Por qué esta investigación importa para pacientes y médicos
Las pruebas de sangre que miden anticuerpos en personas con enfermedad inflamatoria intestinal (EII) se usan cada vez más para ayudar a diagnosticar la enfermedad, distinguir la enfermedad de Crohn de la colitis ulcerosa e incluso para insinuar cómo podría desarrollarse la enfermedad. Pero en el mundo real, muchas de estas mediciones sanguíneas faltan porque las muestras son difíciles de obtener y los pacientes son difíciles de seguir a lo largo del tiempo. Este estudio plantea una pregunta aparentemente simple con grandes consecuencias: cuando faltan piezas clave de ese rompecabezas de pruebas sanguíneas, ¿cuál es la mejor manera de rellenar los huecos para que los médicos e investigadores puedan seguir confiando en sus resultados?
Agujeros ocultos en los datos de las pruebas sanguíneas
La EII, que incluye la enfermedad de Crohn y la colitis ulcerosa, está impulsada por la inflamación crónica del tracto digestivo. Ciertos anticuerpos en la sangre — dirigidos contra levaduras, bacterias y otros objetivos — se han convertido en pistas poderosas para detectar la EII, distinguir sus subtipos y, a veces, predecir la enfermedad años antes de que aparezcan los síntomas. Sin embargo, reunir grandes conjuntos de datos serológicos de miles de pacientes es un proceso desordenado. Las muestras pueden perderse, algunas pruebas pueden fallar o los pacientes pueden faltar a las visitas. Las soluciones rápidas tradicionales, como descartar a cualquier paciente con un valor perdido, desperdician información y pueden sesgar los resultados, haciendo que las enfermedades parezcan menos o más fuertemente asociadas con ciertos marcadores de lo que realmente son.
Diferentes formas en que los datos pueden faltar
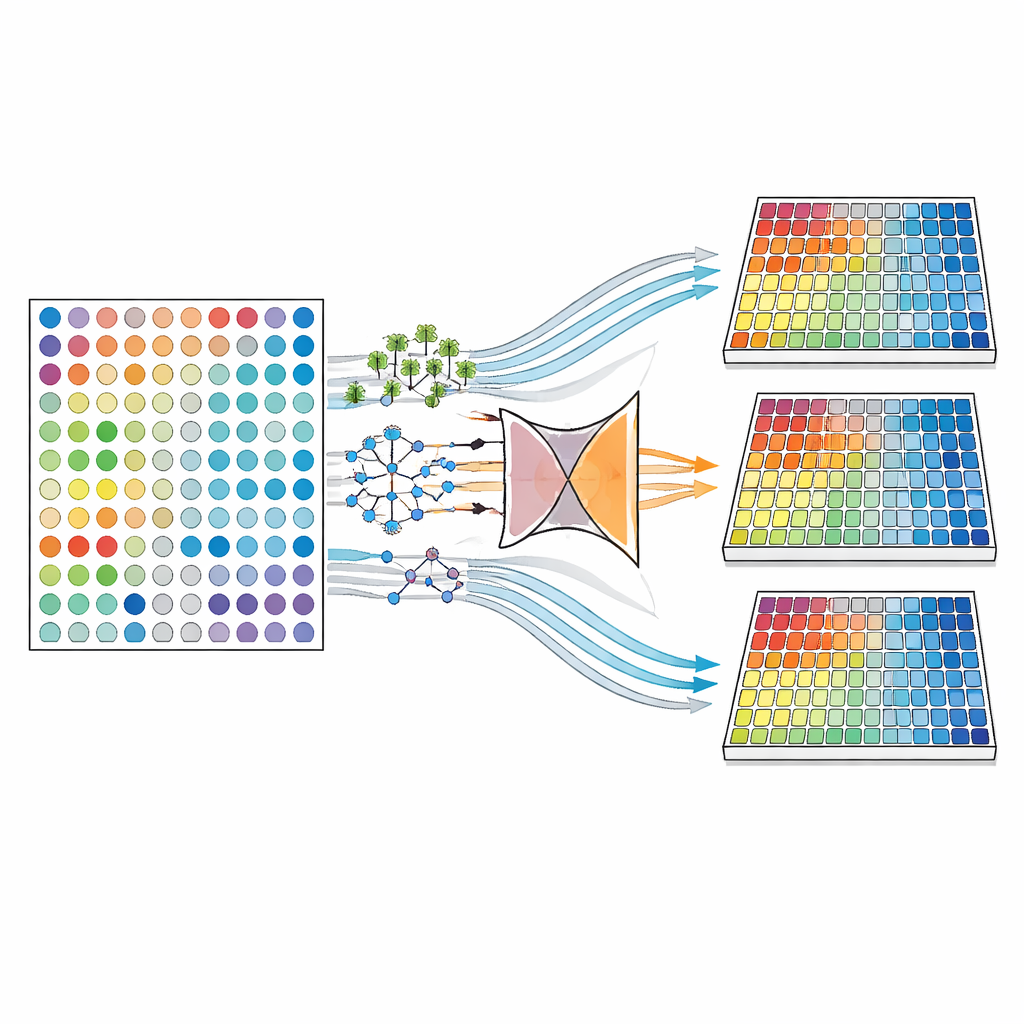
Los autores recrearon cuidadosamente las muchas formas en que pueden estar ausentes los valores de las pruebas sanguíneas. En un escenario, los valores desaparecen completamente al azar, como lanzamientos de moneda a lo largo de una tabla de datos. En otro, los valores faltantes dependen de otra información que sí observamos — por ejemplo, las personas con enfermedad más leve pueden tener menos probabilidades de hacerse ciertas pruebas. En el escenario más difícil, la ausencia depende del propio valor que no observamos — por ejemplo, niveles de anticuerpos extremadamente altos o bajos son menos propensos a registrarse. Usando tres grandes cohortes de EII, el equipo generó miles de versiones de sus conjuntos de datos con cantidades variables de información faltante, desde apenas un 5% hasta un contundente 40% de entradas de pruebas sanguíneas en blanco.
