Clear Sky Science · fr
Apprentissage contrastif doux et lisse avec mémoire hybride pour la ré-identification non supervisée personne visible-infrarouge
Voir les personnes dans l’obscurité
Les villes modernes sont couvertes de caméras, mais la plupart d’entre elles peinent la nuit ou par mauvais temps. Les caméras infrarouges, qui détectent la chaleur plutôt que la lumière visible, peuvent combler cette lacune. Le défi consiste à apprendre aux ordinateurs à reconnaître la même personne quand elle apparaît très différente sur une caméra diurne et sur une caméra thermique, et ce sans que des experts humains étiquettent des milliers d’images d’exemple. Cette étude propose une nouvelle façon d’apprendre automatiquement ces correspondances, rendant les systèmes de sécurité respectueux de la vie privée et opérationnels 24 h/24 plus pratiques.
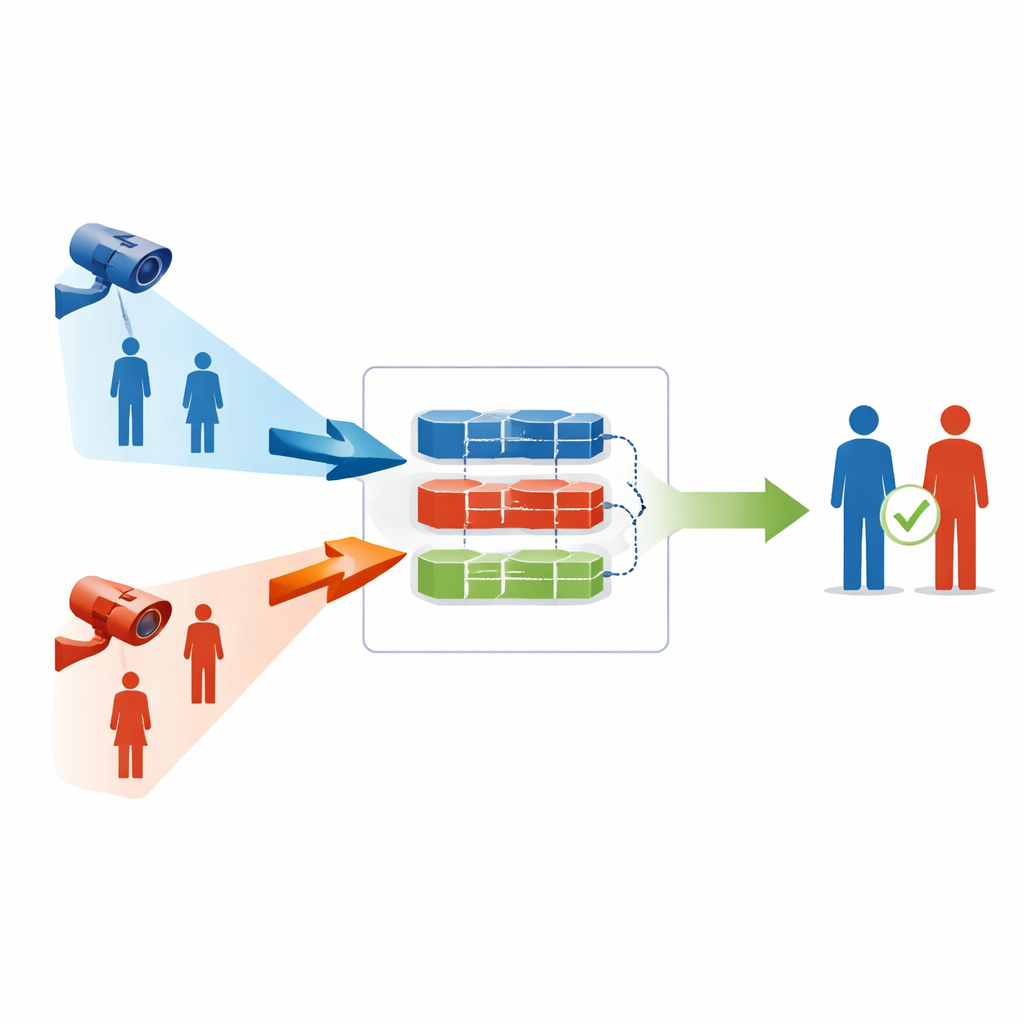
Faire correspondre des personnes entre deux mondes très différents
La ré-identification visible-infrarouge pose une question qui semble simple : étant donné une personne filmée par une caméra couleur ordinaire, peut-on retrouver la même personne dans des images issues d’une caméra infrarouge, ou inversement ? En pratique, les deux types d’images diffèrent par la couleur, le contraste et le niveau de détail, si bien que la description interne qu’en fait l’ordinateur peut diverger selon le type de caméra. Les systèmes antérieurs s’appuyaient souvent sur de larges jeux d’images annotées manuellement, où des humains indiquaient soigneusement quelles photos montraient le même individu. Cela coûte cher et prend du temps, en particulier pour des réseaux multi-caméras couvrant de vastes espaces comme des campus, des aéroports ou des quartiers.
