Clear Sky Science · pt
Melhorando a detecção de fraude com cartão de crédito com uma abordagem híbrida usando machine e deep learning
Por que isso importa para sua carteira
Cada vez que você aproxima seu cartão ou faz compras online, começa uma corrida silenciosa: os computadores do seu banco conseguem identificar um fraudador antes que seu dinheiro desapareça? À medida que os pagamentos digitais explodem no mundo inteiro, os criminosos inventam constantemente novos golpes, e segurança baseada em regras simples (como “bloquear todas as transações acima de R$5.000 à noite”) já não é suficiente. Este estudo mostra como combinar vários tipos de inteligência artificial em um único “time de especialistas” pode detectar quase todas as transações fraudulentas em um conjunto de dados real amplamente utilizado, ao mesmo tempo em que explica por que o sistema tomou cada decisão.
A maré crescente de artifícios digitais
A fraude com cartão de crédito é um negócio de grande escala. As perdas globais já chegam a dezenas de bilhões de dólares por ano e devem continuar crescendo com a expansão do e‑commerce, bancos online e pagamentos sem dinheiro. A maioria das transações é perfeitamente legítima, mas uma fração minúscula é fraudulenta — às vezes menos de duas em mil. Esse desequilíbrio torna o problema difícil: um sistema pode parecer muito preciso simplesmente classificando quase tudo como “normal” e ainda assim perder a maior parte das fraudes. Os autores focam nesse desequilíbrio e no fato de que as táticas de fraude continuam mudando, o que exige ferramentas flexíveis orientadas por dados em vez de regras rígidas escritas à mão.
Transformando fraudes raras em um sinal aprendível
Os pesquisadores começam com um conjunto real de transações de cartão de crédito europeias coletadas ao longo de dois dias: cerca de 285.000 pagamentos, dos quais apenas 492 são fraudulentos. Para evitar que o modelo seja sufocado pelos casos normais, eles usam uma técnica que fabrica exemplos extras realistas da classe rara, de modo que os dados fiquem mais balanceados. O método principal, chamado SMOTE, cria pontos sintéticos parecidos com fraudes entre casos reais de fraude. Eles também testam um método híbrido mais complexo que tanto adiciona exemplos minoritários quanto remove exemplos ruidosos da maioria. Ao escalar cuidadosamente valores e horários das transações e mantendo detalhes sensíveis ocultos por transformações matemáticas, eles preparam um conjunto de dados limpo e preservador da privacidade para que um computador possa aprender.
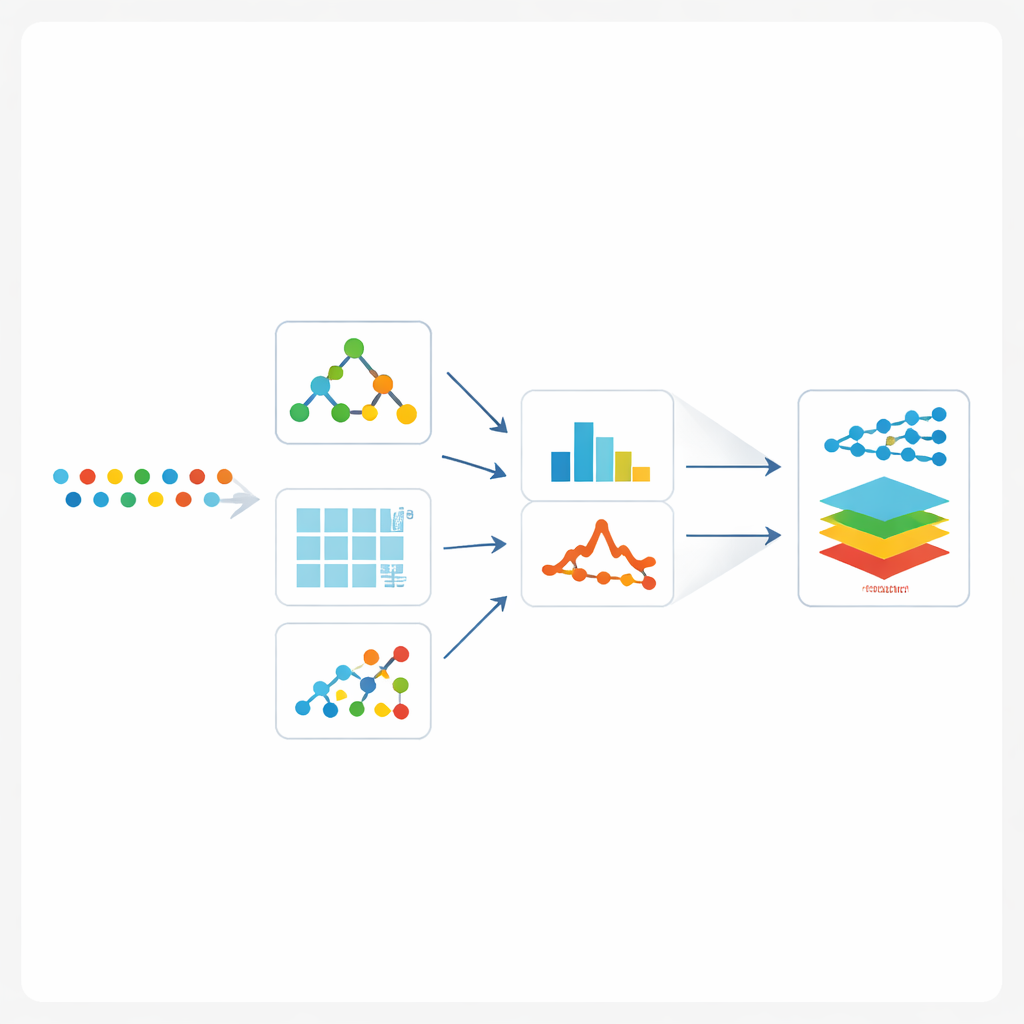
Construindo um time de caçadores digitais de fraude
Em vez de apostar em um único algoritmo, os autores treinam 37 modelos diferentes provenientes de machine learning clássico, árvores de decisão modernas com boosting e redes neurais profundas. Em seguida projetam dois “ensembles por empilhamento” especiais, que atuam como um painel de especialistas cujas opiniões são combinadas por um árbitro final. No primeiro ensemble, um modelo em árvore rápido, uma rede estilo imagem que detecta padrões e uma rede sensível a sequências estudam as mesmas transações. Suas saídas são então alimentadas em um modelo booster poderoso que aprende quanto confiar em cada especialista. O segundo ensemble combina vários tipos de boosters baseados em árvores e florestas em uma configuração em camadas semelhante. Ambos os ensembles são treinados primeiro nos dados originais desbalanceados e depois novamente na versão balanceada produzida pelo SMOTE e pelo método híbrido.
