Clear Sky Science · pl
Opracowanie i walidacja modelu uczenia maszynowego do indywidualizacji dawkowania meropenemu u pacjentów na CRRT
Dlaczego ma to znaczenie dla pacjentów na oddziale intensywnej terapii
Gdy u osób na intensywnej terapii pojawiają się zagrażające życiu zakażenia, lekarze często polegają na silnych antybiotykach i urządzeniach pełniących funkcję sztucznej nerki, aby utrzymać ich przy życiu. Jednak ustalenie właściwej dawki antybiotyku dla każdego pacjenta poddawanego ciągłemu dializopodobnemu leczeniu okazuje się zadaniem zaskakująco trudnym. Badanie pokazuje, jak narzędzie oparte na uczeniu maszynowym może pomóc lekarzom wybrać bezpieczniejsze i skuteczniejsze dawki szerokospektralnego antybiotyku meropenemu dla niektórych z najciężej chorych pacjentów w szpitalu.
Dylemat dawkowania przy uszkodzonych nerkach
Sepsa, ciężkie uogólnione zakażenie, często uszkadza nerki do takiego stopnia, że pacjenci wymagają ciągłej nerkozastępczej terapii (CRRT) — formy powolnej, całodobowej dializy. Meropenem jest powszechnie stosowany w leczeniu tych zakażeń, lecz jego farmakokinetyka ulega znacznym zmianom w przebiegu ciężkiej choroby. Przesunięcia płynów, niewydolność narządów i sam system CRRT wpływają na tempo usuwania leku. Zbyt niska dawka meropenemu grozi niepowodzeniem terapii i powstaniem oporności; zbyt wysoka zwiększa ryzyko działań niepożądanych, takich jak toksyczność neurologiczna i nerkowa. Tradycyjne wzory dawkowania oparte na przeciętnym pacjencie często zawodzą w przypadku osób, których fizjologia znacznie odbiega od normy.
Budowa wirtualnej populacji intensywnej terapii
Ponieważ duże, wysokiej jakości badania farmakokinetyczne u tak niestabilnych pacjentów są rzadkie, badacze najpierw stworzyli wirtualną populację 48 000 symulowanych pacjentów na CRRT, korzystając z istniejącego modelu farmakokinetycznego meropenemu. Dla każdego symulowanego pacjenta wariowali wiek, masę ciała, funkcję nerek, ustawienia CRRT, dawkę meropenemu, odstęp między dawkami, czas infuzji oraz „siłę” drobnoustrojów (podsumowaną jako najmniejsze stężenie hamujące, MIC). Następnie obliczali, czy każdy schemat dawkowania utrzymuje stężenia meropenemu wystarczająco wysokie we krwi przez cały okres między dawkami — zarówno dla standardowego progu (100% czasu powyżej MIC), jak i dla bardzo rygorystycznego (100% czasu powyżej czterech razy MIC), który uważa się za lepiej chroniący przed niepowodzeniem terapii i powstawaniem oporności.
Szkoleń maszyn do przewidywania powodzenia
Wykorzystując tych wirtualnych pacjentów, zespół trenował kilka typów modeli uczenia maszynowego, aby odpowiedzieć na proste pytanie tak/nie: czy konkretny pacjent, przy określonych ustawieniach CRRT i schemacie dawkowania, osiągnie pożądany cel ekspozycji na lek? Algorytmy takie jak lasy losowe, gradient boosting i drzewa decyzyjne uczyły się wzorców łączących cechy pacjenta, klirens przez CRRT, wielkość dawki, odstęp między dawkami, czas infuzji oraz MIC z prawdopodobieństwem sukcesu. W testach na danych symulowanych większość modeli osiągnęła wysoką dokładność, wiele poprawnie klasyfikowało wyniki w ponad 95% przypadków. Aby „rozjaśnić” czarną skrzynkę uczenia maszynowego, badacze zastosowali SHAP (Shapley Additive Explanations), by uszeregować, które dane wejściowe miały największe znaczenie. MIC drobnoustroju okazało się najsilniejszym czynnikiem, następnie częstość i wielkość dawek meropenemu oraz efektywność usuwania leku przez pacjenta i urządzenie CRRT.
