Clear Sky Science · ar
تعلم تبايني ناعم وسلس بذاكرة هجينة لإعادة تعريف الأشخاص مرئي–تحت-الأحمر بدون إشراف
رؤية الأشخاص في الظلام
تغطّي الكاميرات المدن الحديثة، لكن معظمها يعاني ليلاً أو في الطقس السيء. يمكن للكاميرات تحت الحمراء، التي تكتشف الحرارة بدلاً من الضوء المرئي، أن تسد هذه الفجوة. التحدي هو تعليم الحواسيب للتعرف على نفس الشخص عندما يبدو مختلفًا كثيرًا لكاميرا ضوئية وكاميرا حساسة للحرارة، وأن يتم ذلك دون أن يقوم خبراء بشرية بوضع تسميات لآلاف الصور. تقترح هذه الدراسة طريقة جديدة لتعلّم هذا المطابقة تلقائيًا، مما يجعل أنظمة الأمن العاملة على مدار الساعة وأكثر مراعاة للخصوصية أمرًا عمليًا أكثر.
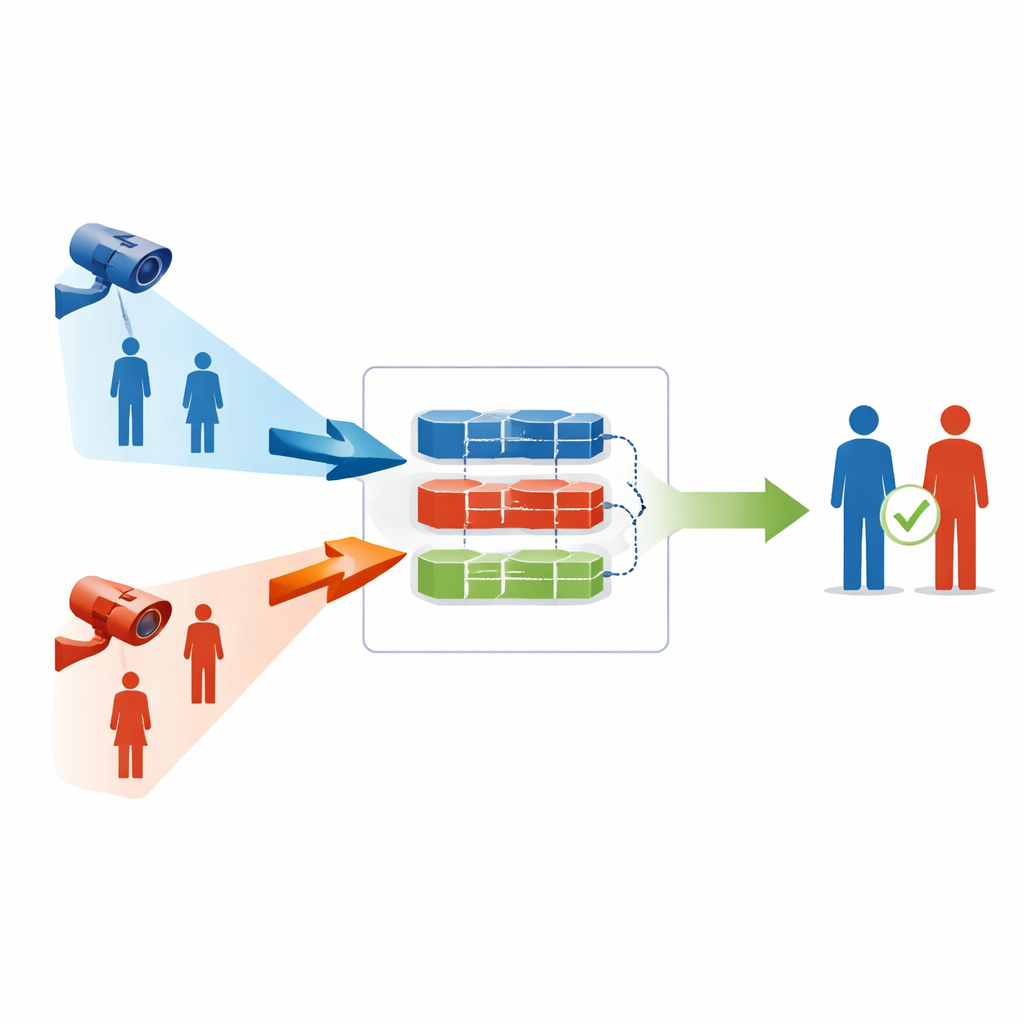
مطابقة الأشخاص عبر عالمين مختلفين للغاية
طرح مسألة إعادة تعريف الأشخاص عبر الرؤية المرئية–تحت-الحمراء سؤالًا يبدو بسيطًا: بالنظر إلى شخص رُصد بواسطة كاميرا ملونة عادية، هل يمكننا العثور على نفس الشخص في لقطات من كاميرا تحت حمراء، أو العكس؟ في الواقع، تختلف نوعا الصور من حيث اللون والتباين والتفاصيل، لذا يمكن أن تتباعد الوصافات الداخلية للحاسوب للشخص عبر نوعي الكاميرات. كانت الأنظمة السابقة تعتمد غالبًا على مجموعات كبيرة من الصور المعلّمة يدويًا، حيث يشير البشر بعناية إلى أي الصور تُظهر نفس الفرد. وهذا مكلف وبطيء، خصوصًا لشبكات كاميرات متعددة في أماكن واسعة مثل الحرم الجامعي أو المطارات أو صفوف الشوارع.
