Clear Sky Science · ja
炎症性腸疾患の血清学的バイオマーカーに対する欠測値補完法
患者と医師にとってこの研究が重要な理由
炎症性腸疾患(IBD)の患者で抗体を測る血液検査は、疾患の診断、クローン病と潰瘍性大腸炎の識別、さらには病気の経過の示唆にますます利用されています。しかし現実の臨床データでは、試料の採取が難しいことや追跡が困難なことから、多くの血液測定値が欠損しています。本研究は一見単純だが影響の大きい問いを投げかけます:主要な血液検査の値が欠けているとき、医師や研究者が結果を信頼できるようにギャップを埋める最良の方法は何か?
血液検査データに潜む欠落
クローン病や潰瘍性大腸炎を含むIBDは消化管の慢性炎症によって駆動されます。酵母や細菌などを標的とする特定の血中抗体は、IBDの検出、サブタイプの識別、場合によっては症状が出る何年も前の予測に有力な手がかりとなります。しかし、何千人規模の血清データを集める作業は乱雑になりがちです。試料の紛失、検査の失敗、受診の欠如などが起きます。欠損値を含む患者を丸ごと除外するような従来の簡易的な対処は、情報を無駄にし、結果に偏りを生じさせ、特定のマーカーと疾患の関連を実際より弱くまたは強く見せてしまうことがあります。
データが欠けるさまざまなパターン
著者らはまず、血液検査の値が欠落する多様なあり得るパターンを精密に再現しました。一つのシナリオでは、値はデータ表全体でコイントスのように完全にランダムに消えます。別のシナリオでは、欠測は我々が観測する他の情報に依存します—例えば、症状が軽い人は特定の検査を受けない傾向があるかもしれません。最も扱いが難しいシナリオでは、欠測は観測されないその値そのものに依存します—例えば、極端に高いまたは低い抗体レベルが記録されにくい場合です。3つの大規模IBDコホートを用いて、研究チームは欠測率が5%から多くは40%に及ぶ、何千もの欠損データ版を生成しました。
ギャップを埋めるための現代的手法
つぎに彼らは欠損を埋める計算手法の系統(代入:imputation)を比較しました。MICE(Multiple Imputation by Chained Equations)やいわゆる「反復代入器」のような方法は、欠けている各値を他の値から繰り返し予測し、表全体が埋まるまでサイクルを回します。ほかにはより柔軟な機械学習エンジンを用いる手法もあり、ランダムフォレスト、類似患者から情報を借りるk近傍法、データの圧縮表現を学習してそこから欠損部分を再構成するオートエンコーダや変分オートエンコーダといった深層学習モデルが含まれます。各設定について、研究者は不確実性を捉えるために複数の完成データセットを作成し、(1)補完した数値が元の値にどれだけ近いか、(2)標準的な統計検定が既知の抗体—疾患の関係をどれだけ回復できるか、(3)予測モデルがIBDのサブタイプをどれだけ正確に識別できるか、の三つの観点で性能を評価しました。