Detecção quase perfeita e o que isso custa
Nos dados balanceados criados com SMOTE, ambos os ensembles propostos alcançam pontuações surpreendentemente altas em todas as medidas padrão de sucesso: eles quase nunca deixam de identificar uma transação fraudulenta e quase nunca disparam um alarme falso em uma transação genuína neste conjunto de dados. Quando os autores comparam com muitos modelos individuais e com métodos publicados anteriormente que usaram os mesmos dados, seus sistemas empilhados consistentemente se destacam. Eles também medem o lado prático: quanto tempo o treinamento leva e quanta memória é necessária. O ensemble que se apoia fortemente em redes neurais profundas é mais custoso computacionalmente, enquanto o ensemble focado em árvores entrega precisão semelhante com demandas de tempo e memória substancialmente menores, tornando‑o mais atraente para sistemas bancários em tempo real.
Vendo dentro da caixa‑preta
Uma preocupação comum com IA avançada é que ela age como uma caixa‑preta: até mesmo seus projetistas podem não saber por que ela marcou sua compra como suspeita. Para lidar com isso, o estudo usa duas ferramentas de explicação que mostram quais características ocultas de uma transação importam mais para uma dada decisão e para o sistema como um todo. Análises visuais revelam um pequeno conjunto de variáveis transformadas que repetidamente impulsionam as previsões de fraude, enquanto muitas outras desempenham apenas um papel de apoio. Os autores também inspecionam onde os modelos ainda cometem erros, quão confiantes eles estão quando erram e quão bem os resultados se mantêm à medida que mais dados são usados. Essas verificações sugerem que os modelos estão genuinamente aprendendo padrões estáveis em vez de simplesmente memorizar os dados de treinamento.
O que isso significa para usuários comuns de cartão
Para não especialistas, a manchete é tranquilizadora: ao balancear os dados de forma inteligente e permitir que várias abordagens de IA trabalhem juntas, os bancos podem construir detectores de fraude que são tanto extremamente precisos em dados de referência quanto razoavelmente eficientes para operar. Igualmente importante, o sistema pode explicar suas decisões, o que ajuda as instituições a confiar e aperfeiçoá‑lo e ajuda reguladores a entender seu comportamento. Embora a implantação no mundo real ainda enfrente desafios — como táticas criminosas em constante evolução e a necessidade de atualizações rápidas e contínuas — essa abordagem híbrida oferece um roteiro robusto para manter seu cartão seguro sem inundá‑lo com falsos positivos.
Citação: Gamal, N., Younis, E.M.G. & Makram, W.M. Enhancing credit card fraud detection with a hybrid approach using machine and deep learning. Sci Rep 16, 10944 (2026). https://doi.org/10.1038/s41598-026-42891-4
Palavras-chave: detecção de fraude com cartão de crédito, machine learning, deep learning, modelos em ensemble, dados desbalanceados