التعلّم بدون تسميات بشرية
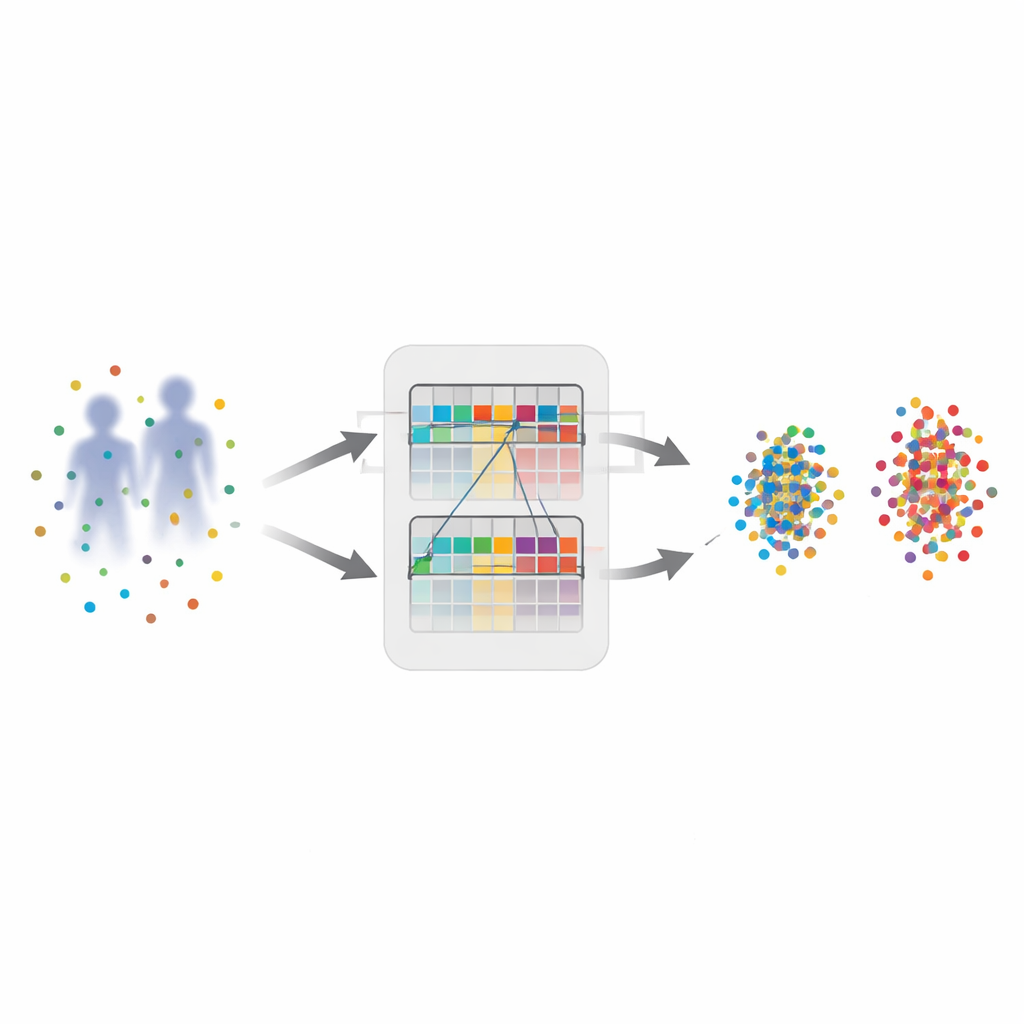
يركّز المؤلفون على النسخة الأصعب «بدون إشراف» من المشكلة، حيث لا تُقدّم تسميات هوية حقيقية. بدلاً من ذلك، يجمع الحاسوب أولًا الصور التي تبدو متشابهة في عناقيد، معاملة كل عنقود كما لو كان شخصًا واحدًا. تسمى هذه الهويات المتخمنة بالتسميات الوهمية. تُشغّل هذه التسميات استراتيجية تدريب شائعة تعرف باسم التعلم التبايني، حيث يسحب النموذج الصور من نفس العنقود لتقترب في تمثيله الداخلي ويدفع العناقيد المختلفة بعيدًا. لكن العنقدة بعيدة عن الكمال: قد تُخلط بين أشخاص يرتدون ملابس متشابهة، والفجوة بين الرؤية المرئية وتحت الحمراء تضيف أخطاء إضافية. ومتى ما تَرَسّخت هذه التخمينات الخاطئة في التدريب، يمكنها أن تضلّل النموذج وتقلّل من موثوقيته.
