Clear Sky Science · pl
Uczenie przepływów turbulentnych za pomocą modeli generatywnych do superrozdzielczości i rzadkiej rekonstrukcji przepływu
Czystsze filmy chaotycznych przepływów
Od silników odrzutowych po prądy oceaniczne — wiele rzeczywistych przepływów ma charakter wysoce chaotyczny. Ujęcie tych turbulentnych ruchów z wystarczającą szczegółowością jest kluczowe dla bezpieczniejszych samolotów, bardziej wydajnych silników i lepszych prognoz klimatycznych, ale tradycyjne symulacje lub ultraprędkie kamery są niezwykle kosztowne. W artykule pokazano, jak nowe narzędzia AI mogą uzupełnić brakujące szczegóły, przekształcając rozmyte lub niekompletne migawki turbulencji w ostre, szybkobieżne filmy — i robiąc to wystarczająco szybko, by było użyteczne w eksperymentach i projektowaniu inżynierskim.
Dlaczego turbulencję tak trudno uchwycić
Przepływy turbulentne obfitują w wiry o rozmiarach od dużych, rozległych struktur po maleńkie, szybko zmieniające się zawirowania. Standardowe modele komputerowe rozwiązujące podstawowe równania ruchu muszą śledzić wszystkie te skale, co wymaga niezwykle gęstych siatek i bardzo małych kroków czasowych. To sprawia, że symulacje o wysokiej wierności i pomiary są powolne, kosztowne i wymagające danych. Nowsza klasa modeli AI, zwana operatorami neuronowymi, może z zasady nauczyć się, jak całe pole przepływu ewoluuje w czasie, pomijając wiele drobnych kroków. Jednak trenowane w tradycyjny sposób — przez minimalizację średniego błędu kwadratowego — mają tendencję do wygładzania ostrych detali, które są najważniejsze w turbulencji.
Połączenie dwóch pomysłów AI, by zachować drobne detale
Autorzy łączą operatory neuronowe z modelowaniem generatywnym, podejściem lepiej znanym z tworzenia realistycznych obrazów, aby zachować drobną strukturę chaotycznych przepływów. Projektują „adwersarialnie trenowany operator neuronowy”, który wciąż uczy się dopasowywać ogólny przebieg pola, ale jest też popychany przez drugą sieć — dyskryminator — do wytwarzania wyników statystycznie nieodróżnialnych od rzeczywistych pól turbulentnych. Taka konfiguracja zachęca model nie tylko do bycia bliskim w średniej, lecz także do odtwarzania poprawnego rozkładu ostrych gradientów i małych zawirowań. Matematyczna analiza rozkładu błędu treningowego w różnych skalach przestrzennych wyjaśnia, dlaczego zwykłe metody niedoważają składowych o wysokiej częstotliwości, i pokazuje, jak nowa strategia treningowa przeciwdziała temu uprzedzeniu.
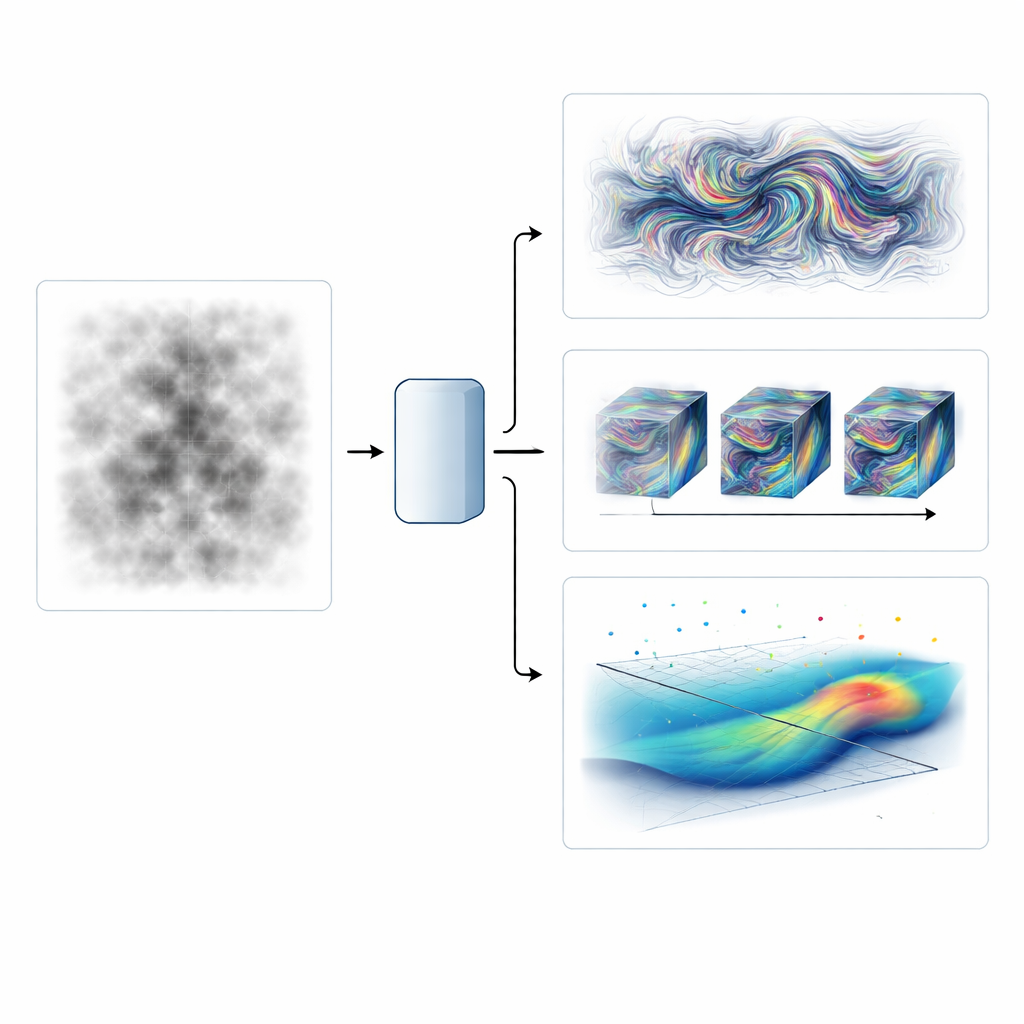
Przekształcanie rozmytych i powolnych obrazów w szybkie i ostre