Herramientas modernas para rellenar los vacíos
Luego compararon familias de métodos computacionales para rellenar los huecos — un enfoque conocido como imputación. Algunos métodos, como MICE (Imputación Múltiple por Ecuaciones Encadenadas) y los «imputadores iterativos» relacionados, predicen repetidamente cada valor faltante a partir de los demás, ciclando hasta que toda la tabla queda completa. Otros usan motores de aprendizaje automático más flexibles, incluidos bosques aleatorios, métodos de vecinos más cercanos que toman información de pacientes similares, y modelos de aprendizaje profundo llamados autoencoders y autoencoders variacionales que aprenden resúmenes comprimidos de los datos y reconstruyen las piezas faltantes a partir de esos resúmenes. Para cada configuración, los investigadores crearon múltiples conjuntos de datos completos para capturar la incertidumbre y evaluaron el rendimiento desde tres ángulos: qué tan cercanos estaban los números imputados a los originales, qué tan bien las pruebas estadísticas estándar recuperaban los vínculos conocidos entre enfermedad y anticuerpos, y qué tan precisos eran los modelos predictivos para distinguir los subtipos de EII.
Qué funciona mejor en diferentes condiciones Figure 1.
No emergió un único método como campeón universal. Cuando solo faltaba una pequeña fracción de datos y los huecos eran bastante bien comportados, los métodos iterativos —especialmente los basados en regresión bayesiana, bosques aleatorios o vecinos más cercanos— tendían a ofrecer las reconstrucciones más precisas y preservaban la fuerza de las asociaciones observadas en los datos completos. A medida que más valores desaparecían, especialmente bajo patrones de ausencia más difíciles, los enfoques de aprendizaje profundo basados en autoencoders se volvieron cada vez más atractivos. Estos modelos eran mejores preservando la estructura global de los datos y manteniendo el rendimiento predictivo cerca de lo que se habría obtenido con información completa. En general, simplemente descartar casos incompletos tuvo un desempeño peor: debilitó las señales, redujo la potencia estadística y no ofreció ninguna ventaja en términos de control de errores de tipo I.
Elegir la herramienta adecuada para el trabajo Figure 2.
La conclusión del estudio es práctica más que prescriptiva. Para proyectos donde la prioridad es una inferencia estadística sólida —como estimar qué tan fuertemente un anticuerpo específico está ligado a la enfermedad de Crohn— los métodos que siguen principios de imputación múltiple, como MICE y ciertos imputadores iterativos, son una primera opción sensata. Se combinan bien con reglas establecidas para integrar resultados entre conjuntos de datos imputados y proporcionan estimaciones de incertidumbre bien calibradas. En contraste, cuando el objetivo principal es la predicción —por ejemplo, entrenar un modelo de aprendizaje automático para clasificar pacientes— los imputadores iterativos y los enfoques basados en autoencoders suelen destacar, particularmente cuando la proporción de valores faltantes es alta. Al mostrar que diferentes métodos sobresalen según los niveles de ausencia y los objetivos del análisis, este trabajo ofrece una hoja de ruta para que los investigadores seleccionen estrategias de imputación que preserven tanto la señal científica como la utilidad clínica de los datos serológicos en EII.
Qué significa esto en términos sencillos
Para las personas que viven con EII y los clínicos y científicos que las atienden, el mensaje es tranquilizador pero matizado: incluso cuando los registros de pruebas sanguíneas están plagados de lagunas, métodos computacionales cuidadosamente elegidos pueden reconstruir suficiente información como para mantener las análisis fiables. No existe una solución única para todo, pero hay patrones claros: métodos iterativos más simples funcionan bien cuando los datos están mayormente completos, mientras que herramientas de aprendizaje profundo más flexibles son mejores cuando los huecos son mayores y más complejos. Usar estos enfoques en lugar de desechar datos imperfectos ayuda a proteger frente a conclusiones engañosas y respalda diagnósticos, monitorización de la enfermedad e investigación de tratamientos más precisos basados en biomarcadores serológicos.
Cita: Boodaghidizaji, M., McGovern, D.P.B. & Li, D. Imputation methods for serologic biomarkers in inflammatory bowel disease.
Sci Rep16, 11160 (2026). https://doi.org/10.1038/s41598-026-41587-z