Clear Sky Science · pl
Postępy w przesiewaniu sercowo-naczyniowym: klasyfikacja dźwięków serca oparta na głębokim uczeniu z wykorzystaniem SMOTE i modelowania czasowego
Słuchanie serca w nowy sposób
Choroby serca są główną przyczyną zgonów na świecie, a jednak w wielu placówkach podstawowym narzędziem przesiewowym wciąż pozostaje ucho lekarza i prosty stetoskop. Subtelne dźwięki przypominające „szum”, zwane szmerami, mogą ostrzegać o groźnych problemach z zastawkami, ale łatwo je przeoczyć, szczególnie poza ośrodkami specjalistycznymi. W artykule badacze analizują, jak komputery mogą przetwarzać nagrane dźwięki serca, aby wykrywać szmery bardziej trafnie i konsekwentnie, co mogłoby przenieść poziom badań specjalistycznych do zatłoczonych przychodni i ośrodków o ograniczonych zasobach.
Dlaczego dźwięki serca są ważne
Każde uderzenie serca tworzy bogate brzmienie, gdy zastawki zamykają się, a krew przepływa przez serce. Lekarze uczą się interpretować te dźwięki przez lata praktyki, jednak nawet doświadczeni klinicyści mogą się nie zgadzać, a lekarze pierwszego kontaktu często przegapiają istotne sygnały. Jednocześnie choroby sercowo-naczyniowe powodują miliony zgonów rocznie, z których wiele można by zapobiec dzięki wcześniejszemu wykryciu. Cyfrowe mikrofony umożliwiają teraz łatwe nagrywanie dźwięków serca, ale zamiana tych fal na wiarygodne diagnozy wymaga inteligentnych algorytmów zdolnych poradzić sobie z hałasem, różnicami między pacjentami i rzadkimi, lecz krytycznymi wzorcami nieprawidłowości.
Przekształcanie surowych uderzeń w użyteczne wzorce