تنعيم التخمينات الصاخبة
لضبط هذه التسميات الوهمية المعيبة، يقدّم البحث مخططًا للتعلم التبايني «ناعم وسلس» يستخدم شبكتين عصبيتين متعاونتين، طالب ومعلم. يتم تحديث الطالب بالطريقة الاعتيادية أثناء التدريب، بينما يكون المعلم نسخة متحركة بطيئة من معلمات الطالب. لكل صورة، ينتج المعلم تقييما لطيفًا على شكل احتمالات عن مدى ملاءمتها لكل عنقود، بدلًا من قرار قاطع بنعم أو لا. ثم يتم مزج هذا التقييم الناعم مع تعيين العنقود الأكثر صرامة من الطالب. النتيجة هدف مُنعم يخفّف القرارات غير المؤكدة ويزيد تأثير القرارات الأكثر موثوقية. وعمليًا، يتعلم النموذج أن يثق في الاتجاهات التدريجية عبر الزمن بدلاً من الردّ بشكل حاد على كل تحديث صاخب.
تذكُّر الاختلافات والقواسم المشتركة معًا
الفكرة الرئيسية الثانية هي «ذاكرة هجينة» تخزن ما تعلّمه النظام حتى الآن. تحافظ الطرق التقليدية على ذاكرات منفصلة للصور المرئية وتلك تحت الحمراء، ما يواكب الاختلافات لكنه يصعب استخلاص ما هو مشترك بين النوعين. هنا يحتفظ المؤلفون بتلك الذاكرتين لكنهم يبنون أيضًا ذاكرة ثالثة: ذاكرة ممزوجة تدمج أمثلة مرئية وتحت حمراء الأكثر تشابهًا. تعمل هذه الذاكرة الهجينة كمكان لقاء، وتشجّع الشبكة على اكتشاف ميزات للشخص مستقرة عبر ظروف الإضاءة وأجهزة الاستشعار، مثل شكل الجسم العام أو توزيع الملابس بدلاً من اللون. مكوّن ثالث، تحديث الذاكرة بوزن تكيفي، يمنح تأثيرًا أكبر للأمثلة النادرة ولكن الموثوقة وأقل للأمثلة غير الواضحة، بحيث تتطور الذاكرة نحو تمثيلات أكثر حدة وفائدة على مستوى العالم.
اختبار الطريقة
يقيم الفريق نهجه، المسماة التعلم التبايني الناعم والسلس بذاكرة هجينة (SCLHM)، على ثلاث مجموعات بيانات مستخدمة على نطاق واسع تتضمن لقطات مرئية وتحت حمراء جُمعت بواسطة كاميرات متعددة في بيئات واقعية. يقارنون نظامهم بالعديد من الأساليب القائمة، بما في ذلك بعض التي تستخدم وضع تسميات بشرية كاملة وأخرى تعمل بتسميات جزئية أو بدون تسميات على الإطلاق. عبر اللوحة، يحقق SCLHM أداءً رفيع المستوى بين الأساليب الخالية من التسميات، وفي عدة حالات يقترب أو ينافس طرقًا تعتمد على التعليقات اليدوية. تُظهر تجارب إضافية أن كلًا من المكونات الثلاثة — التنعيم الناعم، الذاكرة الهجينة، والتحديث التكيفي — يساهم بشكل ملحوظ في الدقة النهائية.
رؤية أوضح على مدار الساعة
للقارئ العام، الرسالة الأساسية هي أن المؤلفين بنوا طريقة تتيح للحواسيب أن تتعلم بنفسها التعرف على الأشخاص عبر كاميرات نهارية وليلية دون أن يحتاج البشر إلى تسمية من هو من. عبر تنعيم التخمينات غير الموثوقة والجمع بعناية بين ما هو فريد لكل نوع كاميرا وما يشتركون فيه، يتعلم إطارهم أنماطًا أكثر استقرارًا وعمومية. هذا يجعُل تتبّع الأشخاص في بيئات معقدة ومنخفضة الإضاءة أكثر دقة وقابلية للتوسع، مما قد يفيد الأمن وإدارة المرور وتطبيقات أخرى تعتمد على استشعار بصري موثوق وعلى مدار الساعة.
الاستشهاد: Zhang, C., Su, Y., Wang, N. et al. Soft smooth contrastive learning with hybrid memory for unsupervised visible-infrared person re-identification. Sci Rep 16, 13951 (2026). https://doi.org/10.1038/s41598-026-44364-0
الكلمات المفتاحية: إعادة تعريف الأشخاص, التصوير بالأشعة تحت الحمراء, التعلم بدون إشراف, التعلم التبايني, المراقبة