Clear Sky Science · it
Una pipeline CNN–Bi-LSTM e un dataset open FSW per il riconoscimento delle azioni nel wrestling libero
Insegnare ai computer a guardare il wrestling
Il wrestling libero è veloce, aggrovigliato e spesso difficile da seguire anche per gli spettatori umani. Per i computer, distinguere una proiezione da un’altra in un’arena affollata è ancora più complicato. Questo studio mostra come una pipeline video accuratamente progettata e un nuovo dataset pubblico possano aiutare le macchine a riconoscere tecniche di wrestling specifiche, aprendo la strada ad analisi sportive più intelligenti, strumenti per allenatori e generazione automatica di highlight.
La sfida degli sport da contatto ravvicinato
La maggior parte dei moderni sistemi di riconoscimento video è stata addestrata su clip in cui le persone sono relativamente separate e facili da vedere, come qualcuno che corre o che colpisce una racchetta. Il wrestling libero è diverso: gli atleti sono bloccati insieme, gli arti si sovrappongono e la scena è piena di distrazioni dovute a arbitri, tappeti e pubblico. I benchmark standard non catturano questa complessità, quindi i metodi che funzionano bene su azioni quotidiane spesso faticano quando i lottatori si clinchano, rotolano e si contorcono in rapida successione.
Costruire una nuova libreria di mosse di wrestling
Per colmare questa lacuna, gli autori hanno creato l’Open FSW dataset, una raccolta curata di 210 brevi clip di wrestling libero. Ogni clip mostra esattamente una mossa completa, scelta tra sette tecniche ben definite come proiezioni d’anca, attacchi alle gambe e spazzate rotanti. Le clip provengono da due sorgenti: sessioni di allenamento controllate con un piccolo gruppo di atleti e incontri trasmessi in diretta da competizioni pubbliche, che aggiungono varietà in termini di angolazione della camera, illuminazione