Clear Sky Science · nl
Efficient SqueezeViT: Een lichtgewicht vision-transformer-framework voor classificatie van thoraxfoto's
Waarom sneller lezen van thoraxfoto's ertoe doet
Thoraxfoto's zijn een van de meest gebruikte methoden waarmee artsen zoeken naar problemen aan longen en hart, van longontsteking tot tuberculose. In drukke ziekenhuizen of kleine klinieken met beperkte rekenkracht is het moeilijk om grote AI-systemen te draaien die artsen snel zouden kunnen helpen deze beelden te interpreteren. Deze studie presenteert een nieuw compact AI-model, SqueezeViT genoemd, dat ontworpen is om ziekten op thoraxfoto's te herkennen met veel minder rekencapaciteit dan gebruikelijke systemen, waardoor het praktischer wordt voor gebruik in de kliniek.
Een nieuwe manier om slimme beeldlezers te verkleinen
Moderne beeldherkenningssystemen steunen vaak op twee benaderingen. Convolutionele neurale netwerken zijn goed in het oppikken van fijne details in kleine beeldgebieden, terwijl transformer-modellen beter zijn in het zien van het grotere geheel over de hele opname. Standaard vision-transformers zijn echter zwaar en traag. De auteurs ontwerpen SqueezeViT om het brede perspectief van transformers te behouden, maar de hoeveelheid informatie die bij elke stap verwerkt moet worden te "perken". Hun doel is de beelddelen die van diagnostisch belang zijn te behouden en tegelijk extra rekenwerk te verminderen zodat het model op bescheiden hardware kan draaien.
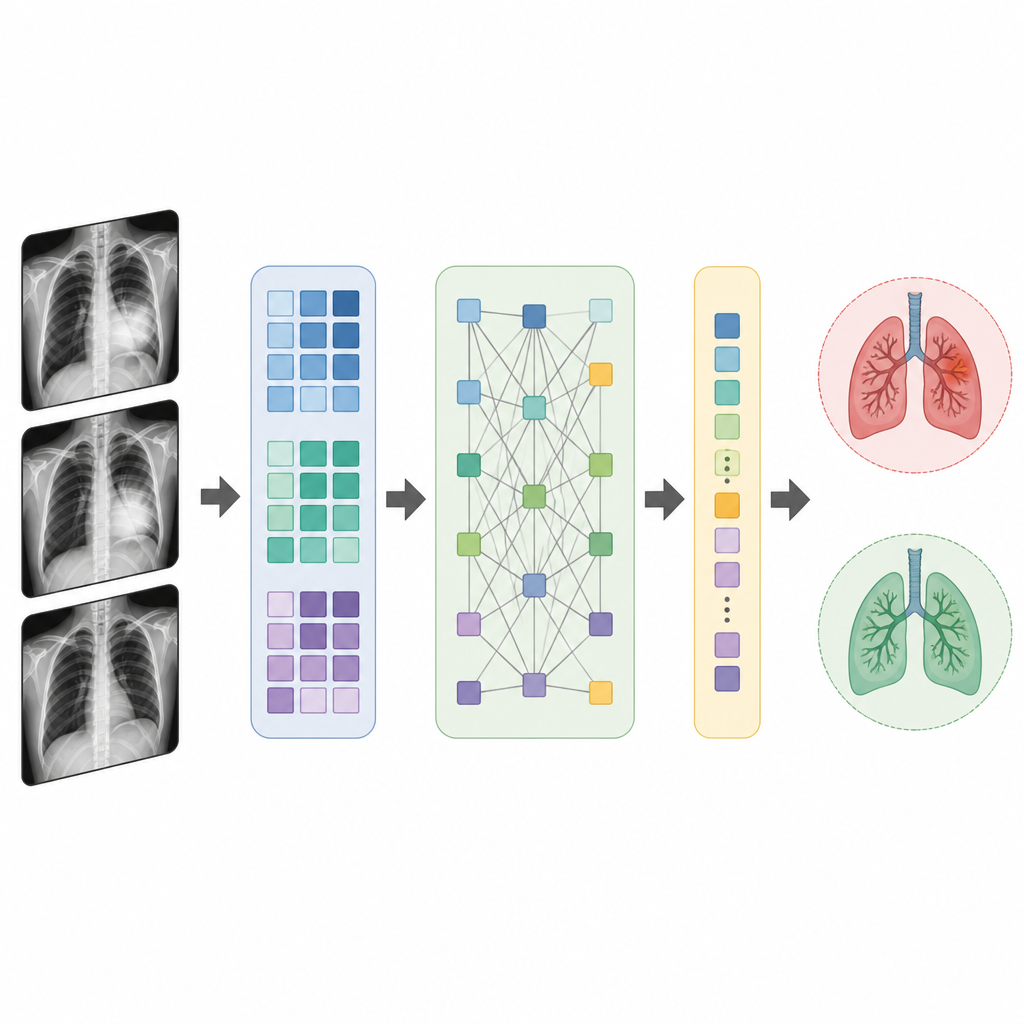
Hoe het compacte model longen en hart ziet
SqueezeViT combineert twee bouwstenen om thoraxfoto's efficiënt te verwerken. De eerste, een Fire-block genoemd, werkt als een slimme filter die de informatie uit het beeld comprimeert naar een kleinere set kenmerken en die vervolgens weer uitbouwt om patronen zoals randen en texturen te benadrukken die samenhangen met ziekte. De tweede, het Translution-block, verdeelt het beeld in kleine patches en past attention toe, waardoor het model signalen uit verschillende delen van de longen of het hart met elkaar kan verbinden. Door iets grotere patches te gebruiken dan veel eerdere ontwerpen, vermindert het model de hoeveelheid werk die de attention-stap moet doen, terwijl het toch vastlegt hoe veranderingen in één deel van de thorax samenhangen met andere delen.
