Clear Sky Science · fr
Une chaîne CNN–Bi-LSTM et un jeu de données Open FSW pour la reconnaissance d’actions en lutte libre
Apprendre aux ordinateurs à regarder la lutte
La lutte libre est rapide, emmêlée et difficile à suivre — même pour les humains. Pour les ordinateurs, distinguer un lancer d’un autre dans une arène encombrée est encore plus délicat. Cette étude montre comment une chaîne vidéo conçue avec soin et un nouveau jeu de données public peuvent aider les machines à reconnaître des techniques de lutte spécifiques, ouvrant la voie à des analyses sportives plus intelligentes, à des outils de coaching et à la génération automatique de temps forts.
Le défi des sports en contact rapproché
La plupart des systèmes modernes de reconnaissance vidéo sont entraînés sur des séquences où les personnes sont relativement séparées et faciles à voir, comme quelqu’un qui court ou qui frappe une raquette. La lutte libre est différente : les athlètes sont verrouillés l’un à l’autre, les membres se recouvrent, et la scène est remplie de distractions — arbitres, tapis et supporters. Les benchmarks standards ne reflètent pas cette complexité, si bien que des méthodes performantes sur des actions courantes peinent souvent lorsque les lutteurs se saisissent, roulent et se tordent en succession rapide.
Construire une nouvelle bibliothèque de gestes de lutte
Pour combler ce vide, les auteurs ont créé l’ensemble Open FSW, une collection soignée de 210 courtes séquences de lutte libre. Chaque extrait montre exactement un mouvement complet, choisi parmi sept techniques bien définies comme les projections de hanche, les attaques de jambes et les balayages roulés. Les clips proviennent de deux sources : des séances d’entraînement contrôlées avec un petit groupe d’athlètes, et des retransmissions de matchs publics, qui ajoutent de la variété en termes d’angle de caméra, d’éclairage et de bruit de fond. Des experts et des arbitres ont aidé à annoter chaque clip, et le jeu de données est partitionné de sorte que les extraits issus d’un même match ou d’une même séance ne figurent jamais à la fois dans l’entraînement et dans le test, réduisant le risque de surestimer les performances.
