Clear Sky Science · en
Learning turbulent flows with generative models for super resolution and sparse flow reconstruction
Sharper Movies of Chaotic Flows
From jet engines to ocean currents, many real-world flows are wildly chaotic. Capturing these turbulent motions in enough detail is crucial for safer planes, cleaner engines and better climate forecasts, but doing so with traditional simulations or ultra-fast cameras is extremely costly. This paper shows how new AI tools can fill in the missing details, turning blurry or incomplete snapshots of turbulence into sharp, high-speed movies, and doing it fast enough to be useful in experiments and engineering design.
Why Turbulence Is So Hard to Capture
Turbulent flows are full of swirling motions that range from large, sweeping eddies down to tiny, rapidly changing whirls. Standard computer models that solve the underlying equations of motion must track all of these scales, which demands extremely fine grids and very small time steps. That makes high-fidelity simulations and measurements slow, expensive and data-hungry. A newer class of AI models called neural operators can, in principle, learn how an entire flow field evolves over time, skipping many of the tiny steps. But when they are trained in the usual way—by minimizing average squared error—they tend to smooth out the sharp details that matter most in turbulence.
Blending Two AI Ideas to Keep Fine Detail
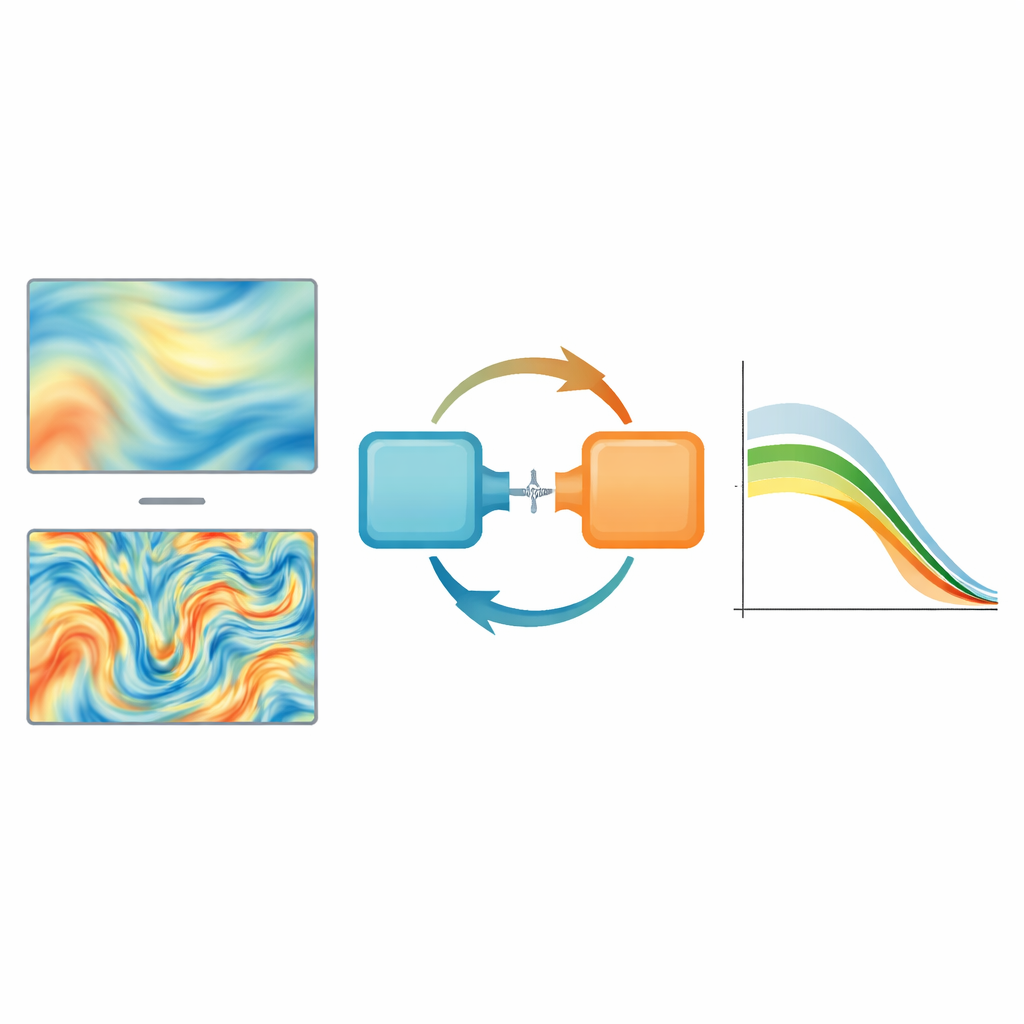
The authors combine neural operators with generative modeling, an approach better known for creating realistic images, to preserve the fine structure of chaotic flows. They design an “adversarially trained neural operator” that still learns to match the overall flow but is also nudged by a second network, a discriminator, to produce outputs that look statistically indistinguishable from real turbulent fields. This setup encourages the model not only to be close on average but also to reproduce the correct distribution of sharp gradients and small eddies. A mathematical analysis of how the training error is distributed across different spatial scales explains why ordinary methods underweight the high-frequency content, and shows how the new training strategy counters that bias.
