Clear Sky Science · pl
Pipeline CNN–Bi-LSTM i otwarty zbiór danych FSW do rozpoznawania akcji w zapasach wolnych
Nauczanie komputerów obserwowania zapasów
Zapasy wolne są szybkie, splecione i chaotyczne do oglądania — nawet dla ludzi. Dla komputerów rozróżnienie jednego rzutu od innego na zatłoczonym macie jest jeszcze trudniejsze. Badanie pokazuje, jak starannie zaprojektowany pipeline wideo i nowy publiczny zbiór danych mogą pomóc maszynom rozpoznawać konkretne techniki zapaśnicze, otwierając drogę do inteligentniejszej analityki sportowej, narzędzi trenerskich i automatycznego generowania skrótów.
Wyzwanie sportów bliskiego kontaktu
Większość współczesnych systemów rozpoznawania wideo trenowano na klipach, w których osoby są stosunkowo odseparowane i łatwe do zobaczenia, np. ktoś biegnie lub uderza w rakietę tenisową. Zapasy wolne są inne: zawodnicy są ze sobą zablokowani, kończyny nachodzą na siebie, a scena pełna jest rozpraszaczy — sędziów, maty i dopingującej publiczności. Standardowe benchmarki nie oddają tej złożoności, więc metody sprawdzające się przy codziennych akcjach często zawodzą, gdy zapaśnicy chwytają się, przewracają i skręcają w szybkim tempie.
Budowa nowej biblioteki ruchów zapaśniczych
Aby sprostać tej luki, autorzy stworzyli zbiór Open FSW — starannie dobraną kolekcję 210 krótkich klipów z zapasów wolnych. Każdy klip pokazuje dokładnie jeden kompletny ruch, wybrany spośród siedmiu dobrze zdefiniowanych technik, takich jak rzuty biodrowe, ataki na nogi i przewroty. Klipy pochodzą z dwóch źródeł: kontrolowanych sesji treningowych z niewielką grupą zawodników oraz transmisji z zawodów, które wprowadzają różnorodność kąta kamery, oświetlenia i zatłoczonego tła. Eksperci i sędziowie pomogli w etykietowaniu każdego klipu, a zbiór danych podzielono tak, by klipy z tego samego meczu lub sesji treningowej nigdy nie występowały jednocześnie w zbiorze treningowym i testowym, zmniejszając ryzyko przeszacowania wyników.
