Clear Sky Science · pl
Miękkie, wygładzające uczenie kontrastowe z pamięcią hybrydową dla niesuperwizowanej re-identyfikacji osób w widzialnym i podczerwonym
Widzieć ludzi w ciemności
Nowoczesne miasta są pokryte kamerami, ale większość z nich ma problemy w nocy lub przy złej pogodzie. Kamery na podczerwień, które rejestrują ciepło zamiast światła widzialnego, mogą wypełnić tę lukę. Wyzwanie polega na tym, by nauczyć komputery rozpoznawać tę samą osobę, gdy wygląda bardzo inaczej dla kamery dziennej i kamery termowizyjnej — i zrobić to bez ręcznego etykietowania tysięcy obrazów przez ekspertów. W tej pracy proponuje się nowy sposób automatycznego uczenia takich dopasowań, co czyni całodobowe, bardziej respektujące prywatność systemy bezpieczeństwa bardziej praktycznymi.
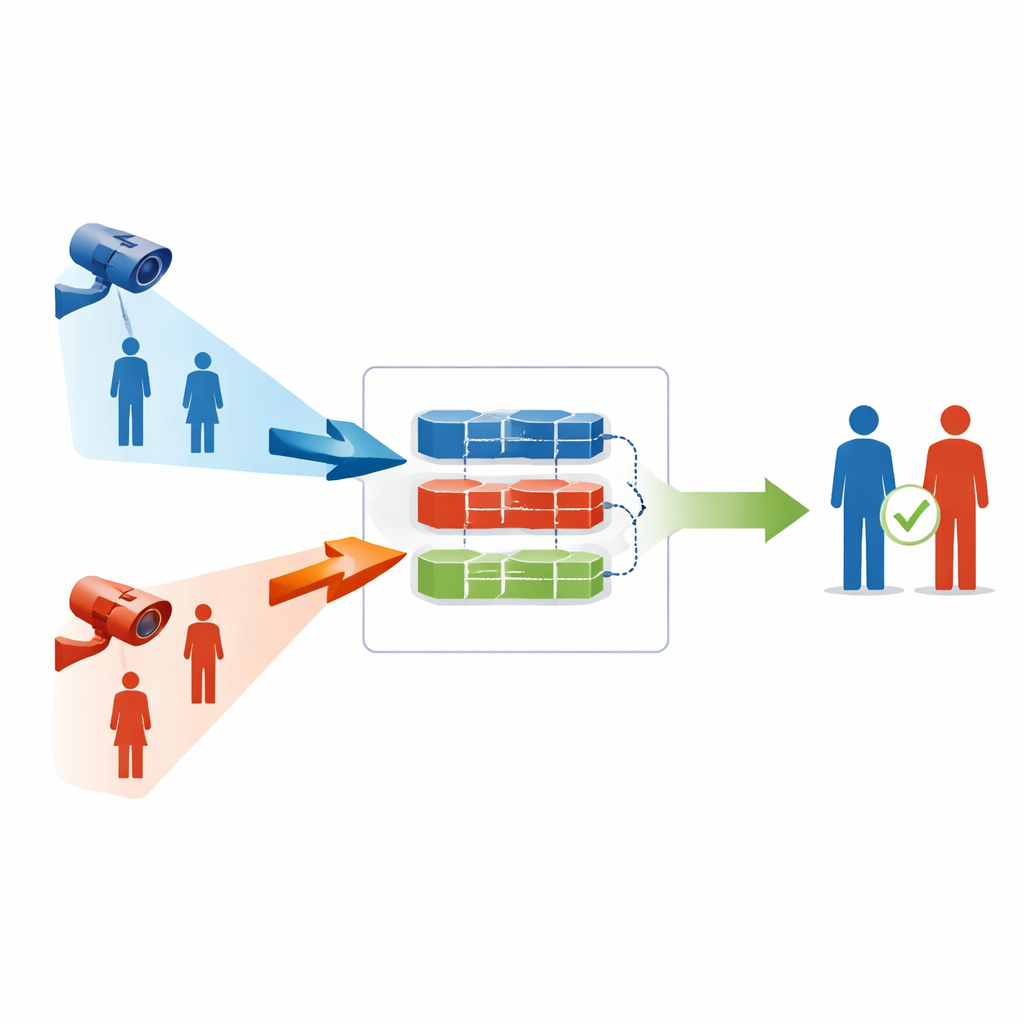
Dopasowywanie osób między dwiema bardzo różnymi rzeczywistościami
Re-identyfikacja osób widzialne–podczerwień stawia pozornie proste pytanie: mając obraz osoby zarejestrowany przez zwykłą kamerę kolorową, czy potrafimy odnaleźć tę samą osobę w nagraniu z kamery na podczerwień lub odwrotnie? W praktyce oba typy obrazów różnią się kolorem, kontrastem i detalami, więc wewnętrzny opis osoby tworzony przez komputer może się rozjechać między rodzajami kamer. Wcześniejsze systemy często bazowały na dużych zbiorach ręcznie oznaczonych obrazów, gdzie ludzie wskazywali, które zdjęcia przedstawiają tę samą osobę. To jest kosztowne i czasochłonne, szczególnie w wielokamerowych sieciach na dużych terenach, takich jak kampusy, lotniska czy kwartały miejskie.
