Clear Sky Science · fr
Faire progresser le dépistage cardiovasculaire : classification des sons cardiaques par apprentissage profond avec SMOTE et modélisation temporelle
Écouter le cœur autrement
Les maladies cardiaques sont la première cause de mortalité dans le monde, et pourtant dans de nombreuses cliniques l’outil principal de dépistage reste l’oreille du médecin et un simple stéthoscope. Des sons subtils de « whooshing », appelés souffles, peuvent alerter sur des problèmes valvulaires dangereux, mais ils sont faciles à manquer, en particulier hors des centres spécialisés. Cet article examine comment des ordinateurs peuvent analyser des enregistrements de sons cardiaques pour détecter les souffles de façon plus précise et cohérente, amenan t potentiellement un niveau de dépistage digne d’un expert dans les cliniques surchargées et les contextes à ressources limitées.
Pourquoi les sons cardiaques comptent
Chaque battement génère une bande sonore riche lorsque les valves se referment et que le sang traverse le cœur. Les médecins apprennent à interpréter ces sons après des années de formation, mais même des cliniciens expérimentés peuvent être en désaccord, et les médecins de soins primaires manquent souvent des indices importants. Parallèlement, les maladies cardiovasculaires causent des millions de décès chaque année, dont beaucoup pourraient être évités par une détection plus précoce. Les microphones numériques permettent désormais d’enregistrer facilement les sons cardiaques, mais transformer ces tracés ondulants en diagnostics fiables exige des algorithmes intelligents capables de gérer le bruit, la variabilité entre patients et des motifs anormaux rares mais critiques.
Transformer les battements bruts en motifs utiles
