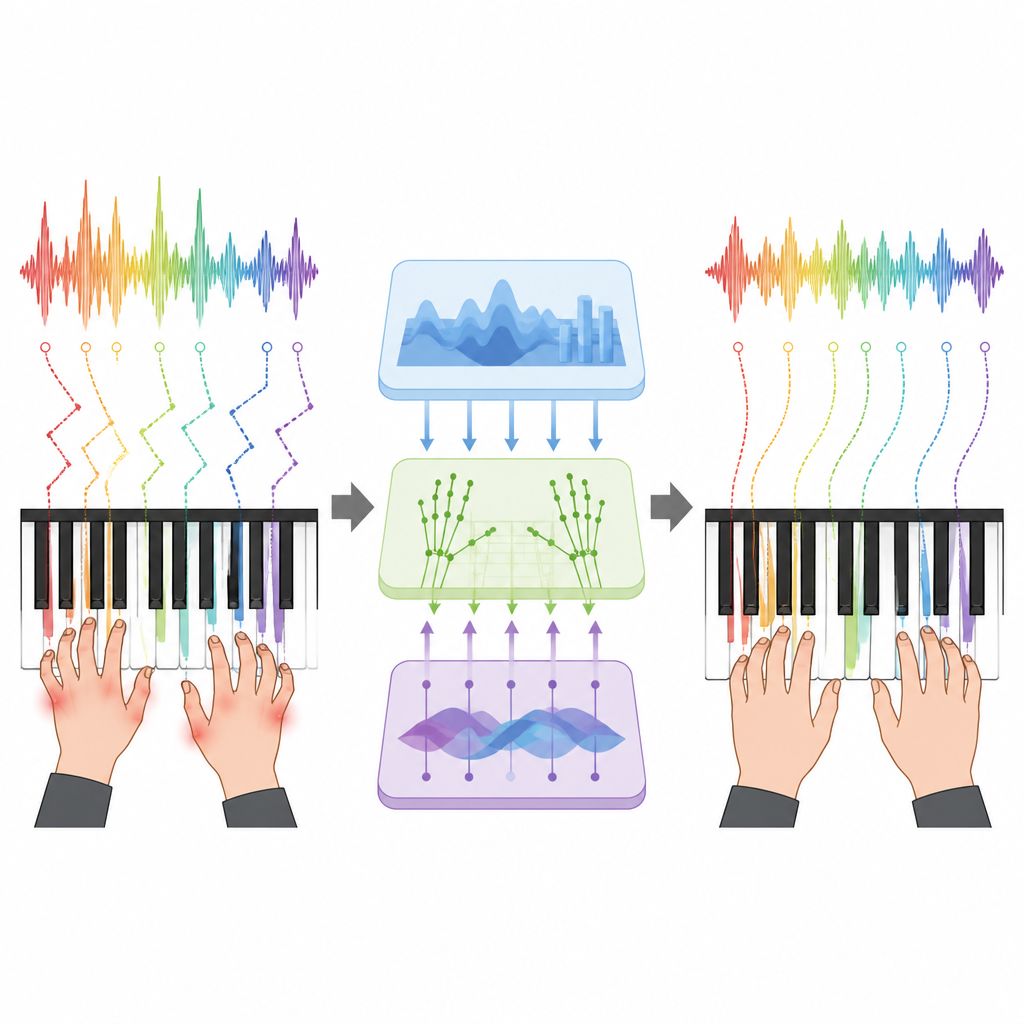
Ensinando um dedilhado melhor e uma execução mais expressiva
Para transformar esse entendimento em ajuda para estudantes, os autores constroem um modelo generativo que faz mais do que rotular certo e errado. Em vez de escolher um único número de dedo "correto", ele aprende a gama de dedilhados que pianistas especialistas usam para um trecho, levando em conta conforto e fluxo musical. Em testes com uma grande coleção de 3.847 performances gravadas, o sistema correspondeu às escolhas de dedilhado de especialistas em quase 90% das vezes no nível de notas individuais e se manteve próximo mesmo em frases longas e difíceis. Ao mesmo tempo, estudou aspectos da expressão, como flexibilidade de tempo, mudanças de intensidade e diferenças sutis de timbre, aprendendo a prever como avaliadores especialistas classificariam a vivacidade de uma performance, com fortes correlações aos escores humanos.
Do protótipo de laboratório ao assistente da sala de prática
Como os algoritmos são eficientes, eles podem processar cerca de um segundo de música em menos de dois décimos de segundo, rápido o suficiente para fornecer feedback ao final de cada frase durante a prática real. Os autores testaram várias formas de apresentar essa orientação, desde sinais simples por cores sobre postura até diagramas mais detalhados mostrando mudanças sugeridas de dedos e como moldar um crescendo ou relaxar um tempo excessivamente rígido. Professores que revisaram as sugestões do sistema julgaram a maioria delas não apenas fisicamente praticável, mas também musicalmente sensata, embora tenham observado que a ferramenta às vezes recomenda soluções avançadas que podem ser desafiadoras para iniciantes.
O que isso significa para o aprendizado musical futuro
O estudo mostra que, ao observar e ouvir conjuntamente, um computador pode capturar parte do vínculo sutil entre como um pianista se move e como a música é sentida. Embora não substitua um mentor humano e ainda tenha dificuldades fora de condições controladas de gravação, a abordagem aponta para ferramentas de prática amplamente acessíveis que oferecem conselhos personalizados de dedilhado e empurrões suaves rumo a uma execução mais expressiva. Para estudantes sem acesso regular a professores especializados, tais sistemas podem tornar a prática mais informada, mais segura para as mãos e mais recompensadora musicalmente.
Citação: Li, J. Multimodal generative adversarial networks for piano fingering correction and performance expressiveness modeling through audio-visual feature fusion. Sci Rep 16, 15076 (2026). https://doi.org/10.1038/s41598-026-44473-w
Palavras-chave: dedilhado de piano, educação musical, aprendizado áudio-visual, expressividade na performance, redes adversariais generativas