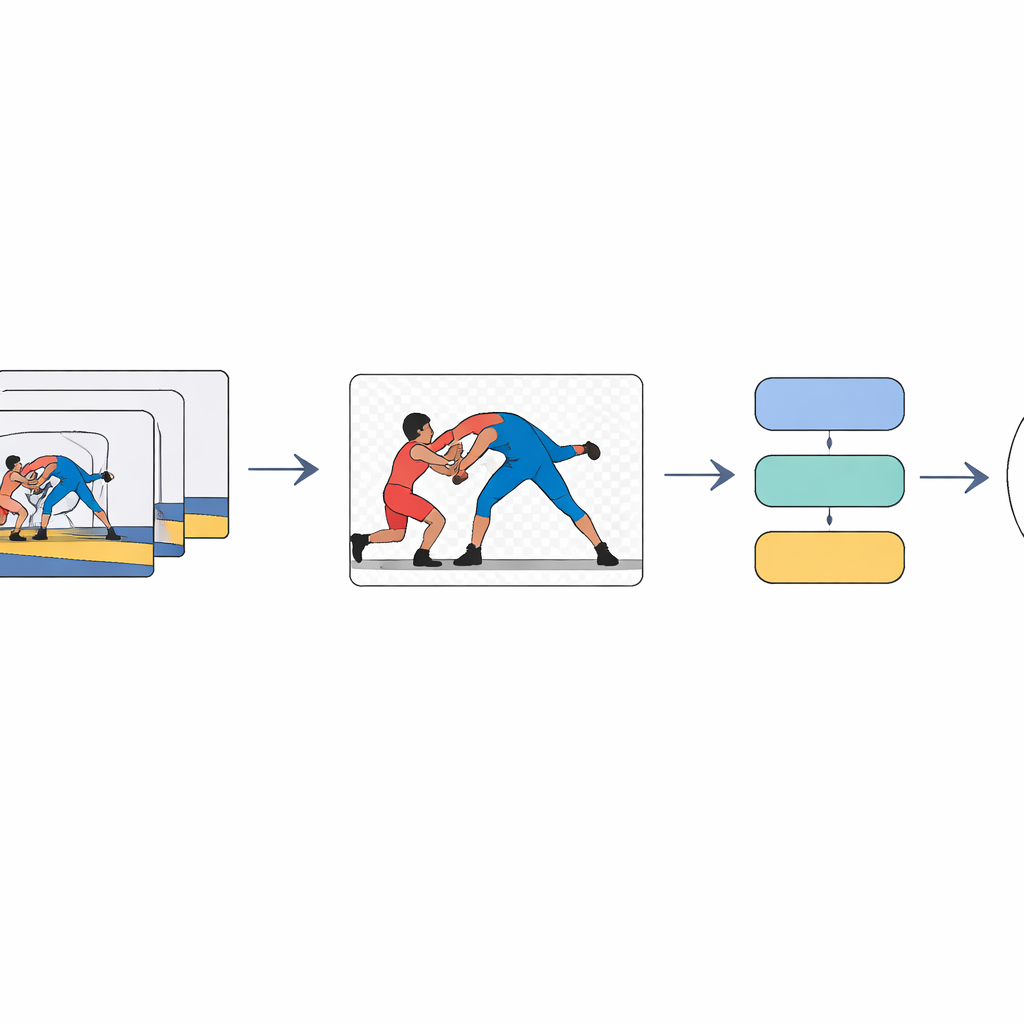
Skupienie na zapaśnikach, nie na tłumie
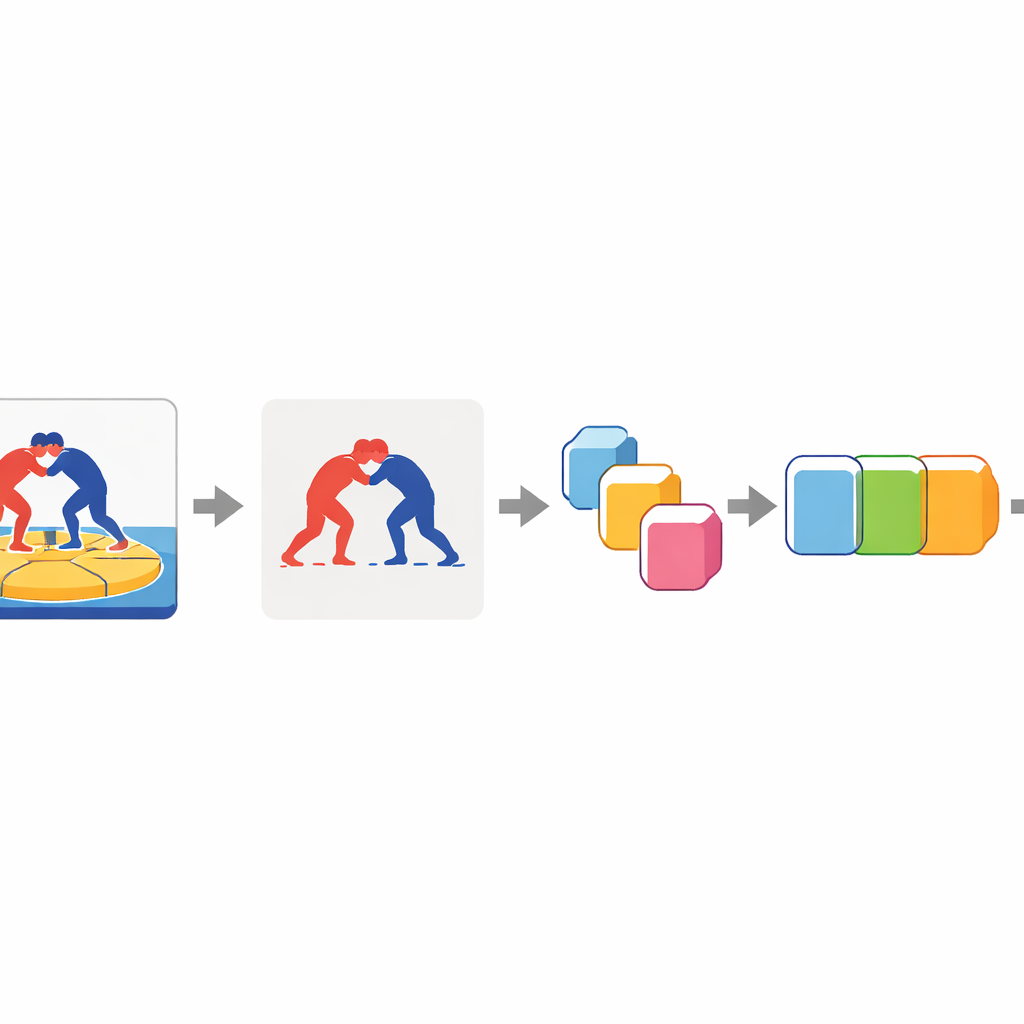
Rdzeniem podejścia jest nauczenie komputera „zwracania uwagi” na zapaśników i zignorowania reszty sceny. Każda klatka wideo najpierw przechodzi przez model segmentacji, który oddziela zawodników od tła i generuje czyste sylwetki pierwszego planu. Te klatki pierwszego planu są następnie przetwarzane przez głęboką sieć obrazową, która kompresuje każde zdjęcie do zwartego wektora cech — w praktyce numerycznego streszczenia kształtów i pozycji zapaśników w danym momencie. Na koniec dwukierunkowy model sekwencyjny analizuje całą serię podsumowań klatek, od początku do końca i wstecz, aby zdecydować, która z siedmiu technik jest wykonywana w klipie.
Jak dobrze system uczy się ruchów
Naukowcy przetestowali kilka popularnych enkoderów obrazowych i porównali swój pipeline uwzględniający pierwszy plan z wcześniejszymi metodami opartymi głównie na szkieletonach zawodników. Najlepsza konfiguracja, łącząca dostrojony model segmentacji z backbonem obrazu EfficientNet i modelem sekwencyjnym, poprawnie identyfikuje ruch w około 83 procentach klipów. To wyraźna poprawa względem solidnej bazy opartej na szkieletonie oraz względem wersji ich własnego systemu pomijających etap wyodrębniania pierwszego planu. Zyski są najsilniejsze dla ruchów, w których ciała są mocno splecione, a tło szczególnie rozpraszające. Testy statystyczne przeprowadzone na wielu podziałach danych potwierdzają, że te ulepszenia są mało prawdopodobne do uzyskania przypadkowo.