Pierwszy test koncentruje się na obrazach Schlieren — szybkich zdjęciach wizualizujących zmiany gęstości w dżecie naddźwiękowym uderzającym w płaską płytę. Zespół trenuje swój operator neuronowy, by przemieniać grube, niskoczęstotliwościowe filmy w sekwencje o wysokiej rozdzielczości i dużej liczbie klatek na sekundę, odzyskując zarówno drobniejsze detale przestrzenne, jak i pominięte kroki czasowe. Porównują kilka strategii: zwykły operator neuronowy, ich adwersarialną wersję oraz kombinacje, w których oddzielny model generatywny oczyszcza nadmiernie wygładzony wynik zwykłego operatora. Operator trenowany adwersarialnie wyróżnia się odtwarzaniem poprawnego rozkładu energii w skali oraz uchwyceniem ostrych struktur fal uderzeniowych, przy niemal takim samym koszcie obliczeniowym jak model podstawowy. Bardziej rozbudowane dodatki generatywne mogą dorównać jakości spektralnej, ale są znacznie droższe obliczeniowo.
Szybkie prognozy i odbudowa przepływów z rzadkich pomiarów
Drugi test polega na prognozowaniu w pełni trójwymiarowej, jednorodnej izotropowej turbulencji — standardowego poligonu do badania kaskad energii w cieczach. Co zaskakujące, autorzy trenują na zaledwie 160 migawkach czasowych z jednej symulacji i mimo to prognozują na kilka dużych czasów obrotu w przyszłość. W porównaniu zarówno ze standardowym operatorem neuronowym, jak i z wersją ograniczoną do zachowania masy, operator trenowany adwersarialnie dłużej utrzymuje poprawną zawartość małych skal i wzorce statystyczne. Pokonuje też najnowocześniejszy model generatywny oparty na dyfuzji pod względem szybkości wnioskowania o ponad dwie rzędy wielkości, osiągając jednocześnie lepszą strukturę i statystyki w tym reżimie o niskiej liczbie danych.
Odtworzenie pełnego pola przepływu z garstki punktów danych
Trzecie wyzwanie jest jeszcze bardziej wymagające: rekonstrukcja pełnych trójwymiarowych pól prędkości i ciśnienia za cylindrem na podstawie wyjątkowo rzadkich pomiarów przypominających śledzenie cząstek. Tutaj problem nie polega na prognozowaniu w czasie, lecz na wywnioskowaniu najbardziej prawdopodobnego całego pola zgodnego z rozproszonym zbiorem obserwacji. Autorzy trenują warunkowe modele generatywne, które, mając dane częściowe i maskę wskazującą, gdzie istnieją pomiary, próbkują kompletne pola przepływu. Model oparty na dyfuzji niezawodnie odzyskuje spójne wzory wirów, pola ciśnienia i poprawne statystyki nawet wtedy, gdy niemal wszystkie punkty są brakujące, i potrafi się dostosować bez ponownego treningu do różnych układów pomiarowych. Z kolei konwencjonalny generator adwersarialny zawodząc przy bardzo rzadkich danych.