Apprendre sans étiquettes humaines
Les auteurs se concentrent sur la version plus difficile « non supervisée » du problème, où aucune étiquette d’identité de référence n’est fournie. Au lieu de cela, l’ordinateur regroupe d’abord les images qui semblent similaires en clusters, traitant chaque groupe comme s’il représentait une même personne. Ces identités devinées sont appelées pseudo-étiquettes. Elles alimentent une stratégie d’entraînement populaire appelée apprentissage contrastif, où le modèle rapproche dans son espace interne les images d’un même cluster et écarte celles de clusters différents. Mais le clustering est loin d’être parfait : des personnes portant des vêtements similaires peuvent être confondues, et l’écart entre vues visibles et infrarouges introduit d’autres erreurs. Une fois que ces mauvaises hypothèses sont intégrées à l’entraînement, elles peuvent induire le modèle en erreur et réduire sa fiabilité.
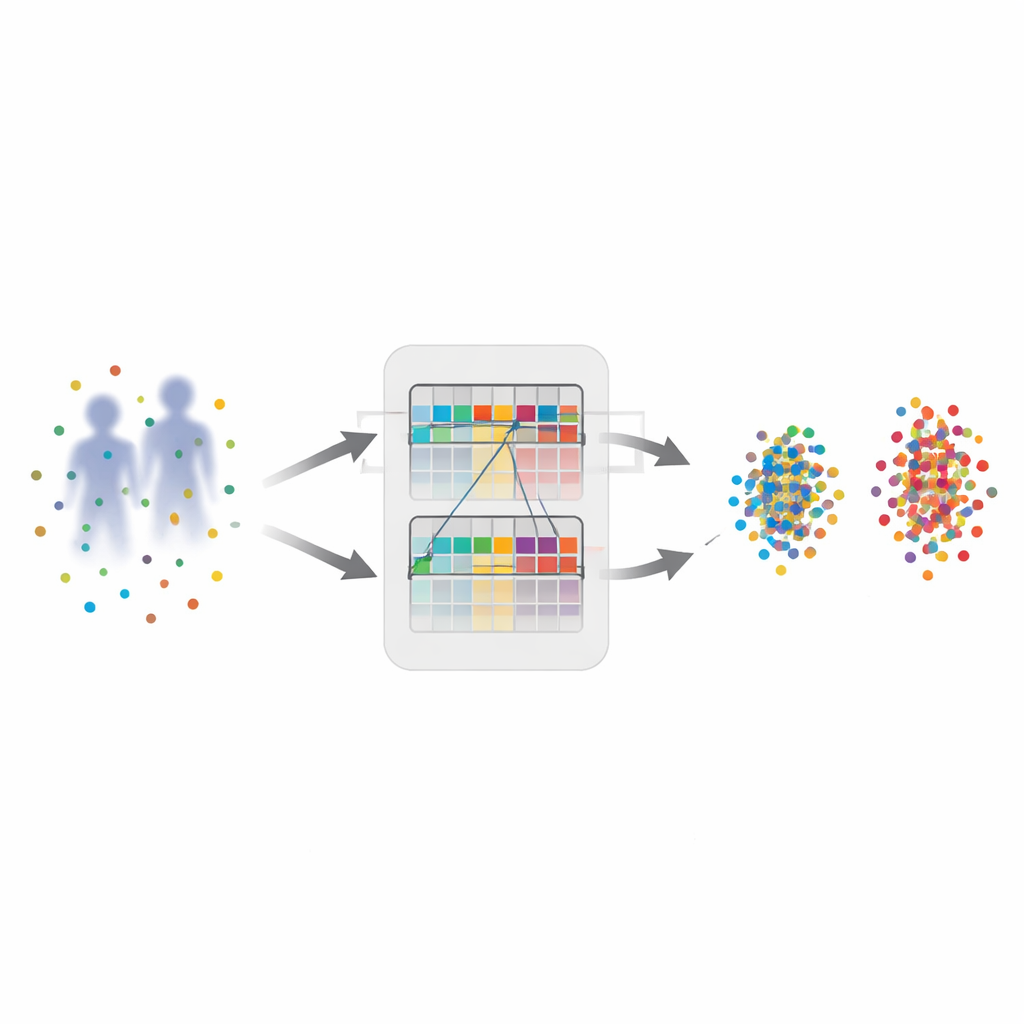
Lisser les devinettes bruitées
Pour maîtriser ces pseudo-étiquettes fautives, l’article introduit un schéma d’apprentissage contrastif « doux et lissé » qui utilise deux réseaux neuronaux coopératifs, un étudiant et un enseignant. L’étudiant est mis à jour de la manière habituelle pendant l’entraînement, tandis que l’enseignant est une moyenne lente des paramètres de l’étudiant. Pour chaque image, l’enseignant produit une évaluation de type probabiliste et graduelle de l’appartenance à chaque cluster, plutôt qu’une décision binaire stricte. Cette évaluation souple est ensuite mélangée avec l’affectation plus nette de l’étudiant. Le résultat est une cible lissée qui atténue les décisions incertaines et augmente l’influence des estimations plus fiables. En pratique, le modèle apprend à faire confiance aux tendances progressives au fil du temps plutôt qu’à réagir fortement à chaque mise à jour bruitée.
Se souvenir des différences et des éléments communs
La seconde idée clé est une « mémoire hybride » qui stocke ce que le système a appris jusqu’à présent. Les méthodes classiques maintiennent des mémoires séparées pour les images visibles et infrarouges, ce qui conserve les différences mais rend difficile l’extraction de ce qui est partagé entre les deux modalités. Ici, les auteurs conservent ces deux mémoires mais construisent aussi une troisième : une mémoire mixte qui combine les exemples visible et infrarouge les plus similaires. Cette mémoire hybride sert de