Clear Sky Science · nl
Een nieuwe digital-twinstrategie om de implicaties van gerandomiseerde klinische onderzoeken voor echte populaties te onderzoeken
Waarom dit belangrijk is voor gewone patiënten
Wanneer artsen de resultaten van een groot klinisch onderzoek lezen, blijft een knagende vraag bestaan: gelden deze uitkomsten ook echt voor de patiënten die voor mij zitten? Deze studie introduceert een nieuwe manier om die vraag te beantwoorden met "digitale tweelingen" van klinische onderzoeken — computergemaakte kopieën van echte studies die opnieuw kunnen worden gedraaid binnen andere patiëntpopulaties, inclusief groepen afkomstig uit elektronische medische dossiers. Het werk richt zich op bloeddrukonderzoeken, maar de benadering zou uiteindelijk kunnen helpen om bewijs uit vrijwel elk onderzoek af te stemmen op de mensen die daadwerkelijk in klinieken en ziekenhuizen verschijnen.
Het probleem van one-size-fits-all-onderzoeken
Gerandomiseerde klinische onderzoeken zijn de gouden standaard om vast te stellen of een behandeling werkt, maar ze worden meestal uitgevoerd in zorgvuldig geselecteerde patiëntgroepen. Veel alledaagse patiënten — oudere volwassenen, mensen met meerdere aandoeningen of personen uit ondervertegenwoordigde groepen — lijken mogelijk niet op de vrijwilligers uit de oorspronkelijke onderzoeken. Daardoor moeten artsen vaak gokken hoeveel ze de onderzoeksresultaten kunnen vertrouwen voor hun eigen patiënten. Dit probleem wordt extra nijpend wanneer verschillende onderzoeken naar ogenschijnlijk dezelfde behandeling tot tegenstrijdige conclusies komen, waardoor clinici en richtlijnschrijvers onzeker blijven over wat ze moeten aanbevelen.
Een raadselige onenigheid tussen twee bloeddrukonderzoeken
De onderzoekers richten zich op een bekend raadsel. Eén groot onderzoek, SPRINT, toonde aan dat het agressief verlagen van de systolische bloeddruk (met als doel onder 120 mmHg) duidelijk leidde tot minder grote hart- en vaatgebeurtenissen vergeleken met standaardzorg (met als doel onder 140 mmHg). Een ander onderzoek, ACCORD, testte dezelfde agressieve strategie maar bij mensen met type 2-diabetes en vond geen duidelijk voordeel. Er zijn veel mogelijke verklaringen voorgesteld, waaronder verschillen in wie werd opgenomen en in hoe vaak gebeurtenissen voorkwamen, maar er was geen rigoureuze methode om het resultaat van de ene onderzoekspopulatie naar een andere te "transporteren" en te zien of de uitkomst zou veranderen.
Een digitale tweeling van een onderzoek bouwen
Om dit aan te pakken creëerde het team RCT-Twin-GAN, een deep-learningraamwerk dat een digitale tweeling van een gerandomiseerd onderzoek bouwt. De methode gebruikt een type generatief model dat leert hoe verschillende patiëntkenmerken — zoals leeftijd, nierfunctie, hartslag, eerdere hartziekte en medicatiegebruik — zich tot elkaar en tot onderzoeksuitkomsten verhouden. Klinische expertise is ingebouwd via een gerichte kaart van oorzaak-en-gevolgrelaties, die het model stuurt om zich te concentreren op verbindingen die medisch logisch zijn en op het vermijden van schijnverbanden. Zodra het model is getraind op een oorspronkelijk onderzoek, kan het vervolgens worden "geconditioneerd" op een tweede populatie: het neemt het profiel van die nieuwe groep op en genereert een synthetische versie van het onderzoek alsof dat in die patiënten was uitgevoerd, terwijl de randomisatie tussen behandel- en controlegroep behouden blijft.