異なる条件下で何が最も有効か
Figure 1.
万能の勝者となる手法はありませんでした。欠損が少なく、比較的穏やかなパターンであれば、ベイズ回帰、ランダムフォレスト、近傍法に基づく反復的手法が最も正確な再構築を行い、完全データで見られる関連の強さを保存する傾向がありました。欠損が増え、特により困難な欠測パターンが現れると、オートエンコーダに基づく深層学習アプローチの魅力が高まりました。これらのモデルはデータ全体の構造を保ち、予測性能を完全データで得られたものに近づけるのに優れていました。いずれの場合も、不完全な症例を単純に捨てる方法は成績が悪く、信号を弱め、統計的検出力を低下させ、偽陽性の制御に関しても利点を示しませんでした。
目的に合った道具の選び方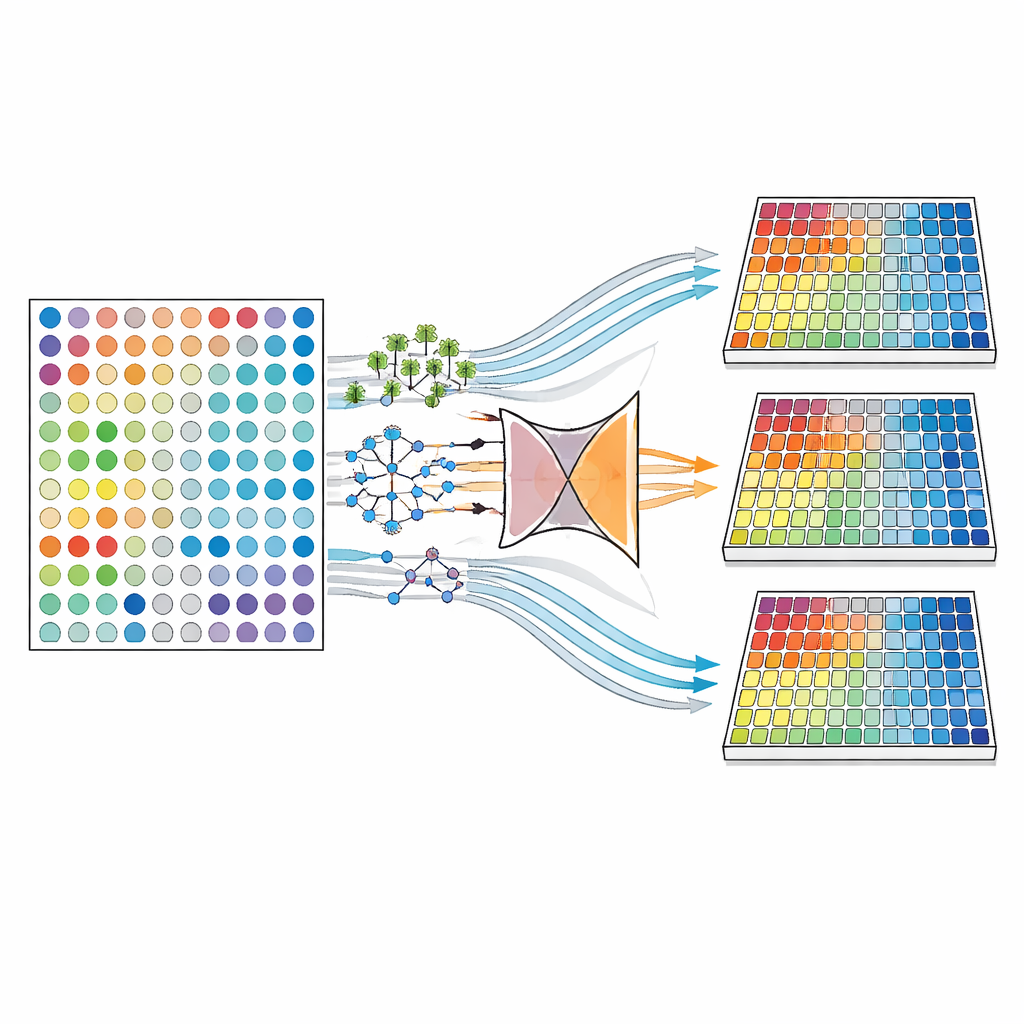
Figure 2.
研究の結論は処方的というより実用的です。特定の抗体がクローン病とどれほど強く関連しているかを推定するなど、統計学的推論が優先されるプロジェクトでは、MICEや一部の反復代入器のような多重代入の原則に従う方法が第一選択として妥当です。これらは代入後のデータセット間で結果を組み合わせる既存のルールと相性が良く、よく較正された不確実性推定を提供します。一方で、主要な目的が患者の分類などの予測である場合は、反復代入器やオートエンコーダベースの手法が、特に欠損率が高いときに優れることが多いです。異なる欠損レベルと解析目的で異なる方法が優れることを示すことで、本研究はIBDにおける血清学的データの科学的信号と臨床的有用性を保つための代入戦略の指針を提供します。
平たく言えば何を意味するか
IBDと向き合う患者や臨床医・研究者にとって、この結果は安心できるが一筋縄ではいかないメッセージを伝えます:血液検査の記録に穴が多くても、慎重に選ばれた計算手法を使えば解析の信頼性を保つのに十分な再構成が可能です。万能の解はありませんが明確な傾向があります—データがほぼ完全な場合は単純な反復的手法がよく機能し、穴が大きくより複雑な場合はより柔軟な深層学習ツールが有利です。これらのアプローチを不完全なデータを捨てる代わりに用いることで、誤った結論を避け、血清マーカーに基づくより正確な診断、疾患モニタリング、治療研究を支えることができます。
引用: Boodaghidizaji, M., McGovern, D.P.B. & Li, D. Imputation methods for serologic biomarkers in inflammatory bowel disease. Sci Rep 16, 11160 (2026). https://doi.org/10.1038/s41598-026-41587-z
キーワード: 炎症性腸疾患, 血清学的バイオマーカー, 欠損データ, 多重代入法, 機械学習