Clear Sky Science · nl
Ontwikkeling en validatie van een machine learning‑model voor geïndividualiseerde meropenemdosering bij CRRT‑patiënten
Waarom dit belangrijk is voor patiënten op de intensive care
Wanneer mensen op de intensive care levensbedreigende infecties krijgen, vertrouwen artsen vaak op krachtige antibiotica en kunstniermachines om hen in leven te houden. Toch is het bepalen van de juiste antibioticadosis voor elke patiënt die een continue dialyse‑achtige behandeling ondergaat verrassend ingewikkeld. Deze studie laat zien hoe een op machine learning gebaseerd hulpmiddel artsen kan helpen veiligere en effectievere doses van het breedspectrumantibioticum meropenem te kiezen voor enkele van de ernstigste patiënten in het ziekenhuis.
Het doseringsdilemma bij kwetsbare nieren
Sepsis, een ernstige lichaam brede infectie, beschadigt vaak de nieren zo ernstig dat patiënten continue niervervangende therapie (CRRT) nodig hebben — een vorm van langzame, continue dialyse. Meropenem wordt veel gebruikt voor de behandeling van deze infecties, maar het gedrag van het middel in het lichaam verandert sterk bij kritieke ziekte. Vloeistofverschuivingen, falende organen en het CRRT‑apparaat zelf beïnvloeden allemaal hoe snel het geneesmiddel wordt geklaard. Te weinig meropenem vergroot het risico op therapiefalen en antibioticaresistentie; te veel verhoogt de kans op bijwerkingen zoals neuro‑ en niertoxiteit. Traditionele doseringsformules die zijn gebaseerd op gemiddelde patiënten schieten vaak tekort voor individuen wiens fysiologie ver van normaal afwijkt.
Het opbouwen van een virtuele ic‑populatie
Aangezien grote, hoogwaardige geneesmiddelstudies bij zulke instabiele patiënten zeldzaam zijn, creëerden de onderzoekers eerst een virtuele populatie van 48.000 gesimuleerde CRRT‑patiënten met behulp van een bestaand farmacokinetisch model van meropenem. Voor elke gesimuleerde patiënt varieerden ze leeftijd, lichaamsgewicht, nierfunctie, CRRT‑instellingen, meropenemdosis, doseringsinterval, infusietijd en de weerbaarheid van de infectieuze bacterie (samengevat als de minimale remmende concentratie, of MIC). Daarna berekenden ze of elk doseringsplan de meropenemspiegels in het bloed gedurende de hele doseringsperiode hoog genoeg hield — zowel bij een standaarddrempel (100% van de tijd boven de MIC) als bij een zeer strikte (100% boven viermaal de MIC), waarvan men denkt dat die beter beschermt tegen therapiefalen en resistentie.
Machines trainen om succes te voorspellen
Met deze virtuele patiënten trainde het team verschillende typen machine learning‑modellen om een eenvoudige ja‑of‑nee‑vraag te beantwoorden: zal een bepaalde patiënt, met een specifieke CRRT‑instelling en doseringsschema, het gewenste geneesmiddelblootstellingsdoel bereiken? Algoritmen zoals random forests, gradient boosting en beslisbomen leerden patronen te koppelen tussen patiëntkenmerken, CRRT‑clearance, dosisgrootte, doseringsinterval, infusieduur en MIC en de kans op succes. Over de gesimuleerde testdata waren de meeste modellen zeer nauwkeurig, waarbij veel modellen in meer dan 95% van de gevallen uitkomsten correct classificeerden. Om de “black box” van machine learning te openen, gebruikten de onderzoekers SHAP (Shapley Additive Explanations) om te rangschikken welke invoerparameters het belangrijkst waren. Bacteriële MIC was de belangrijkste factor, gevolgd door hoe vaak en hoeveel meropenem werd toegediend en hoe efficiënt de patiënt en het CRRT‑apparaat het geneesmiddel verwijderden.