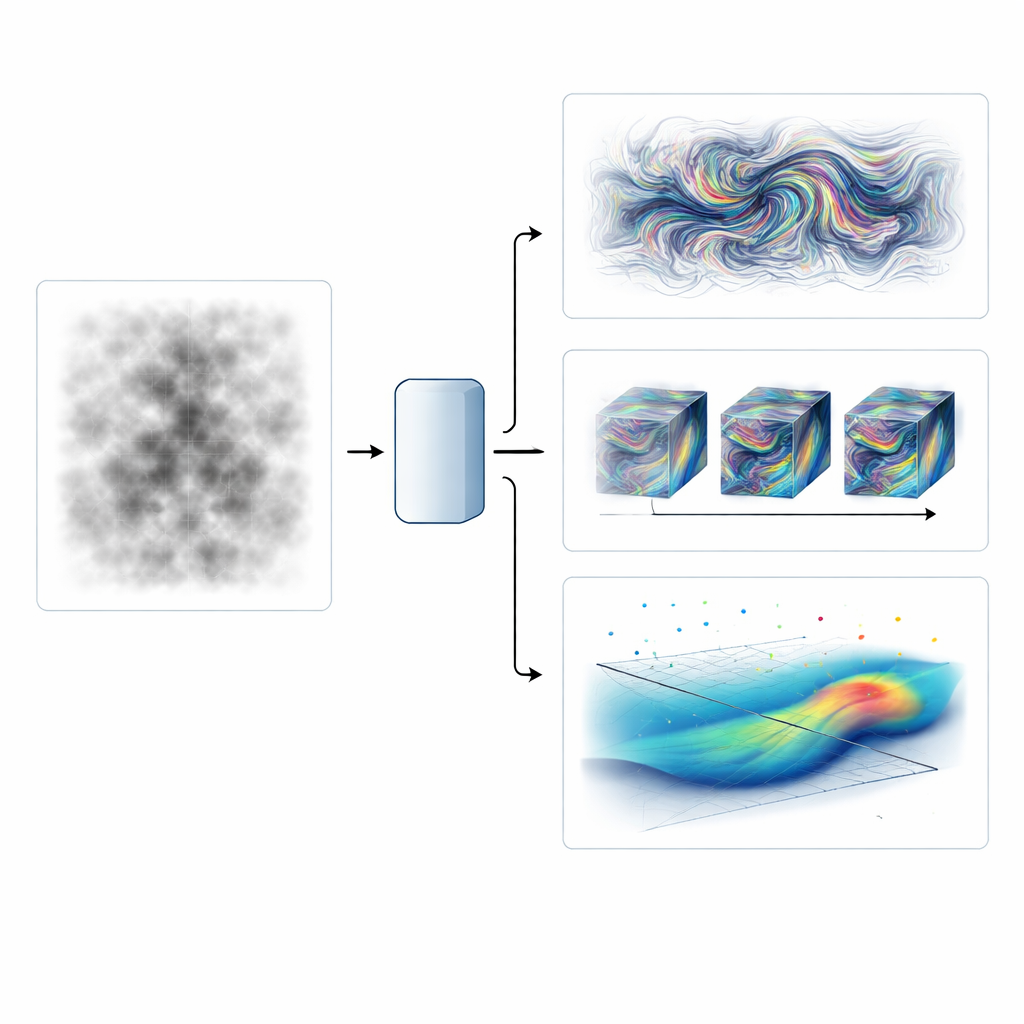
Making Blurry and Slow Images Look High-Speed and Sharp
The first test focuses on Schlieren images—high-speed pictures that visualize density changes in a supersonic jet hitting a flat plate. The team trains their neural operator to turn coarse, low-frame-rate movies into high-resolution, high-frame-rate sequences, recovering both finer spatial details and skipped time steps. They compare several strategies: a plain neural operator, their adversarial version, and combinations where a separate generative model cleans up the plain operator’s over-smoothed output. The adversarially trained operator stands out by reproducing the correct distribution of energy across scales and capturing crisp shock structures, while costing almost the same to run as the plain model. More elaborate generative add-ons can match the spectral quality but are far more computationally expensive.
Fast Forecasts and Rebuilding Flows from Sparse Measurements
The second test asks the model to forecast fully three-dimensional homogeneous isotropic turbulence, a standard playground for studying energy cascades in fluids. Remarkably, the authors train on just 160 time snapshots from a single simulation and still forecast several large turnover times into the future. Compared with both a standard neural operator and a version constrained to obey mass conservation, the adversarially trained operator keeps the correct small-scale content and statistical patterns for longer times. It also beats a state-of-the-art diffusion-based generative model by over two orders of magnitude in inference speed while achieving better structure and statistics in this low-data regime.
Recreating the Full Flow from a Handful of Data Points
The third challenge is even more demanding: reconstructing the full three-dimensional velocity and pressure fields of the wake behind a cylinder from extremely sparse, particle-tracking-like measurements. Here the problem is not forecasting in time but inferring the most plausible entire flow consistent with a scattered set of observations. The authors train conditional generative models that, given partial data and a mask that indicates where measurements exist, sample complete flow fields. A diffusion-based model reliably recovers coherent vortex patterns, pressure fields and correct statistics even when nearly all points are missing, and can adapt without retraining to different measurement layouts. A conventional adversarial generator, by contrast, breaks down when the data become too sparse.
Bringing Real-Time Turbulence Within Reach
Overall, the study shows that pairing operator learning with generative ideas can overcome long-standing weaknesses in AI models of turbulence, especially their tendency to erase small-scale structure. The resulting tools can sharpen and speed up flow visualizations, forecast complex three-dimensional turbulence far into the future using very little training data, and reconstruct nearly complete fields from limited experimental measurements. These advances point toward a future where high-fidelity, near-real-time analysis and control of turbulent flows is possible without the prohibitive cost of traditional simulations or specialized hardware.
Citation: Oommen, V., Khodakarami, S., Bora, A. et al. Learning turbulent flows with generative models for super resolution and sparse flow reconstruction. Nat Commun 17, 3707 (2026). https://doi.org/10.1038/s41467-026-70145-4
Keywords: turbulence, generative models, neural operators, super-resolution, flow reconstruction