Por que esta pesquisa importa para pacientes e médicos
Exames de sangue que medem anticorpos em pessoas com doença inflamatória intestinal (DII) são cada vez mais usados para ajudar a diagnosticar a condição, distinguir doença de Crohn de colite ulcerativa e até sugerir como a doença pode evoluir. Mas, na prática, muitas dessas medições sanguíneas estão ausentes porque as amostras são difíceis de coletar e os pacientes são difíceis de acompanhar ao longo do tempo. Este estudo faz uma pergunta aparentemente simples, mas com grandes consequências: quando peças-chave desses quebra‑cabeças de exames de sangue estão faltando, qual é a melhor maneira de preencher as lacunas para que médicos e pesquisadores ainda possam confiar nos resultados?
Buracos ocultos nos dados de exames sanguíneos
A DII, que inclui doença de Crohn e colite ulcerativa, é impulsionada por inflamação crônica no trato digestivo. Certos anticorpos no sangue — direcionados contra leveduras, bactérias e outros alvos — tornaram-se pistas poderosas para identificar DII, distinguir seus subtipos e às vezes prever a doença anos antes do aparecimento dos sintomas. No entanto, montar grandes conjuntos sorológicos com milhares de pacientes é complicado. Amostras podem ser perdidas, alguns testes podem falhar ou pacientes podem faltar às consultas. Correções rápidas e tradicionais, como excluir qualquer paciente com um valor ausente, desperdiçam informação e podem distorcer os resultados, fazendo com que doenças pareçam menos ou mais fortemente associadas a certos marcadores do que realmente são.
Diferentes maneiras pelas quais dados podem faltar
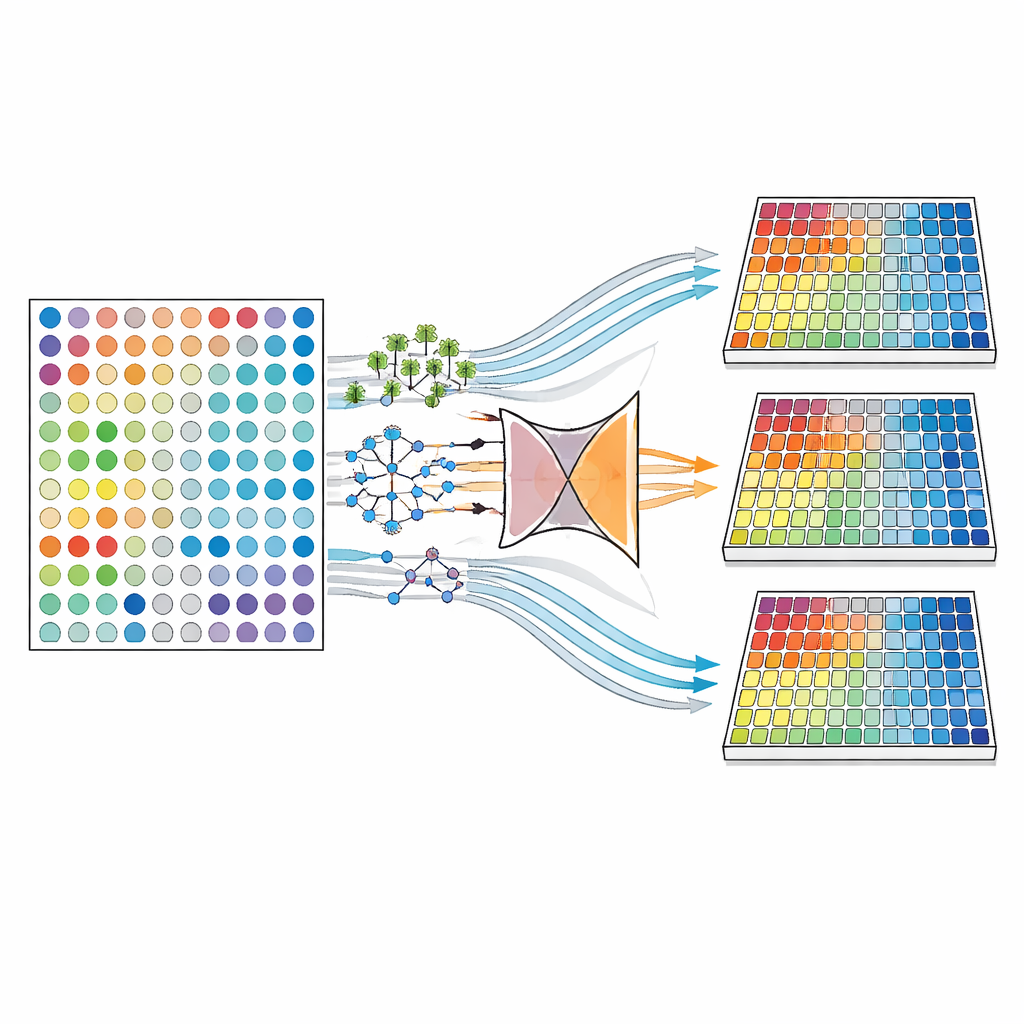
Os autores primeiro recriaram cuidadosamente as muitas formas pelas quais valores de exames sanguíneos podem estar ausentes. Em um cenário, os valores desaparecem completamente ao acaso, como lançamentos de moeda em uma tabela de dados. Em outro, os valores ausentes dependem de outras informações que vemos — por exemplo, pessoas com doença mais branda podem ter menos probabilidade de realizar certos testes. No cenário mais difícil, a ausência depende do próprio valor que não observamos — por exemplo, níveis de anticorpos muito altos ou muito baixos têm menos probabilidade de serem registrados. Usando três grandes coortes de DII, a equipe gerou milhares de versões de seus conjuntos de dados com quantidades variadas de informação ausente, de apenas 5% até robustos 40% das entradas de exames em branco.
