Clear Sky Science · de
Erlernen turbulenter Strömungen mit generativen Modellen für Superauflösung und spärliche Strömungsrekonstruktion
Scharfere Filme chaotischer Strömungen
Von Düsentriebwerken bis zu Meeresströmungen sind viele Strömungen in der realen Welt hochgradig chaotisch. Diese turbulenten Bewegungen in ausreichendem Detail zu erfassen, ist entscheidend für sicherere Flugzeuge, sauberere Triebwerke und bessere Klimavorhersagen, aber mit herkömmlichen Simulationen oder ultraschnellen Kameras ist das extrem kostenintensiv. Diese Arbeit zeigt, wie neue KI-Werkzeuge fehlende Details ergänzen können, verschwommene oder unvollständige Schnappschüsse der Turbulenz in scharfe, hochfrequente Filme verwandeln und das schnell genug, um in Experimenten und beim technischen Design nützlich zu sein.
Warum Turbulenz so schwer zu erfassen ist
Turbulente Strömungen sind voller Wirbelbewegungen, die von großen, weitreichenden Eddies bis zu winzigen, schnell wechselnden Wirbeln reichen. Standard-Computermodelle, die die zugrunde liegenden Bewegungsgleichungen lösen, müssen all diese Skalen verfolgen, was extrem feine Gitter und sehr kleine Zeitschritte erfordert. Das macht hochauflösende Simulationen und Messungen langsam, teuer und datenhungrig. Eine neuere Klasse von KI-Modellen, sogenannte neuronale Operatoren, kann prinzipiell lernen, wie ein gesamtes Strömungsfeld sich über die Zeit entwickelt, und dabei viele der kleinen Zwischenschritte überspringen. Wenn sie jedoch auf übliche Weise trainiert werden — durch Minimierung des mittleren quadratischen Fehlers — neigen sie dazu, die scharfen Details zu glätten, die in der Turbulenz am bedeutsamsten sind.
Zwei KI-Ideen kombinieren, um feine Details zu bewahren
Die Autoren kombinieren neuronale Operatoren mit generativem Modeling, einem Ansatz, der eher für die Erzeugung realistischer Bilder bekannt ist, um die feine Struktur chaotischer Strömungen zu bewahren. Sie entwerfen einen „adversarial trainierten neuronalen Operator“, der zwar weiterhin lernt, das gesamte Strömungsbild anzunähern, aber durch ein zweites Netzwerk — einen Diskriminator — dazu gedrängt wird, Ausgaben zu erzeugen, die statistisch nicht von echten turbulenten Feldern zu unterscheiden sind. Diese Konstellation veranlasst das Modell, nicht nur im Durchschnitt nah zu liegen, sondern auch die richtige Verteilung scharfer Gradienten und kleiner Wirbel nachzubilden. Eine mathematische Analyse der Verteilung des Trainingsfehlers über verschiedene räumliche Skalen erklärt, warum gewöhnliche Methoden hochfrequente Inhalte untergewichten, und zeigt, wie die neue Trainingsstrategie diesem Bias entgegenwirkt.
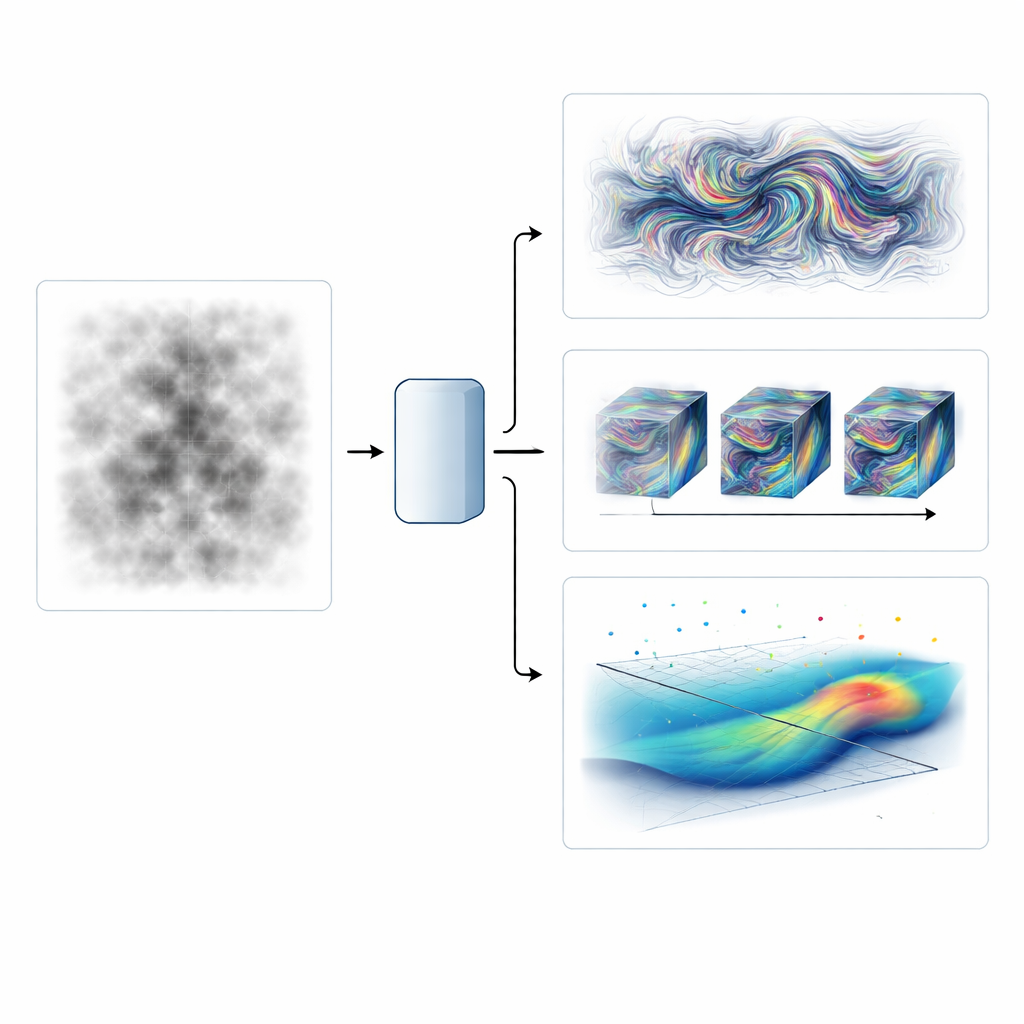
Verschwommene und langsame Bilder scharf und hochfrequent machen