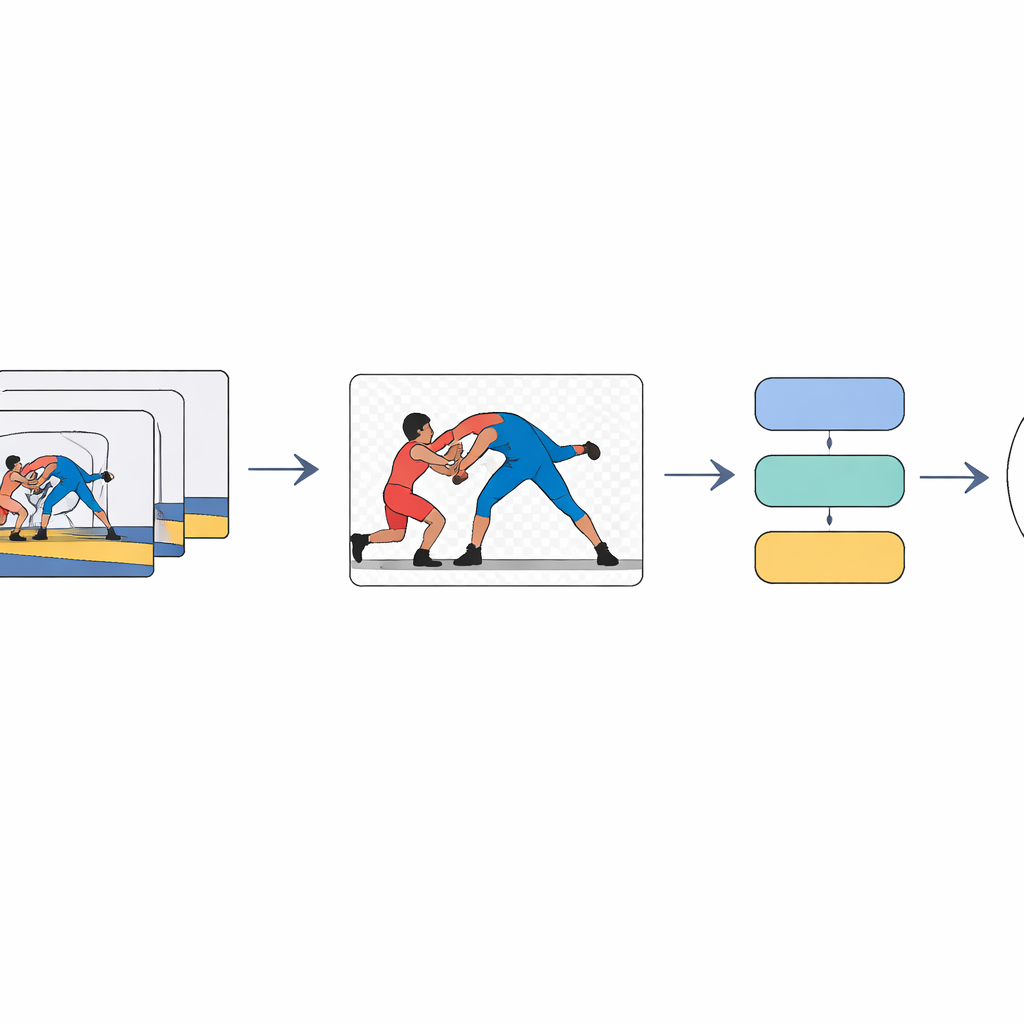
Se concentrer sur les lutteurs, pas sur la foule
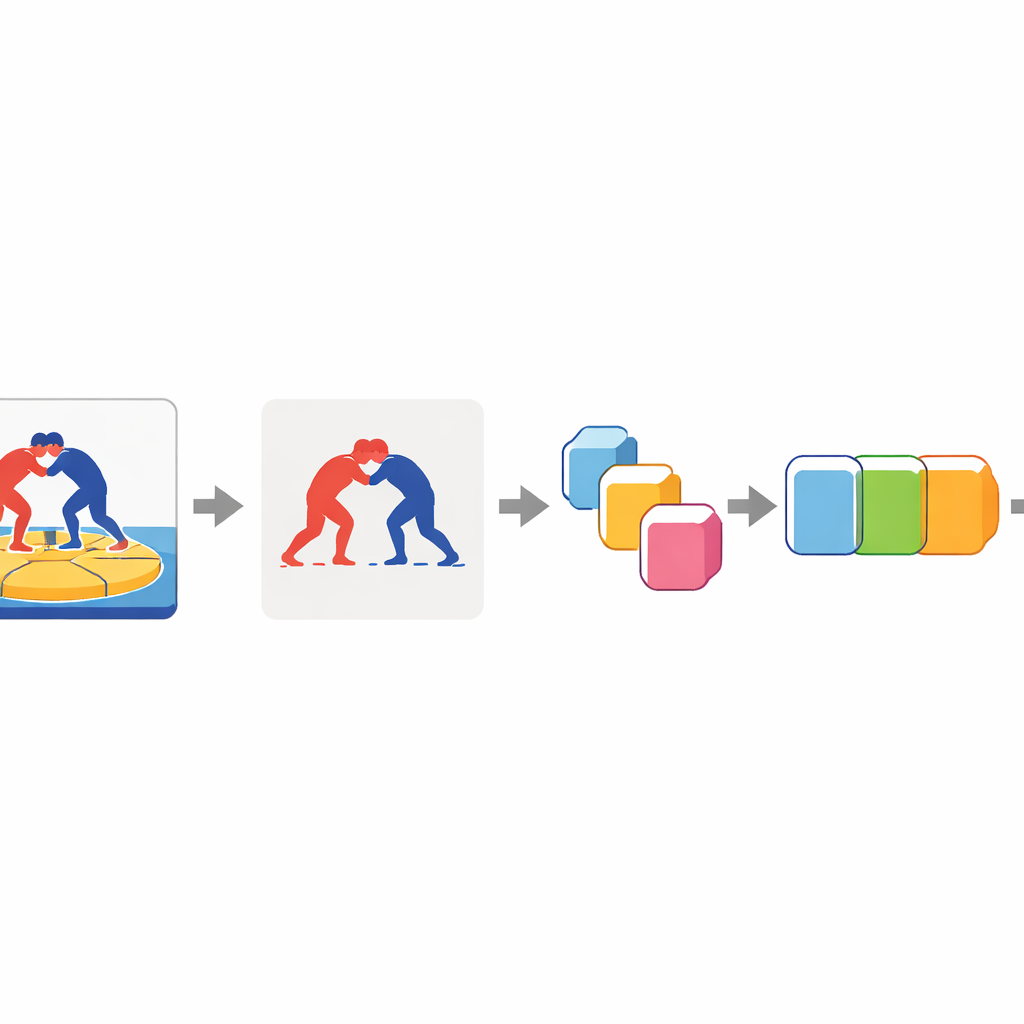
Le cœur de l’approche consiste à apprendre à l’ordinateur à « prêter attention » aux lutteurs et à ignorer en grande partie le reste. Chaque image vidéo passe d’abord par un modèle de segmentation qui sépare les athlètes de l’arrière-plan et produit des silhouettes de premier plan propres. Ces images de premier plan sont ensuite traitées par un réseau d’images profond qui compresse chaque image en un vecteur de caractéristiques compact — essentiellement un résumé numérique des formes et positions des lutteurs à cet instant. Enfin, un modèle séquentiel bidirectionnel examine l’ensemble des résumés d’images, du début à la fin et dans l’autre sens, pour décider laquelle des sept techniques est exécutée dans le clip.
Quelle est l’efficacité du système pour apprendre les mouvements
Les chercheurs ont testé plusieurs encodeurs d’image populaires et comparé leur chaîne sensible au premier plan à des méthodes antérieures reposant principalement sur des squelettes des athlètes. Leur meilleure configuration, qui combine une segmentation finement ajustée avec un backbone d’image EfficientNet et un modèle séquentiel, identifie correctement le mouvement dans environ 83 % des clips. Il s’agit d’une amélioration nette par rapport à une solide référence basée sur les squelettes et par rapport à des variantes de leur propre système qui sautent l’étape de premier plan. Les gains sont les plus marqués pour les mouvements où les corps sont fortement enchevêtrés et où l’arrière-plan est particulièrement distrayant. Des tests statistiques sur plusieurs partitions des données confirment que ces améliorations ont peu de chances d’être dues au hasard.