Les chercheurs ont construit une chaîne de traitement étape par étape qui imite la façon dont un expert pourrait écouter, mais avec la précision d’une machine. D’abord, ils détectent automatiquement les événements clés du battement — les principaux pics « lub‑dub » — et découpent l’enregistrement en courts extraits d’une seconde centrés sur ces points. Cela préserve le rythme naturel du cycle cardiaque. Ensuite, ils convertissent chaque extrait en une description compacte de sa hauteur et de son timbre en utilisant une méthode initialement inspirée de l’audition humaine. Plutôt que d’alimenter le modèle avec le son brut, ils utilisent ces motifs distillés comme entrée, ce qui facilite pour l’ordinateur la concentration sur des différences médicalement significatives entre sons normaux et souffles. 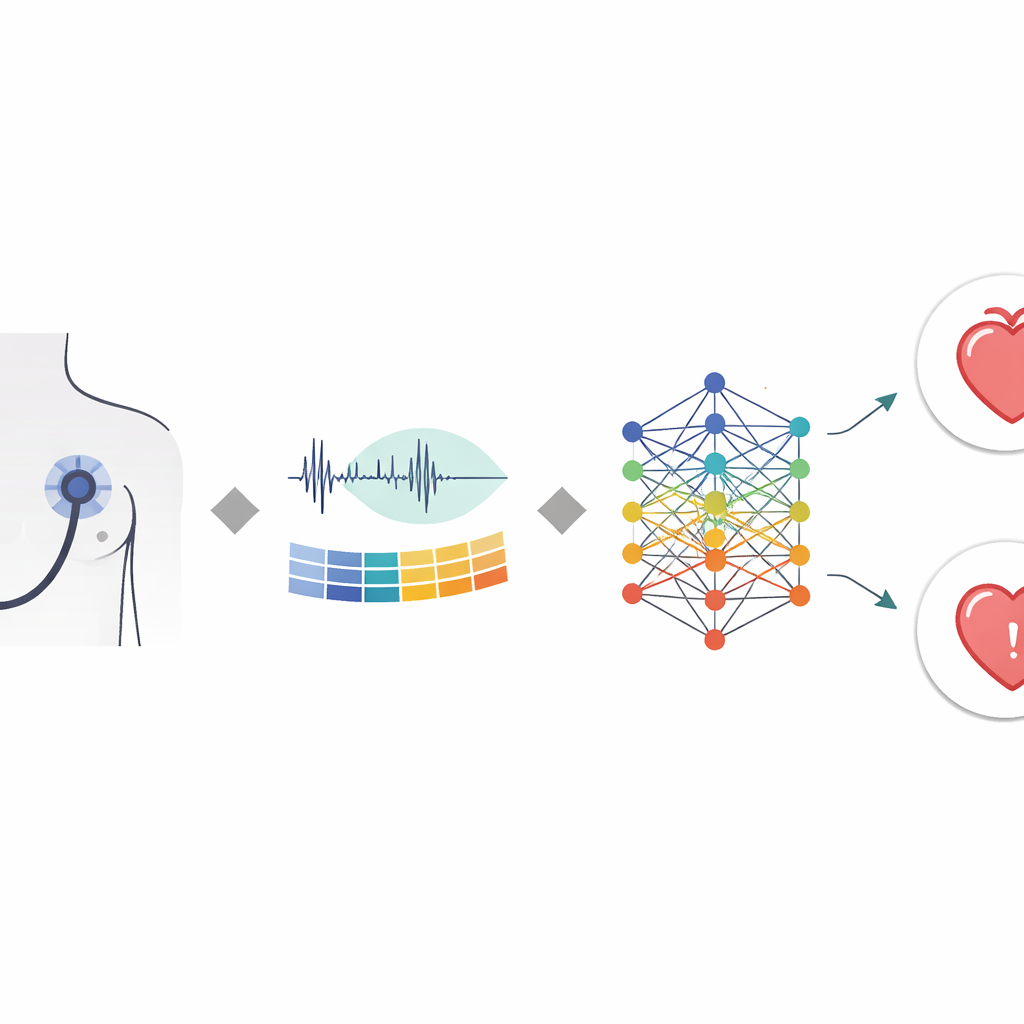
Équilibrer les souffles rares et l’apprentissage dans le temps
Dans les cliniques réelles, les enregistrements de cœurs sains sont beaucoup plus fréquents que ceux présentant des problèmes graves. Si un ordinateur apprend principalement à partir de battements normaux, il peut avoir tendance à tout étiqueter comme normal et sembler pourtant précis sur le papier. Pour éviter ce piège, l’équipe utilise une technique qui crée des exemples synthétiques soigneusement conçus des motifs de souffle plus rares, équilibrant l’ensemble d’entraînement sans copier les données. Tout aussi important, ils utilisent un type de réseau neuronal conçu pour comprendre les séquences dans le temps, permettant au système de tenir compte de l’évolution des sons tout au long de chaque battement plutôt que de traiter chaque instant isolément. Ensemble, ces choix aident le modèle à être à la fois sensible aux anomalies et résistant au bruit et à la variabilité entre patients.
Tester équitablement et éviter les raccourcis cachés
Un problème fréquent en IA médicale est la « fuite de données », où l’enregistrement du même patient influence par erreur à la fois l’entraînement et le test, donnant une performance artificiellement élevée. Les auteurs affrontent ce problème de front en scindant leurs données au niveau de l’enregistrement dans un jeu de données et au niveau du patient