Der erste Test konzentriert sich auf Schlierenaufnahmen — hochgeschwindigkeitsaufnahmen, die Dichteänderungen in einem Überschallstrahl sichtbar machen, der auf eine Platte trifft. Das Team trainiert seinen neuronalen Operator darauf, grobe, niedrig-bildfrequente Filme in hochauflösende, hochbildfrequente Sequenzen umzuwandeln und so sowohl feinere räumliche Details als auch übersprungene Zeitschritte zu rekonstruieren. Sie vergleichen mehrere Strategien: einen einfachen neuronalen Operator, ihre adversarial Variante und Kombinationen, bei denen ein separates generatives Modell die übermäßig geglätteten Ausgaben des einfachen Operators bereinigt. Der adversarial trainierte Operator sticht hervor, indem er die korrekte Energieverteilung über die Skalen reproduziert und scharfe Stoßstrukturen einfängt, während er nahezu gleich schnell läuft wie das einfache Modell. Aufwendigere generative Ergänzungen können zwar die spektrale Qualität erreichen, sind aber deutlich rechenintensiver.
Schnelle Vorhersagen und Wiederaufbau von Strömungen aus spärlichen Messungen
Der zweite Test lässt das Modell vollständig dreidimensionale homogene isotrope Turbulenz vorhersagen, ein Standard-Testfeld zur Untersuchung von Energiekaskaden in Fluiden. Überraschenderweise trainieren die Autoren mit nur 160 Zeitschnappschüssen aus einer einzigen Simulation und sagen dennoch mehrere große Umlaufzeiten in die Zukunft voraus. Im Vergleich zu einem Standard-neuronalen Operator und einer Version, die zusätzlich die Massenerhaltung erzwingt, bewahrt der adversarial trainierte Operator länger den korrekten Kleinskaleninhalt und die statistischen Muster. Außerdem übertrifft er ein hochmodernes, diffusionsbasiertes generatives Modell in der Inferenzgeschwindigkeit um mehr als zwei Größenordnungen, während er in diesem datenarmen Regime bessere Struktur und Statistik liefert.
Das vollständige Strömungsfeld aus wenigen Datenpunkten rekonstruieren
Die dritte Herausforderung ist noch anspruchsvoller: die Rekonstruktion des vollständigen dreidimensionalen Geschwindigkeits- und Druckfelds des Schweifs hinter einem Zylinder aus extrem spärlichen, partikelverfolgungsähnlichen Messungen. Hier geht es nicht um zeitliche Vorhersage, sondern darum, das plausibelste gesamte Strömungsfeld zu erschließen, das mit einer verstreuten Menge von Beobachtungen konsistent ist. Die Autoren trainieren konditionale generative Modelle, die, gegeben teilweiser Daten und einer Maske, die angibt, wo Messwerte existieren, vollständige Strömungsfelder sampeln. Ein diffusionsbasiertes Modell stellt zuverlässig kohärente Wirbelmuster, Druckfelder und korrekte Statistiken wieder her, selbst wenn fast alle Punkte fehlen, und kann sich ohne erneutes Training an unterschiedliche Messaufstellungen anpassen. Ein konventioneller adversarial Generator hingegen versagt, wenn die Daten zu spärlich werden.