Uczenie bez etykiet od ludzi
Autorzy skupiają się na trudniejszej, „niesuperwizowanej” wersji problemu, gdzie nie dostarcza się prawdziwych etykiet tożsamości. Zamiast tego komputer najpierw grupuje podobne obrazy w klastry, traktując każdy klaster jakby reprezentował jedną osobę. Te przypuszczalne tożsamości nazywa się pseudo-etykietami. Zasilają one popularną strategię treningową zwaną uczeniem kontrastowym, w której model przyciąga obrazy z tego samego klastra bliżej w swojej reprezentacji wewnętrznej i oddala klastry różne. Jednak klasteryzacja jest daleka od doskonałości: osoby w podobnych ubraniach mogą być mylnie łączone, a przepaść między widzialnym a podczerwonym obrazem wprowadza dodatkowe błędy. Gdy takie błędne przypuszczenia zostaną utrwalone w treningu, mogą wprowadzać model w błąd i zmniejszać jego wiarygodność.
Wygładzanie zaszumionych przypuszczeń
Aby okiełznać te wadliwe pseudo-etykiety, artykuł wprowadza schemat „miękkiego wygładzania” w uczeniu kontrastowym, wykorzystujący dwa współpracujące sieci neuronowe: ucznia i nauczyciela. Uczeń jest aktualizowany w standardowy sposób podczas treningu, natomiast nauczyciel to wolno poruszające się uśrednienie parametrów ucznia. Dla każdego obrazu nauczyciel daje łagodną, probabilistyczną ocenę dopasowania do każdego klastra, zamiast twardej decyzji tak/nie. Ta miękka ocena jest następnie mieszana z bardziej zdecydowanym przypisaniem klastra przez ucznia. Efektem jest wygładzony cel, który tłumi niepewne decyzje i zwiększa wpływ bardziej wiarygodnych. W praktyce model uczy się ufać stopniowym trendom w czasie, zamiast reagować gwałtownie na każdy zaszumiony update.
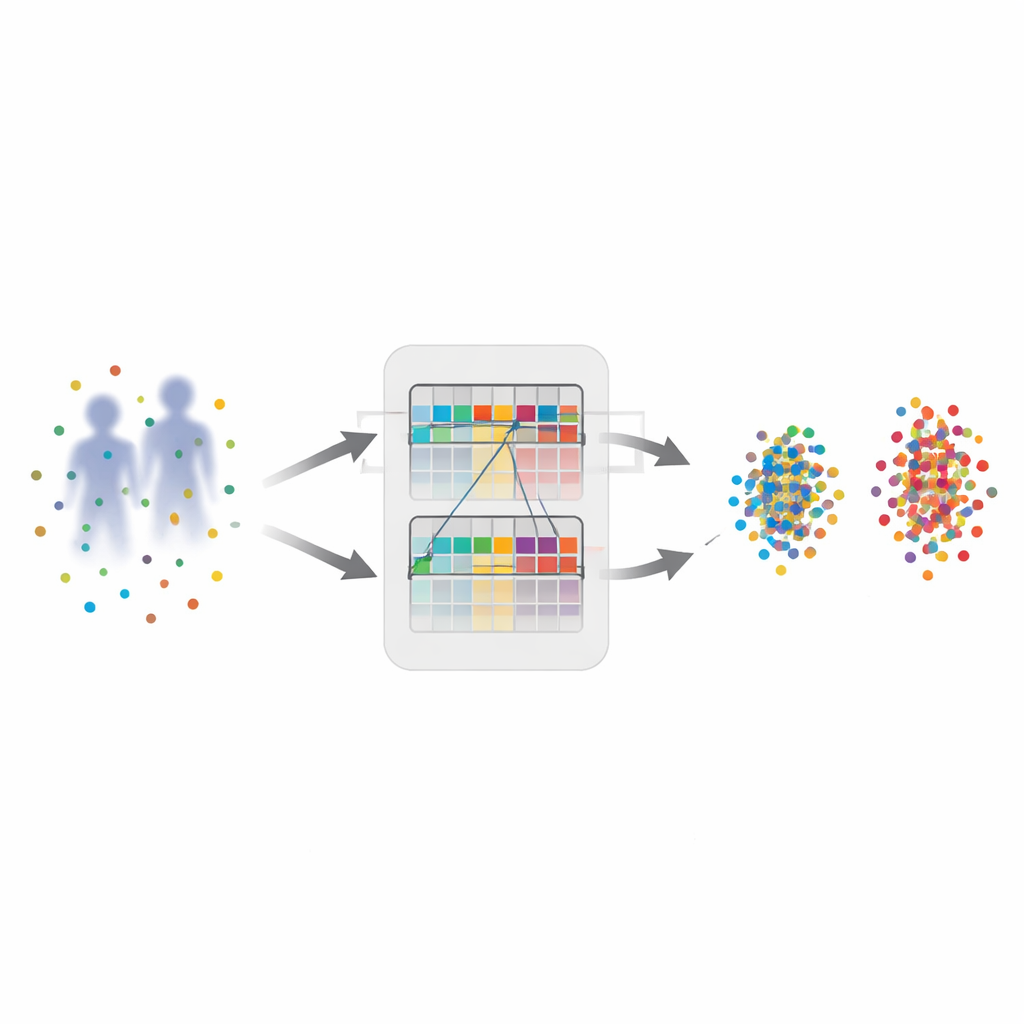
Pamiętanie zarówno różnic, jak i wspólnego gruntu
Drugą kluczową ideą jest „pamięć hybrydowa”, która przechowuje to, czego system dotychczas się nauczył. Tradycyjne metody utrzymują oddzielne pamięci dla obrazów widzialnych i podczerwonych, co dobrze rejestruje różnice, ale utrudnia wydobycie tego, co wspólne dla obu trybów. W tej pracy autorzy zachowują te dwie pamięci, a dodatkowo budują trzecią: pamięć mieszaną, która łączy najbardziej podobne przykłady z widzialnego i podczerwonego zbioru. Ta hybrydowa pamięć działa jak miejsce spotkań, zachęcając sieć do odkrywania cech osoby stabilnych