dans un autre, garantissant qu’aucun segment provenant de la même personne n’apparaît dans les deux ensembles. Ils évaluent leur système sur deux grandes collections publiques de sons cardiaques qui diffèrent par la prévalence des souffles et par la diversité des enregistrements. Dans les deux cas, le modèle distingue correctement sons normaux et anormaux dans environ 99 cas sur 100, avec très peu de problèmes manqués et peu de fausses alertes. Des vérifications supplémentaires qui remélangent les données de plusieurs façons montrent que cette forte performance est stable et n’est pas due au hasard lié à une seule division favorable. 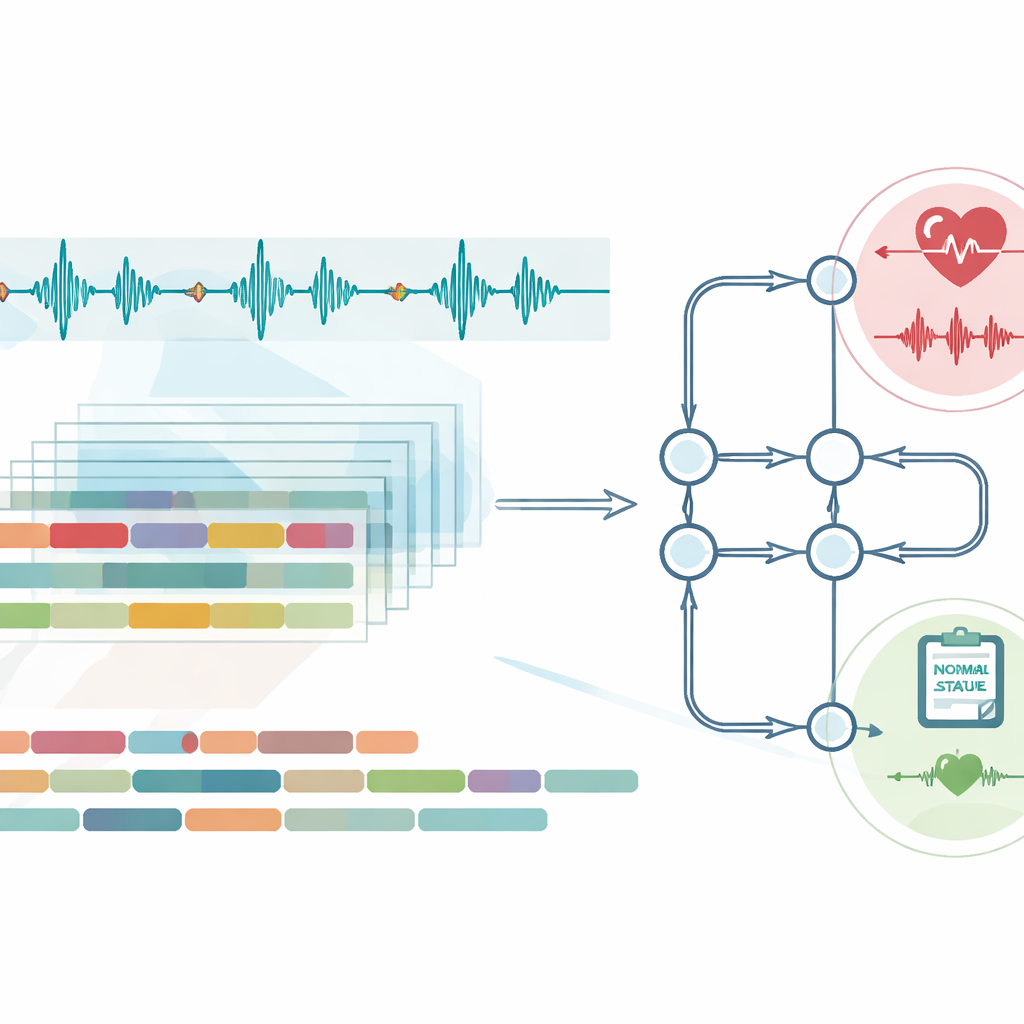
Ce que cela pourrait signifier pour les soins quotidiens
L’étude montre que des algorithmes d’écoute soigneusement conçus peuvent égaler ou surpasser de nombreuses approches antérieures pour la détection automatique des souffles, même sous des règles de test plus strictes et plus réalistes. En respectant le timing naturel des battements, en équilibrant des cas rares mais cruciaux et en se protégeant contre les raccourcis cachés dans les données, les auteurs proposent une feuille de route robuste pour les futurs stéthoscopes numériques. Bien qu’il reste du travail pour gérer des environnements réels bruyants et rendre les décisions du système plus faciles à interpréter par les médecins, ce cadre ouvre la voie vers un futur où un petit capteur et un modèle intelligent pourraient aider les cliniques de première ligne à détecter tôt les problèmes cardiaques dangereux, quel que soit le lieu de vie des patients.
Citation: Ameen, A., Eldesouky Fattoh, I., Abd El-Hafeez, T. et al. Advancing cardiovascular screening: deep learning-based heart-sound classification using SMOTE and temporal modeling. Sci Rep 16, 12063 (2026). https://doi.org/10.1038/s41598-026-45276-9
Mots-clés: souffles cardiaques, stéthoscope numérique, apprentissage profond, dépistage cardiovasculaire, analyse des sons cardiaques