Compromis, limites et impact plus large
Se focaliser sur les lutteurs a un coût : exécuter une étape de segmentation supplémentaire double à peu près le temps de traitement par clip sur le matériel testé. Pour l’analyse hors ligne — comme les débriefings post-match ou les études de recherche — cette surcharge est acceptable, mais les applications en temps réel pourraient nécessiter des modèles de segmentation plus rapides ou des machines plus puissantes. L’étude note également que le jeu de données est relativement petit, ce qu’ils compensent par l’apprentissage par transfert et l’augmentation des données, et que la segmentation peut peiner en cas de flou de mouvement extrême ou d’occlusion sévère.
Ce que cela signifie pour les supporters et les entraîneurs
En termes simples, ce travail montre qu’épurer ce que voit l’ordinateur — en découpant les lutteurs hors d’une scène encombrée avant d’analyser l’action — améliore nettement sa capacité à nommer des mouvements spécifiques. Bien que les résultats actuels soient adaptés à la lutte libre, la même idée pourrait s’appliquer à d’autres sports de contact rapproché comme le judo ou le jiu-jitsu brésilien. En publiant à la fois le jeu de données et le code, les auteurs posent une base pour des systèmes futurs capables de décomposer automatiquement des échanges de lutte complexes, aidant entraîneurs, athlètes et spectateurs à mieux comprendre ce qui se passe sur le tapis.
Citation: Rostamian, M., Mottaghi, A. & Soryani, M. A CNN–Bi-LSTM pipeline and open FSW dataset for freestyle wrestling action recognition. Sci Rep 16, 14632 (2026). https://doi.org/10.1038/s41598-026-44782-0
Mots-clés: lutte libre, reconnaissance d’actions, analyse sportive, vision par ordinateur, apprentissage profond