Badacze zbudowali etapowy proces przypominający sposób, w jaki ekspert mógłby słuchać, ale z precyzją maszyny. Najpierw automatycznie wykrywają kluczowe zdarzenia sercowe — główne piki „lub‑dub” — i dzielą nagranie na krótkie, jednosekundowe fragmenty wycentrowane na tych punktach. To zachowuje naturalny rytm cyklu sercowego. Następnie każdy fragment przekształcają w skondensowany opis jego wysokości i barwy dźwięku, stosując metodę pierwotnie inspirowaną ludzkim słuchem. Zamiast podawać do modelu surowy dźwięk, używają tych zdestylowanych wzorców jako wejścia, co ułatwia komputerowi skupienie się na medycznie istotnych różnicach między dźwiękami prawidłowymi a szmerami. 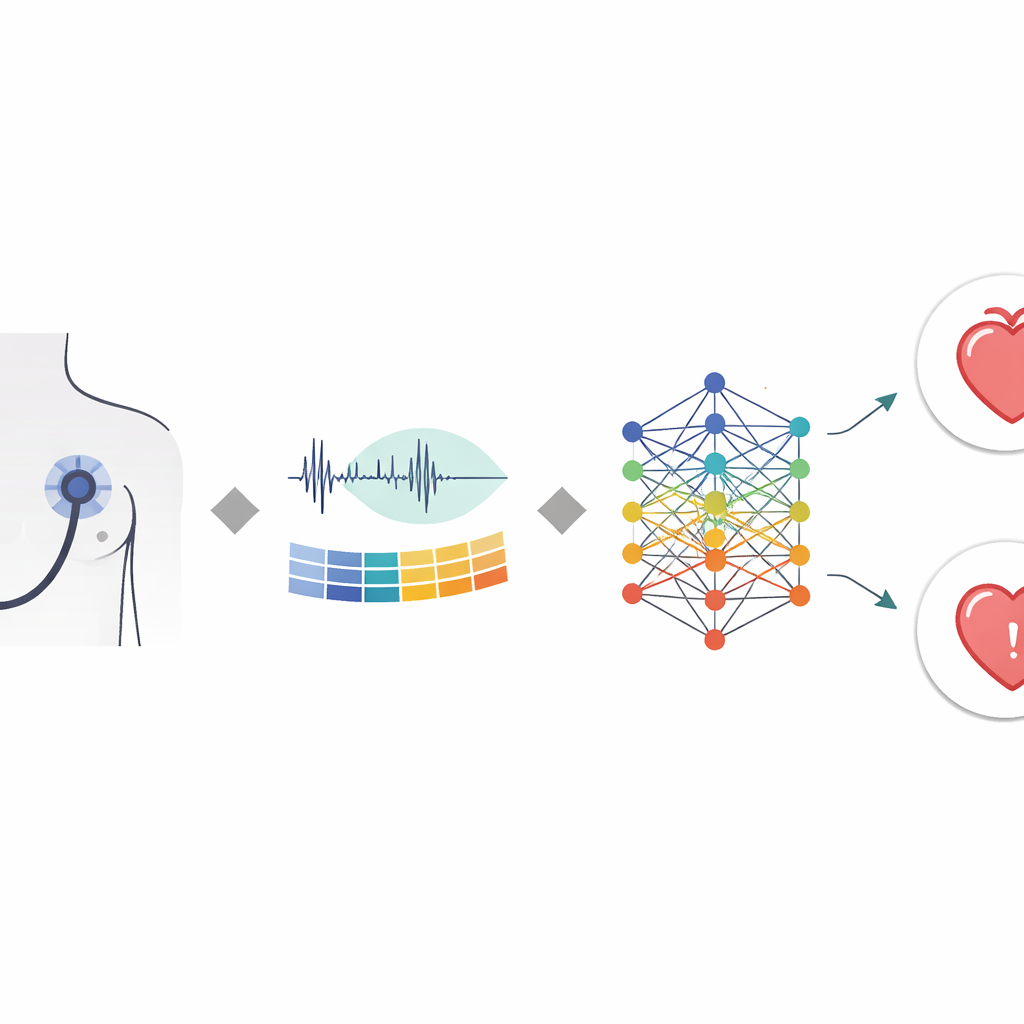
Równoważenie rzadkich szmerów i uczenie się w czasie
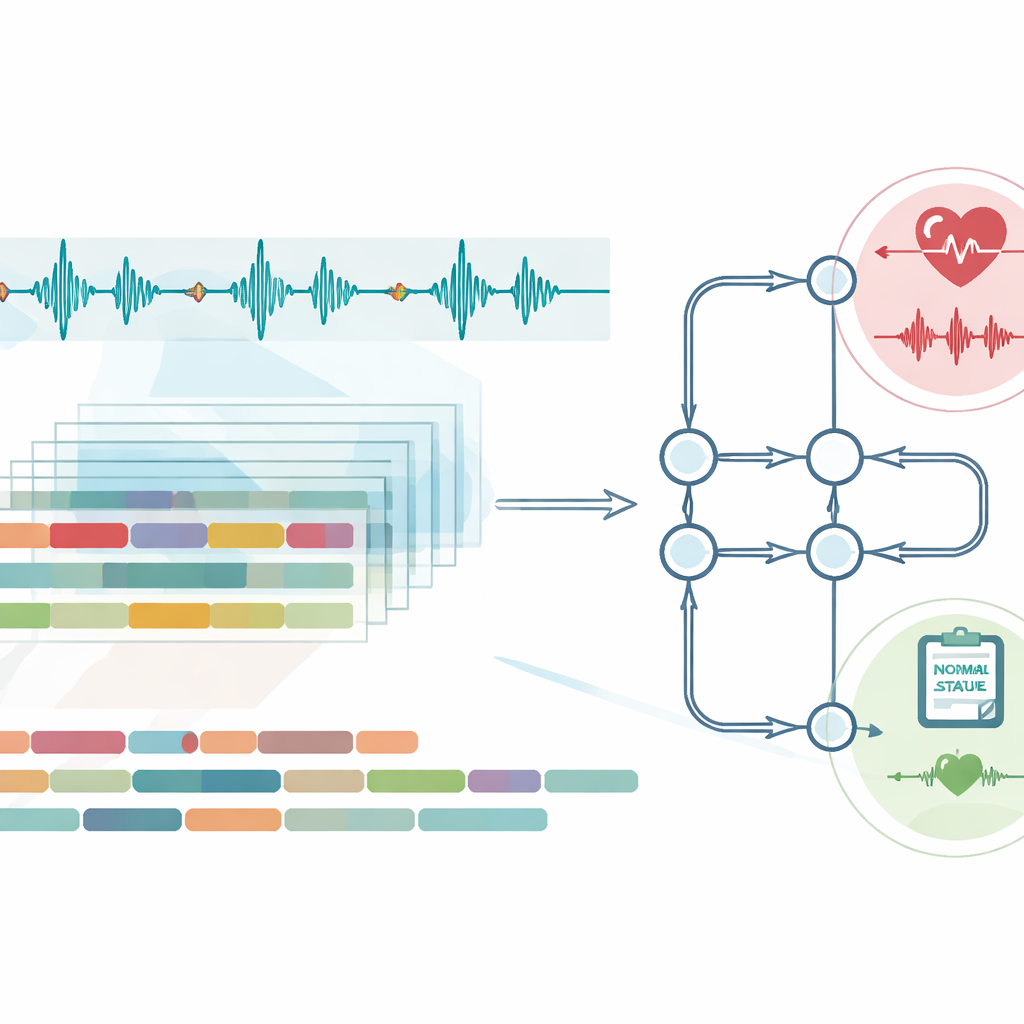
W rzeczywistych przychodniach nagrania zdrowych serc są znacznie częstsze niż te z poważnymi problemami. Jeśli komputer uczy się głównie na normalnych uderzeniach, może po prostu oznaczać wszystko jako prawidłowe i w dokumentacji wyglądać na dokładny. Aby uniknąć tej pułapki, zespół stosuje technikę tworzącą starannie przygotowane syntetyczne przykłady rzadszych wzorców szmerów, wyrównując zestaw treningowy bez prostego kopiowania danych. Równie ważne jest użycie typu sieci neuronowej zaprojektowanej do rozumienia sekwencji w czasie, co pozwala systemowi zwracać uwagę na to, jak dźwięki ewoluują w trakcie każdego uderzenia serca, zamiast traktować każdy moment oddzielnie. Te wybory sprawiają, że model staje się zarówno wrażliwy na nieprawidłowości, jak i odporny na hałas oraz zmienność między pacjentami.
Sprawiedliwe testowanie i unikanie ukrytych skrótów
Typowym problemem w medycznej sztucznej inteligencji jest „przeciek danych”, kiedy to to samo nagranie pacjenta przypadkowo wpływa i na trening, i na testowanie, co zawyża wyniki. Autorzy rozwiązują to wprost, dzieląc dane na poziomie nagrań w jednym zbiorze i na poziomie pacjentów w innym, zapewniając, że