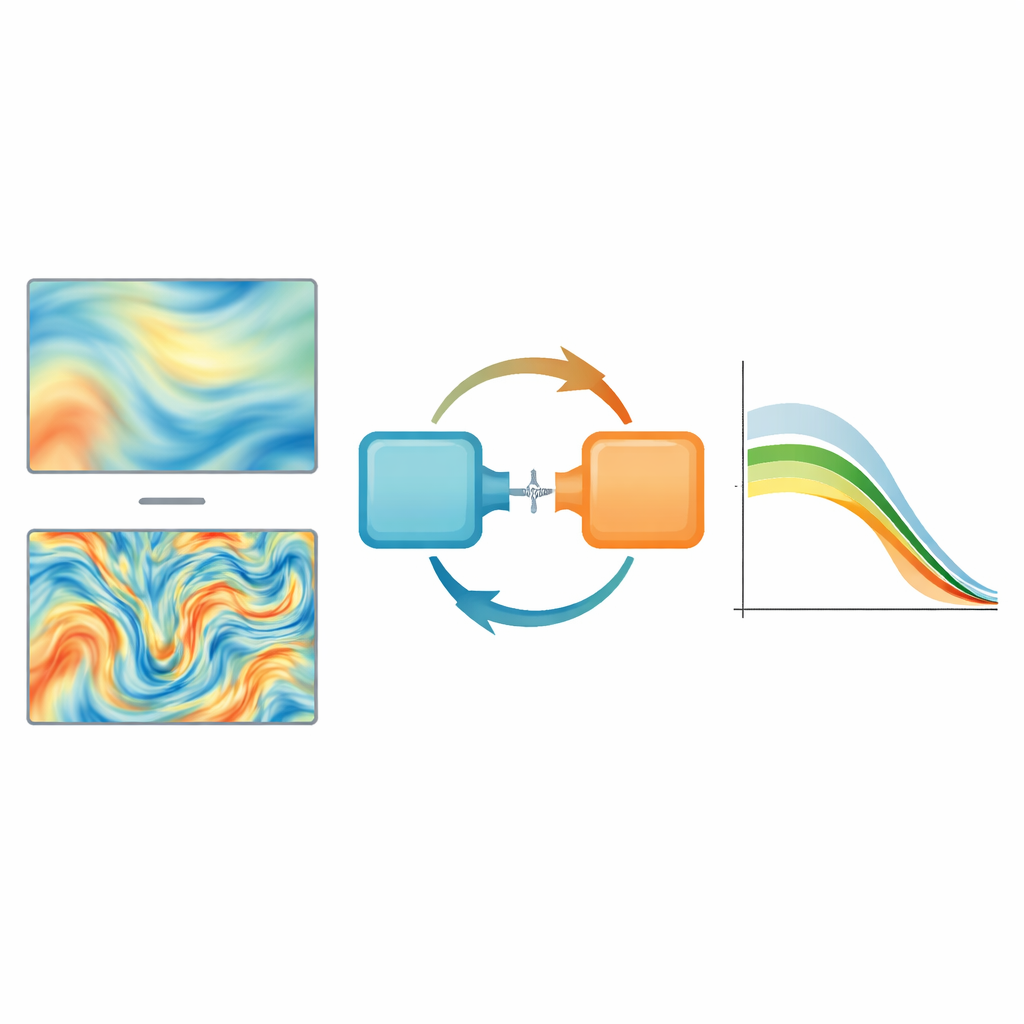
Echtzeitfähige Turbulenz in Reichweite bringen
Insgesamt zeigt die Studie, dass die Kombination von Operator-Lernen mit generativen Ideen langjährige Schwächen von KI-Modellen für Turbulenz überwinden kann, insbesondere deren Tendenz, kleinräumige Strukturen zu verwischen. Die resultierenden Werkzeuge können Strömungsvisualisierungen schärfen und beschleunigen, komplexe dreidimensionale Turbulenz mit sehr wenig Trainingsdaten weit in die Zukunft vorhersagen und nahezu vollständige Felder aus begrenzten experimentellen Messungen rekonstruieren. Diese Fortschritte deuten auf eine Zukunft hin, in der hochauflösende, nahezu in Echtzeit mögliche Analyse und Steuerung turbulenter Strömungen ohne die prohibitiven Kosten traditioneller Simulationen oder spezialisierter Hardware möglich wird.
Zitation: Oommen, V., Khodakarami, S., Bora, A. et al. Learning turbulent flows with generative models for super resolution and sparse flow reconstruction. Nat Commun 17, 3707 (2026). https://doi.org/10.1038/s41467-026-70145-4
Schlüsselwörter: Turbulenz, generative Modelle, neuronale Operatoren, Superauflösung, Strömungsrekonstruktion