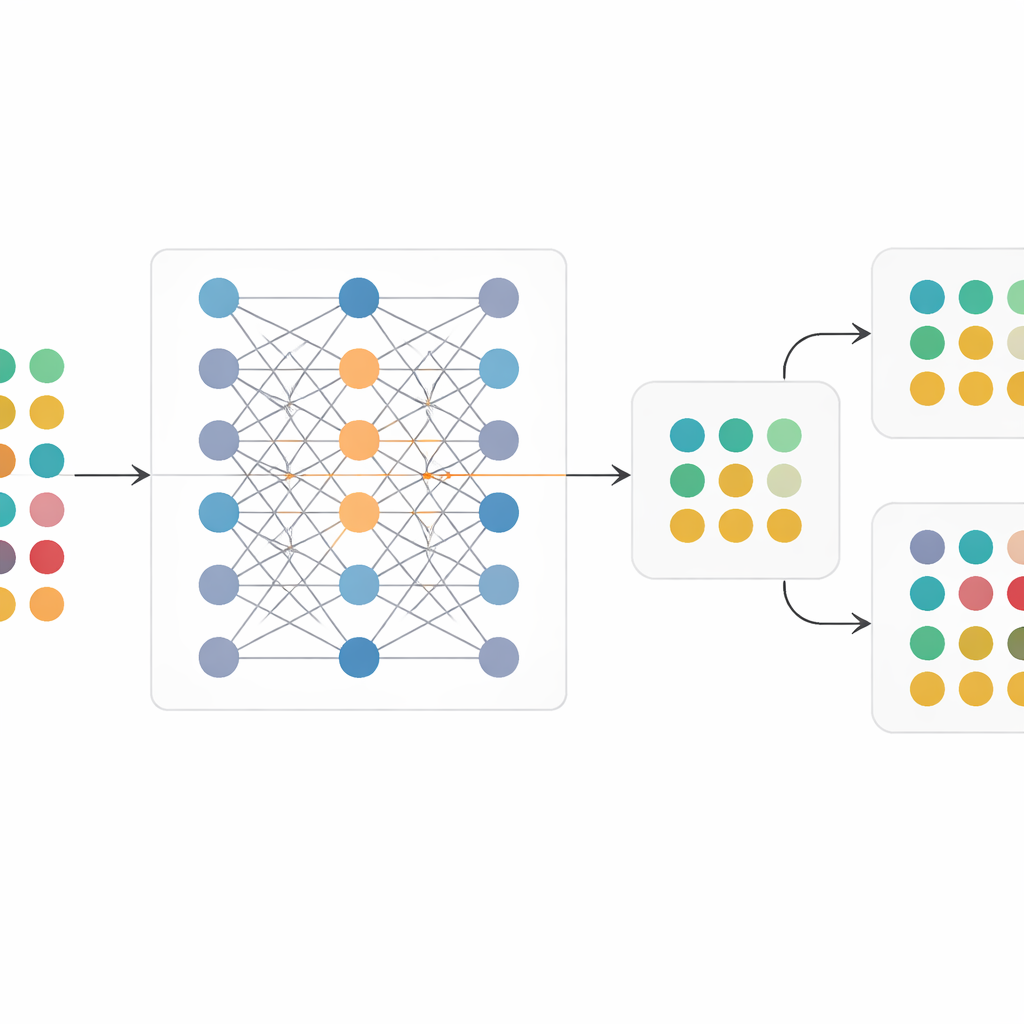
Onderzoeken opnieuw afspelen in nieuwe patiëntpopulaties
De auteurs controleerden eerst of hun digitale tweeling trouw de oorspronkelijke SPRINT- en ACCORD-onderzoeken kon reproduceren. De synthetische versies kwamen nauw overeen met de echte onderzoeken in baselinekenmerken, relaties tussen variabelen en, cruciaal, in de omvang van het behandelvoordeel — of het ontbreken daarvan — die in elk onderzoek werd waargenomen. Vervolgens voerden ze een gedachte-experiment uit: ze trainden het model op SPRINT maar conditioneerden het op de ACCORD-populatie, en omgekeerd. Toen SPRINT werd afgespeeld binnen de ACCORD-populatie, toonde de digitale tweeling geen duidelijk voordeel van intensieve bloeddrukcontrole, en spiegelde daarmee de echte ACCORD-uitkomst. Toen ACCORD werd afgespeeld binnen een SPRINT-achtige populatie, liet de digitale tweeling een significant voordeel zien, wat SPRINT weerspiegelde. Tot slot condoleerden ze het model op echte patiënten uit de elektronische medische dossiers van een groot zorgsysteem, waarmee ze onderzoekstweelingen creëerden die lokale patiëntprofielen weerspiegelden en schatten wat de SPRINT- en ACCORD-interventies in die bredere groepen zouden hebben kunnen bereiken.
Wat dit betekent voor zorg en toekomstige onderzoeken
Voor een leek is de conclusie dat de tegenstrijdige resultaten van SPRINT en ACCORD waarschijnlijk meer voortkomen uit verschillen in wie werd bestudeerd dan uit de bloeddrukstrategie zelf. Dezelfde behandeling kan in de ene mix van patiënten nuttig lijken en in een andere neutraal. RCT-Twin-GAN biedt een manier om deze "wat-als"scenario’s kwantitatief te verkennen, zonder dure en tijdrovende onderzoeken opnieuw te moeten uitvoeren. Hoewel de schattingen die voor populaties uit elektronische medische dossiers worden geproduceerd niet klaar zijn om individuele zorg te sturen, maken ze duidelijk waar onderzoeksbevindingen wel of niet generaliseerbaar zijn. In de loop van de tijd zouden benaderingen als deze zorgsystemen en regelgevers kunnen helpen voorspellen hoe nieuwe behandelingen in echte patiënten presteren en toekomstige onderzoeken zodanig te ontwerpen dat ze beter aansluiten bij de mensen die het meest antwoorden nodig hebben.
Bronvermelding: Thangaraj, P.M., Shankar, S.V., Huang, S. et al. A novel digital twin strategy to examine the implications of randomized clinical trials for real-world populations. npj Digit. Med. 9, 329 (2026). https://doi.org/10.1038/s41746-026-02464-1
Trefwoorden: digitale tweelingen, klinische onderzoeken, bloeddruk, elektronische medische dossiers, generatieve AI