Het systeem op de proef gesteld
Om te beoordelen hoe goed SqueezeViT in de praktijk werkt, evalueren de onderzoekers het op twee grote openbare verzamelingen van thoraxfoto's: de NIH ChestX-ray14-dataset en de CheXpert-dataset. Samen omvatten deze honderdduizenden beelden die gelabeld zijn voor verschillende aandoeningen, zoals cardiomegalie, oedeem, longontsteking en longknobbels. Het team traint SqueezeViT vanaf nul en vergelijkt het vermogen om zieke van gezonde gevallen te onderscheiden met bekende deep-learningmodellen, waaronder zwaargewichten zoals ResNet en DenseNet en lichtere opties zoals MobileNet, ShuffleNet, SqueezeNet en MobileViT. Ze richten zich op de area under the receiver operating characteristic-curve, een score die modellen beloont die abnormale gevallen hoger rangschikken dan normale over verschillende beslissingsdrempels.
Snelheid, omvang en nauwkeurigheid in balans
De resultaten tonen dat SqueezeViT accuratesse bereikt die vergelijkbaar is met, en in meerdere taken beter dan, veel grotere modellen, terwijl het aanzienlijk kleiner is. Het gebruikt ongeveer een halve miljoen trainbare parameters, waardoor het aantal parameters met meer dan 40 procent vermindert vergeleken met MobileViT en met meer dan 90 procent vergeleken met sommige van de grootste referentiemodellen. De berekeningen, het geheugenverbruik en de vertragingen in verwerking op zowel grafische processen als standaard CPU's zijn allemaal verminderd, waardoor het in staat is beelden in slechts enkele milliseconden op typische hardware te analyseren. In multi-ziekte-scenario's evenaart SqueezeViT of blijft het dicht bij de beste zware modellen voor veel aandoeningen en overtreft het duidelijk andere lichtgewicht ontwerpen. Voor eenvoudige normaal-tegen-abnormaal beslissingen levert het opnieuw sterke en consistente scores over beide datasets.
Wat dit betekent voor de dagelijkse zorg
Voor lezers zonder technische achtergrond is de kernboodschap dat SqueezeViT aantoont dat het mogelijk is een AI-assistent voor thoraxfoto's te bouwen die zowel zuinig is met rekenmiddelen als zorgvuldig in ziekteherkenning. Hoewel het de noodzaak voor radiologen of clinici niet wegneemt, kan het helpen verdachte opnames sneller te signaleren in drukke ziekenhuizen en geavanceerde beeldanalyse toegankelijker te maken voor klinieken met beperkte apparatuur. De auteurs merken op dat labels uit de praktijk ruis kunnen bevatten en sommige ziektecategorieën uitdagend blijven, maar zij stellen dat dit compacte ontwerp een veelbelovende stap is richting betrouwbare, draagbare ondersteuningshulpmiddelen voor thoraxbeeldvorming en mogelijk in de toekomst aangepast kan worden voor andere beeldvormingen zoals CT of MRI.
Bronvermelding: Maurya, A., Lohia, A., Chirag et al. Efficient SqueezeViT: A lightweight vision transformer framework for chest X-ray image classification. Sci Rep 16, 16183 (2026). https://doi.org/10.1038/s41598-026-47918-4
Trefwoorden: thoraxfoto AI, vision transformer, medische beeldanalyse, lichtgewicht deep learning, detectie van longziekten