Ferramentas modernas para preencher as lacunas
Em seguida, compararam famílias de métodos computacionais para preencher as lacunas — uma abordagem conhecida como imputação. Alguns métodos, como MICE (Multiple Imputation by Chained Equations) e os “imputadores iterativos” relacionados, preveem repetidamente cada valor ausente a partir dos demais, ciclando até que toda a tabela esteja preenchida. Outros usam motores de aprendizado de máquina mais flexíveis, incluindo florestas aleatórias, métodos de vizinho mais próximo que emprestam informação de pacientes semelhantes, e modelos de deep learning chamados autoencoders e variational autoencoders, que aprendem resumos comprimidos dos dados e reconstróem peças ausentes a partir desses resumos. Para cada configuração, os pesquisadores criaram múltiplos conjuntos de dados completos para capturar incerteza e avaliaram o desempenho por três ângulos: quão próximos os números preenchidos estavam dos originais, quão bem testes estatísticos padrão recuperavam associações conhecidas entre doença e anticorpos, e quão acurados modelos preditivos podiam distinguir subtipos de DII.
O que funciona melhor em diferentes condições Figura 1.
Não surgiu um único método campeão universal. Quando apenas uma pequena fração dos dados estava ausente e as lacunas eram relativamente bem comportadas, métodos iterativos — especialmente aqueles baseados em regressão bayesiana, florestas aleatórias ou vizinhos mais próximos — tenderam a fornecer as reconstruções mais precisas e preservaram a força das associações observadas nos dados completos. À medida que mais valores desapareciam, especialmente sob padrões de ausência mais desafiadores, abordagens de deep learning baseadas em autoencoders tornaram-se cada vez mais atraentes. Esses modelos foram melhores em preservar a estrutura geral dos dados e manter o desempenho preditivo próximo ao que teria sido obtido com informação completa. Em todos os casos, simplesmente descartar casos incompletos teve desempenho pior: enfraqueceu sinais, reduziu o poder estatístico e não ofereceu vantagem no controle de erros de falso positivo.
Escolhendo a ferramenta certa para o trabalho Figura 2.
A conclusão do estudo é mais prática do que prescritiva. Para projetos onde a prioridade é uma inferência estatística sólida — como estimar quão fortemente um anticorpo específico está ligado à doença de Crohn — métodos que seguem princípios de imputação múltipla, como MICE e certos imputadores iterativos, são uma primeira escolha sensata. Eles combinam bem com regras estabelecidas para agregar resultados entre conjuntos imputados e fornecem estimativas de incerteza bem calibradas. Em contraste, quando o objetivo principal é predição — como treinar um modelo de aprendizado de máquina para classificar pacientes — imputadores iterativos e abordagens baseadas em autoencoders frequentemente se destacam, especialmente quando a parcela de valores ausentes é alta. Ao demonstrar que métodos diferentes se sobressaem sob níveis variados de ausência e objetivos de análise distintos, este trabalho oferece um roteiro para pesquisadores selecionarem estratégias de imputação que preservem tanto o sinal científico quanto a utilidade clínica dos dados sorológicos em DII.
O que isso significa em termos simples
Para pessoas que vivem com DII e para os clínicos e cientistas que cuidam delas, a mensagem é tranquilizadora, porém nuançada: mesmo quando registros de exames de sangue estão repletos de lacunas, métodos computacionais cuidadosamente escolhidos podem reconstruir o suficiente da imagem para manter as análises confiáveis. Não existe uma solução única para todos os casos, mas há padrões claros — métodos iterativos mais simples funcionam bem quando os dados estão majoritariamente completos, enquanto ferramentas de deep learning mais flexíveis são melhores quando os buracos são maiores e mais complexos. Usar essas abordagens em vez de descartar dados imperfeitos ajuda a proteger contra conclusões enganosas e apoia diagnósticos mais precisos, monitoramento da doença e pesquisas de tratamento baseadas em biomarcadores sorológicos.
Citação: Boodaghidizaji, M., McGovern, D.P.B. & Li, D. Imputation methods for serologic biomarkers in inflammatory bowel disease.
Sci Rep16, 11160 (2026). https://doi.org/10.1038/s41598-026-41587-z
Palavras-chave: doença inflamatória intestinal, biomarcadores sorológicos, dados ausentes, imputação múltipla, aprendizado de máquina