niezależnie od warunków oświetleniowych i czujników — np. ogólny kształt sylwetki czy układ ubioru zamiast koloru. Trzeci element, adaptacyjne ważenie aktualizacji pamięci, nadaje większy wpływ nietypowym, lecz wiarygodnym przykładom i mniejszy przykładom dwuznacznym, dzięki czemu pamięć ewoluuje w kierunku ostrzejszych, bardziej globalnie użytecznych reprezentacji.
Sprawdzanie metody w praktyce
Zespół ocenia swoje podejście, nazwane Soft Smooth Contrastive Learning with Hybrid Memory (SCLHM), na trzech szeroko stosowanych zestawach danych zawierających zarówno materiał widzialny, jak i podczerwony zarejestrowany przez wiele kamer w realistycznych warunkach. Porównują swój system z wieloma istniejącymi metodami, w tym z tymi korzystającymi z pełnego oznakowania przez ludzi oraz z tymi pracującymi częściowo lub całkowicie bez etykiet. W całym spektrum SCLHM osiąga najlepsze wyniki wśród podejść bez etykiet, a w kilku przypadkach zbliża się do, a nawet rywalizuje z metodami opartymi na ręcznych adnotacjach. Dodatkowe eksperymenty wykazują, że każda z trzech części — miękkie wygładzanie, pamięć hybrydowa i adaptacyjne aktualizacje — wnosi istotny wkład w końcową dokładność.
Bardziej klarowny widok przez całą dobę
Dla szerokiego odbiorcy główne przesłanie jest takie, że autorzy opracowali sposób, dzięki któremu komputery potrafią same uczyć się rozpoznawania osób między kamerami dziennymi i nocnymi bez konieczności ludzkiego etykietowania, kto jest kim. Poprzez wygładzanie zawodnych przypuszczeń i ostrożne łączenie tego, co unikalne dla każdego rodzaju kamery, z tym, co wspólne, ich metoda uczy się stabilniejszych i bardziej ogólnych wzorców. To sprawia, że śledzenie osób w złożonych, słabo oświetlonych środowiskach jest dokładniejsze i bardziej skalowalne, co może przynieść korzyści w bezpieczeństwie, zarządzaniu ruchem i innych zastosowaniach wymagających niezawodnego, całodobowego monitorowania wizualnego.
Cytowanie: Zhang, C., Su, Y., Wang, N. et al. Soft smooth contrastive learning with hybrid memory for unsupervised visible-infrared person re-identification. Sci Rep 16, 13951 (2026). https://doi.org/10.1038/s41598-026-44364-0
Słowa kluczowe: re-identyfikacja osób, obrazowanie w podczerwieni, uczenie niesuperwizowane, uczenie kontrastowe, nadzór