lieu de convergence, encourageant le réseau à découvrir des caractéristiques d’une personne stables à travers conditions d’éclairage et capteurs, comme la silhouette générale ou la disposition des vêtements plutôt que la couleur. Un troisième mécanisme, la mise à jour adaptative des poids de la mémoire, donne plus d’influence aux exemples inhabituels mais fiables et moins aux exemples ambigus, de sorte que la mémoire évolue vers des représentations plus nettes et globalement utiles.
Mettre la méthode à l’épreuve
L’équipe évalue son approche, appelée Soft Smooth Contrastive Learning with Hybrid Memory (SCLHM), sur trois jeux de données largement utilisés qui incluent à la fois des séquences visibles et infrarouges collectées par plusieurs caméras en conditions réalistes. Ils comparent leur système à de nombreuses méthodes existantes, y compris certaines qui utilisent un étiquetage humain complet et d’autres qui fonctionnent avec des étiquettes partielles ou sans aucune. Dans l’ensemble, SCLHM atteint l’état de l’art parmi les approches sans étiquettes, et dans plusieurs cas se rapproche voire rivalise avec des méthodes reposant sur des annotations manuelles. Des expériences supplémentaires montrent que chacune des trois composantes — lissage doux, mémoire hybride et mise à jour adaptative — contribue de manière significative à la précision finale.
Une vision plus claire, 24 h/24
Pour le lecteur général, le message central est que les auteurs ont conçu un moyen pour les ordinateurs d’apprendre à reconnaître les personnes entre caméras diurnes et nocturnes sans exiger que des humains identifient qui est qui. En lissant les estimations peu fiables et en combinant soigneusement ce qui est spécifique à chaque type de caméra avec ce qu’elles partagent, leur cadre apprend des motifs plus stables et plus généraux. Cela rend le suivi des personnes dans des environnements complexes et faiblement éclairés plus précis et plus extensible, ce qui pourrait profiter à la sécurité, à la gestion du trafic et à d’autres applications dépendant d’une détection visuelle fiable et continue.
Citation: Zhang, C., Su, Y., Wang, N. et al. Soft smooth contrastive learning with hybrid memory for unsupervised visible-infrared person re-identification. Sci Rep 16, 13951 (2026). https://doi.org/10.1038/s41598-026-44364-0
Mots-clés: ré-identification de personnes, imagerie infrarouge, apprentissage non supervisé, apprentissage contrastif, surveillance