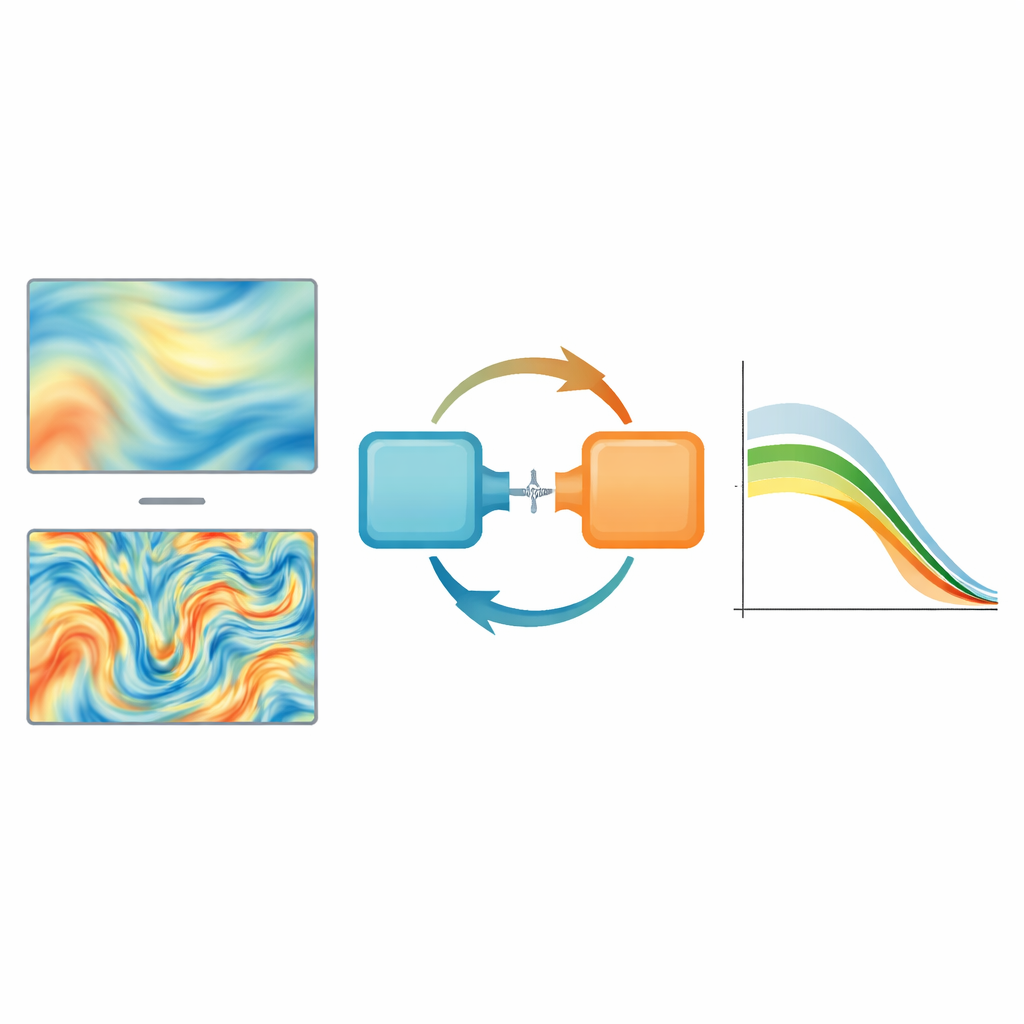
Przybliżenie turbulencji w czasie rzeczywistym
Podsumowując, badanie pokazuje, że łączenie uczenia operatorów z pomysłami generatywnymi może przezwyciężyć długotrwałe słabości modeli AI opisujących turbulencję, zwłaszcza ich skłonność do wymazywania struktur małej skali. Powstałe narzędzia potrafią wyostrzyć i przyspieszyć wizualizacje przepływów, prognozować złożoną, trójwymiarową turbulencję daleko w przyszłość używając bardzo niewielu danych treningowych oraz rekonstruować niemal kompletne pola z ograniczonych pomiarów eksperymentalnych. Postępy te wskazują na przyszłość, w której wysokowiernościowa, niemal w czasie rzeczywistym analiza i sterowanie przepływami turbulentnymi będą możliwe bez zaporowych kosztów tradycyjnych symulacji lub specjalistycznego sprzętu.
Cytowanie: Oommen, V., Khodakarami, S., Bora, A. et al. Learning turbulent flows with generative models for super resolution and sparse flow reconstruction. Nat Commun 17, 3707 (2026). https://doi.org/10.1038/s41467-026-70145-4
Słowa kluczowe: turbulencja, modele generatywne, operatory neuronowe, super-rozdzielczość, rekonstrukcja przepływu