e rumore di fondo. Esperti e arbitri hanno contribuito all’etichettatura di ogni clip, e il dataset è diviso in modo che clip provenienti dalla stessa gara o sessione di allenamento non compaiano né nel training né nel test, riducendo il rischio di sovrastimare le prestazioni.
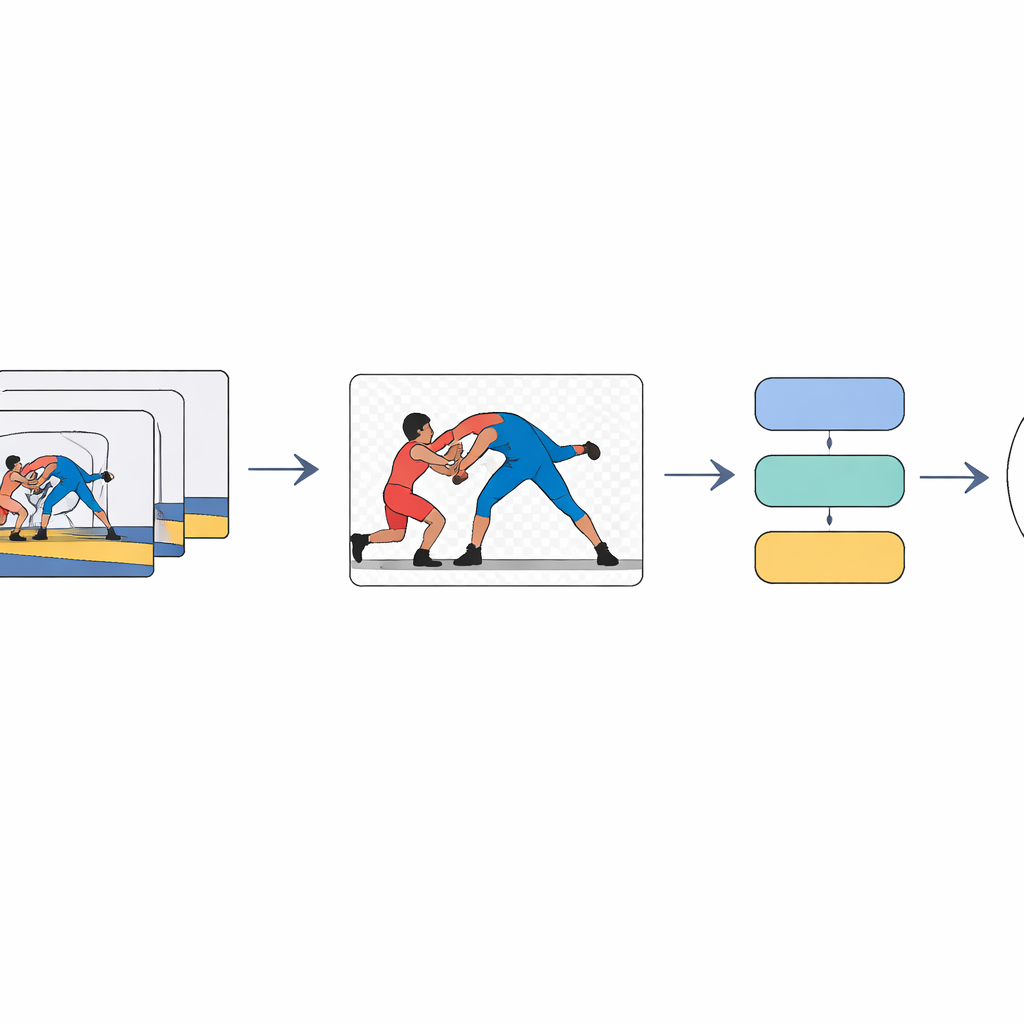
Concentrarsi sui lottatori, non sulla folla
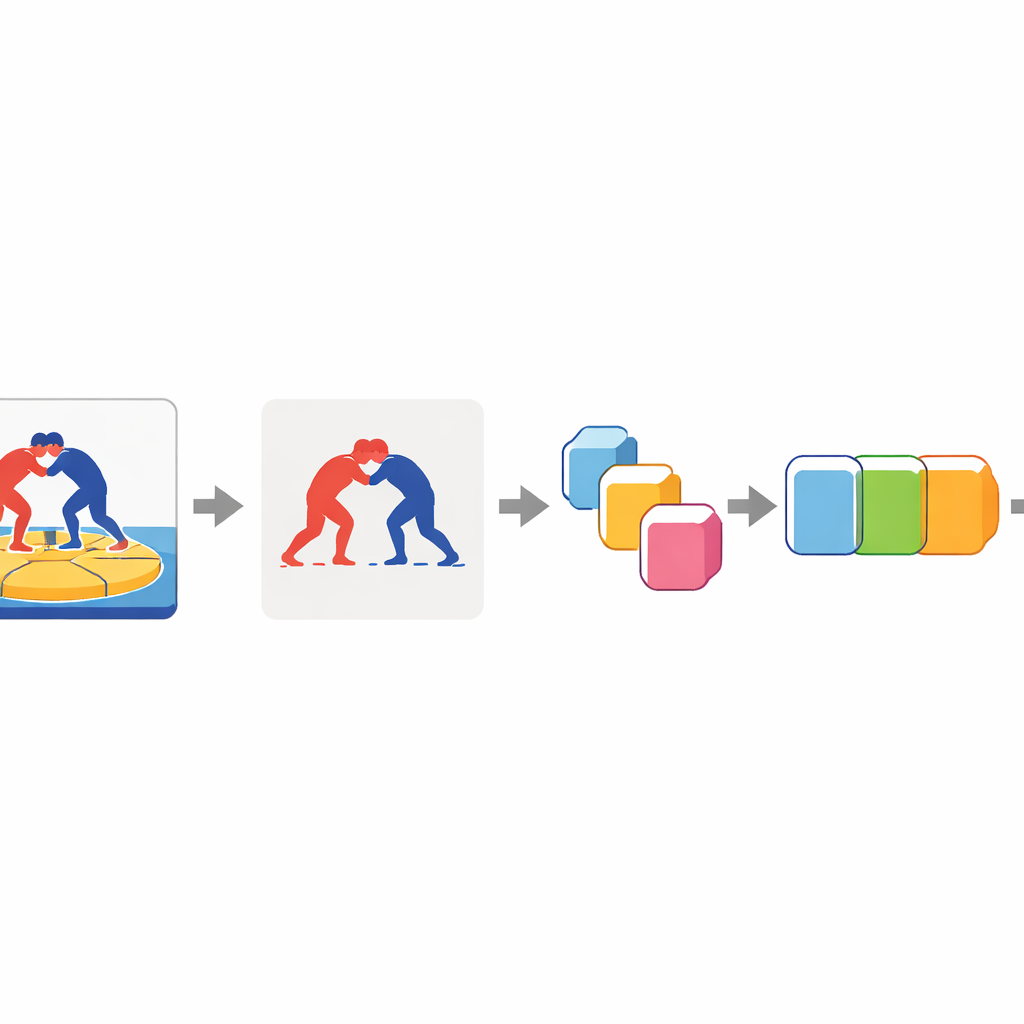
Il cuore dell’approccio è insegnare al computer a “prestare attenzione” ai lottatori e a ignorare perlopiù il resto. Ogni fotogramma del video passa prima attraverso un modello di segmentazione che separa gli atleti dallo sfondo e produce silhouette di primo piano pulite. Questi fotogrammi di primo piano vengono poi elaborati da una rete profonda per immagini che comprime ciascuna immagine in un vettore di caratteristiche compatto — essenzialmente un riassunto numerico delle forme e delle posizioni dei lottatori in quel momento. Infine, un modello di sequenza bidirezionale analizza l’intera serie di riassunti dei fotogrammi, dall’inizio alla fine e viceversa, per decidere quale delle sette tecniche viene eseguita nella clip.
Quanto bene il sistema apprende le mosse
I ricercatori hanno testato diversi encoder di immagini popolari e hanno confrontato la loro pipeline consapevole del primo piano con metodi precedenti che si basano principalmente su scheletri degli atleti. La loro configurazione migliore, che combina segmentazione fine-tunata con un backbone EfficientNet per le immagini e un modello di sequenza, identifica correttamente la mossa in circa l’83 percento delle clip. Questo rappresenta un miglioramento chiaro rispetto a un forte baseline basato sullo scheletro e rispetto a versioni del loro stesso sistema che saltano la fase di primo piano. I guadagni sono più marcati per le mosse in cui i corpi sono fortemente intrecciati e lo sfondo è particolarmente distraente. Test statistici su più fold dei dati confermano che questi miglioramenti difficilmente sono dovuti al caso.