Kompromisy, ograniczenia i szerszy wpływ
Skupienie na zapaśnikach ma swoją cenę: wykonanie dodatkowego kroku segmentacji mniej więcej podwaja czas przetwarzania jednego klipu na testowanym sprzęcie. Do analiz offline — takich jak powysiłkowe rozbiórki meczów czy studia badawcze — ten narzut jest akceptowalny, ale aplikacje w czasie rzeczywistym mogą wymagać szybszych modeli segmentacji lub mocniejszych maszyn. Badanie zauważa także, że zbiór danych jest relatywnie niewielki, co autorzy rekompensują transfer learningiem i augmentacją danych, oraz że segmentacja może mieć problemy przy ekstremalnym rozmyciu ruchu lub silnej zasłonie ciała.
Co to oznacza dla kibiców i trenerów
Mówiąc prosto: praca pokazuje, że oczyszczenie tego, co widzi komputer — przez wyodrębnienie zapaśników z zatłoczonej sceny przed analizą akcji — znacząco poprawia jego zdolność do nazywania konkretnych ruchów. Choć obecne wyniki są dopasowane do zapasów wolnych, ta sama idea może przełożyć się na inne sporty bliskiego kontaktu, jak judo czy brazylijskie jiu-jitsu. Udostępniając zarówno zbiór danych, jak i kod, autorzy dają podstawę pod przyszłe systemy, które automatycznie rozłożą złożone wymiany chwytów, pomagając trenerom, zawodnikom i kibicom lepiej rozumieć, co dzieje się na macie.
Cytowanie: Rostamian, M., Mottaghi, A. & Soryani, M. A CNN–Bi-LSTM pipeline and open FSW dataset for freestyle wrestling action recognition. Sci Rep 16, 14632 (2026). https://doi.org/10.1038/s41598-026-44782-0
Słowa kluczowe: zapasy wolne, rozpoznawanie akcji, analityka sportowa, widzenie komputerowe, uczenie głębokie