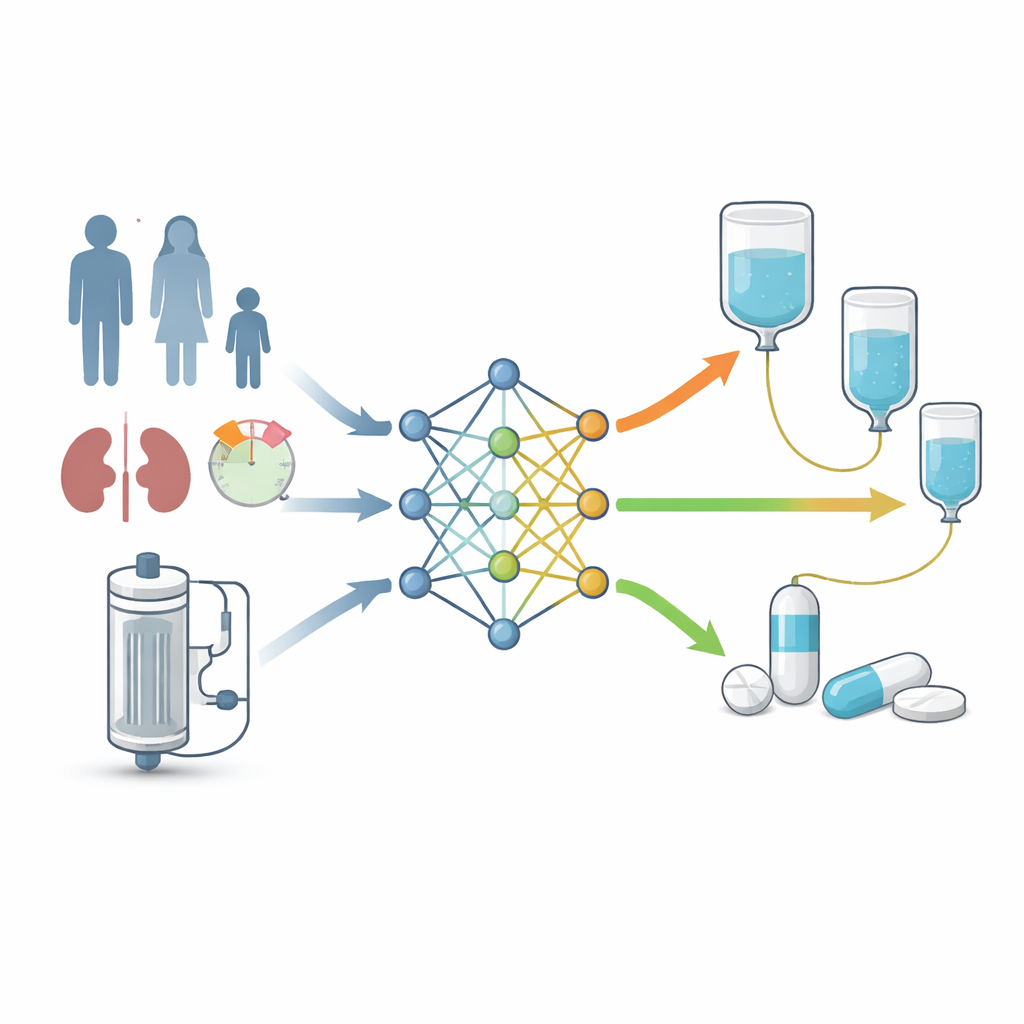
Testy w rzeczywistych warunkach i narzędzie przy łóżku pacjenta
Następnym krokiem było sprawdzenie, jak te modele sprawdzają się u rzeczywistych pacjentów. Autorzy wykorzystali dane od 78 ciężko chorych osób na różnych systemach CRRT, zebrane z dziewięciu opublikowanych badań. Dla każdego pacjenta tradycyjny model populacyjny odtwarzał szczegółowe krzywe stężeń leku, które służyły jako standard odniesienia dla oceny, czy dawkowanie osiągnęło rygorystyczne cele ekspozycji dla różnych możliwych wartości MIC. Gdy modele uczenia maszynowego proszono o przewidzenie tych samych wyników, używając wyłącznie cech pacjenta, ustawień CRRT i informacji o dawkowaniu, generalnie przewyższały one konwencjonalne podejście farmakokinetyczne. W szczególności model gradient boosting osiągnął lepszą zdolność dyskryminacji dla obu celów ekspozycji niż ustalony model. Najlepiej działający model został następnie osadzony w prostej aplikacji webowej o nazwie „MeroDose”, zbudowanej w ramach Streamlit.
Od złożonych danych do jaśniejszych wyborów
Przy łóżku pacjenta narzędzie MeroDose pozwala klinicystom wprowadzić podstawowe informacje o pacjencie, funkcję nerek, parametry CRRT, proponowaną dawkę i schemat meropenemu oraz przyjęte MIC. System natychmiast szacuje szansę, że dany schemat utrzyma stężenia leku wystarczająco wysokie przez cały interwał dawkowania, zarówno dla standardowych, jak i bardzo rygorystycznych celów. Choć nie zastępuje monitorowania poziomów we krwi ani oceny klinicznej, daje punkt wyjścia dostosowany do pacjenta zamiast uniwersalnej dawki. Badanie konkluduje, że to wsparcie oparte na uczeniu maszynowym może istotnie poprawić wybór początkowych dawek meropenemu u pacjentów na CRRT i wzywa do przeprowadzenia badań prospektywnych, które potwierdzą, czy takie narzędzia przekładają się na lepsze wyniki i mniej zakażeń opornych.
Cytowanie: Li, D., Qiao, Z., Xiong, X. et al. Development and validation of a machine learning model for individualised meropenem dosing in CRRT patients. Sci Rep 16, 12398 (2026). https://doi.org/10.1038/s41598-026-43012-x
Słowa kluczowe: sepsa, ciągła nerkozastępcza terapia, dawkowanie meropenemu, uczenie maszynowe w medycynie, wsparcie decyzji klinicznej