Compromessi, limiti e impatto più ampio
Concentrarsi sui lottatori comporta però un costo: eseguire un ulteriore passaggio di segmentazione raddoppia approssimativamente il tempo di elaborazione per clip sull’hardware testato. Per l’analisi offline — come le revisioni post-incontro o gli studi di ricerca — questo overhead è accettabile, ma le applicazioni in tempo reale potrebbero richiedere modelli di segmentazione più veloci o macchine più potenti. Lo studio osserva inoltre che il dataset è relativamente piccolo, problema che gli autori mitigano con transfer learning e data augmentation, e che la segmentazione può avere difficoltà in presenza di forte motion blur o occlusioni severe.
Cosa significa per tifosi e allenatori
In termini semplici, il lavoro mostra che ripulire ciò che il computer vede — ritagliando i lottatori dalla scena affollata prima di analizzare l’azione — rende molto più efficace il riconoscimento delle mosse specifiche. Sebbene i risultati attuali siano ottimizzati per il wrestling libero, la stessa idea potrebbe essere applicata ad altri sport da contatto ravvicinato come il judo o il Brazilian jiu-jitsu. Rilasciando sia il dataset che il codice, gli autori forniscono una base per futuri sistemi in grado di scomporre automaticamente gli scambi di lotta complessi, aiutando allenatori, atleti e appassionati a comprendere meglio ciò che avviene sul tappeto.
Citazione: Rostamian, M., Mottaghi, A. & Soryani, M. A CNN–Bi-LSTM pipeline and open FSW dataset for freestyle wrestling action recognition. Sci Rep 16, 14632 (2026). https://doi.org/10.1038/s41598-026-44782-0
Parole chiave: wrestling libero, riconoscimento delle azioni, analisi sportiva, computer vision, deep learning