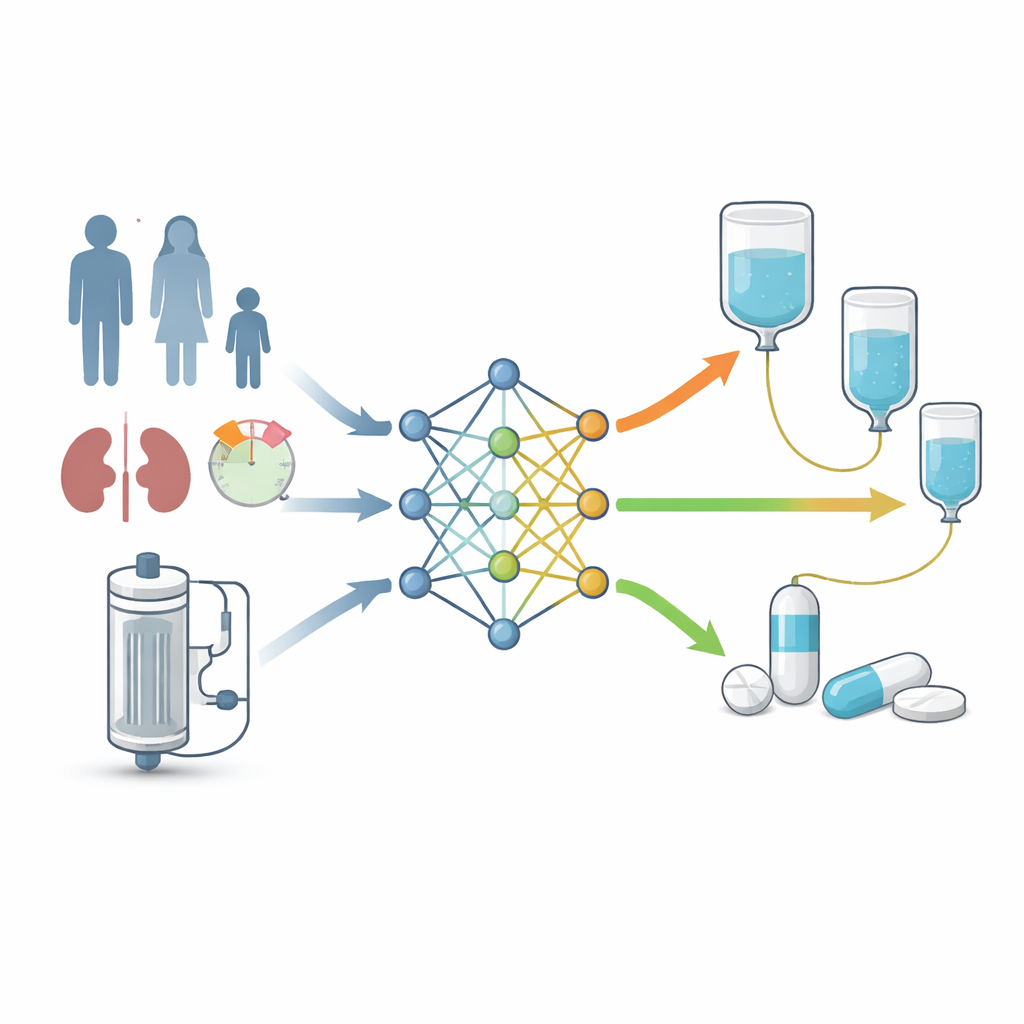
Testen in de echte wereld en een beddentaltool
De volgende stap was nagaan hoe deze modellen presteerden bij echte patiënten. De auteurs putten uit gegevens van 78 kritisch zieke personen op verschillende CRRT‑systemen, samengesteld uit negen gepubliceerde studies. Voor elke patiënt reconstrueerde een conventioneel populatiemodel gedetailleerde geneesmiddelconcentratiecurven, die als referentiestandaard dienden om te bepalen of de dosering de strikte blootstellingsdoelen behaalde over een reeks plausibele MIC‑waarden. Toen de machine learning‑modellen werd gevraagd dezelfde uitkomsten te voorspellen op basis van alleen patiëntkenmerken, CRRT‑instellingen en doseringsinformatie, presteerden ze over het algemeen beter dan de conventionele farmacokinetische benadering. Met name een gradient boosting‑model behaalde een hogere discriminatie voor beide blootstellingsdoelen dan het gevestigde model. Dit best presterende model werd vervolgens ingebed in een eenvoudige webapplicatie genaamd “MeroDose”, gebouwd met het Streamlit‑framework.
Van complexe data naar duidelijkere keuzes
Bij het bed kan de MeroDose‑tool clinici in staat stellen de basisgegevens van een patiënt, nierfunctie, CRRT‑parameters, voorgestelde meropenemdosis en -schema en een veronderstelde MIC in te voeren. Het systeem schat direct de kans dat dit regime de geneesmiddelspiegels gedurende het hele doseringsinterval hoog genoeg houdt, zowel voor het standaard‑ als het zeer strikte doel. Hoewel het geen bloedspiegelmonitoring of klinisch oordeel vervangt, biedt het een patiëntspecifiek vertrekpunt in plaats van een one‑size‑fits‑all‑dosering. De studie concludeert dat dit door machine learning aangestuurde ondersteuningssysteem zinvol kan verbeteren hoe initiële meropenemdoses worden gekozen voor CRRT‑patiënten, en pleit voor prospectieve trials om te bevestigen dat dergelijke hulpmiddelen leiden tot betere uitkomsten en minder resistente infecties.
Bronvermelding: Li, D., Qiao, Z., Xiong, X. et al. Development and validation of a machine learning model for individualised meropenem dosing in CRRT patients. Sci Rep 16, 12398 (2026). https://doi.org/10.1038/s41598-026-43012-x
Trefwoorden: sepsis, continue niervervangende therapie, meropenembesdosering, machine learning in de geneeskunde, klinische beslissingsondersteuning