żaden fragment od tej samej osoby nie pojawia się w obu zestawach. Oceniają swój system na dwóch dużych, publicznych zbiorach dźwięków serca, które różnią się częstością występowania szmerów i zróżnicowaniem nagrań. W obu przypadkach model poprawnie odróżnia dźwięki normalne od nieprawidłowych w około 99 na 100 przypadków, z bardzo niewielką liczbą przeoczonych problemów i niską liczbą fałszywych alarmów. Dodatkowe testy przetasowujące dane na wiele sposobów pokazują, że ta wysoka skuteczność jest stabilna, a nie wynikiem szczęśliwego podziału.
Co to może znaczyć dla codziennej opieki
Badanie pokazuje, że starannie zaprojektowane algorytmy nasłuchu mogą dorównać lub przewyższyć wiele wcześniejszych podejść do automatycznego wykrywania szmerów, nawet przy surowszych i bardziej realistycznych zasadach testowania. Szanując naturalne tempo uderzeń serca, równoważąc rzadkie, ale istotne przypadki i chroniąc przed ukrytymi skrótami w danych, autorzy przedstawiają solidny model dla przyszłych cyfrowych stetoskopów. Choć potrzeba jeszcze pracy nad obsługą głośnych, rzeczywistych środowisk i nad tym, by decyzje systemu były łatwiejsze do interpretacji przez lekarzy, proponowane podejście wskazuje na przyszłość, w której mały czujnik i inteligentny model mogą pomóc wczesniej wykrywać niebezpieczne problemy sercowe na pierwszej linii opieki, bez względu na miejsce zamieszkania pacjentów.
Cytowanie: Ameen, A., Eldesouky Fattoh, I., Abd El-Hafeez, T. et al. Advancing cardiovascular screening: deep learning-based heart-sound classification using SMOTE and temporal modeling. Sci Rep 16, 12063 (2026). https://doi.org/10.1038/s41598-026-45276-9
Słowa kluczowe: szmery serca, cyfrowy stetoskop, głębokie uczenie, przesiewanie układu krążenia, analiza dźwięków serca