Clear Sky Science · de
Efficient SqueezeViT: Ein leichtgewichtiges Vision-Transformer‑Framework zur Klassifizierung von Thorax-Röntgenbildern
Warum schnellere Auswertung von Thorax‑Röntgenaufnahmen wichtig ist
Thorax‑Röntgenuntersuchungen sind eine der häufigsten Methoden, mit denen Ärztinnen und Ärzte nach Lungen‑ und Herzproblemen suchen, von Pneumonie bis Tuberkulose. In viel beschäftigten Krankenhäusern oder kleinen Kliniken mit begrenzter Computerleistung ist es schwierig, große KI‑Modelle zu betreiben, die bei der schnellen Befundung unterstützen könnten. Diese Studie stellt ein neues kompaktes KI‑Modell namens SqueezeViT vor, das Thorax‑Erkrankungen auf Röntgenaufnahmen erkennt und dabei deutlich weniger Rechenleistung benötigt als übliche Systeme, wodurch es im praktischen Klinikalltag besser einsetzbar ist.
Ein neuer Ansatz, intelligente Bildleser zu verkleinern
Moderne Bildverarbeitungswerkzeuge beruhen oft auf zwei Prinzipien. Convolutional Neural Networks sind gut darin, feine Details in kleinen Bildbereichen zu erfassen, während Transformer‑Modelle das große Ganze über das gesamte Bild hinweg besser erkennen. Standard‑Vision‑Transformer sind jedoch ressourcenintensiv und langsam. Die Autorinnen und Autoren entwerfen SqueezeViT so, dass er die breite Perspektive von Transformern beibehält, gleichzeitig aber die zu verarbeitende Informationsmenge „zusammendrückt“. Ziel ist es, die für die Diagnose relevanten Bildteile zu bewahren und unnötige Berechnungen zu reduzieren, damit das Modell auf bescheidener Hardware läuft.
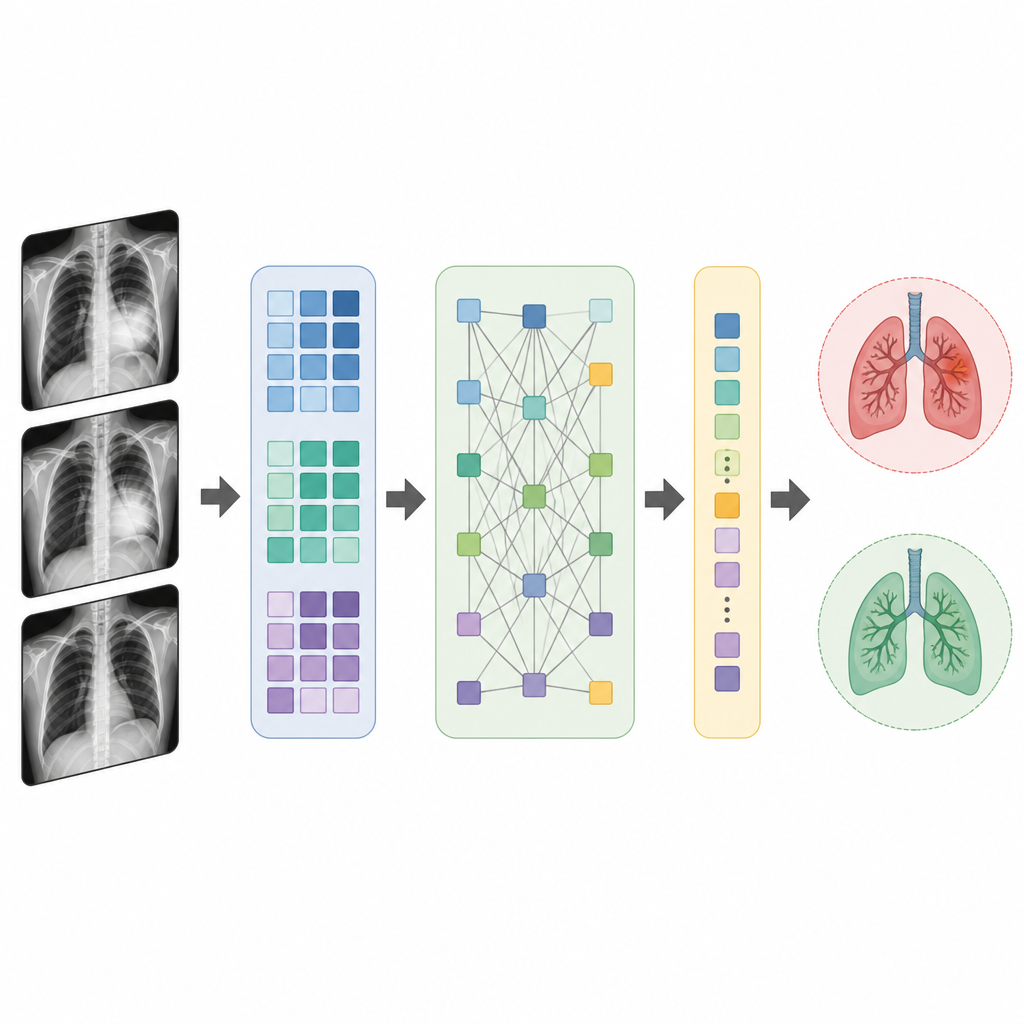
Wie das kompakte Modell Lunge und Herz sieht
SqueezeViT kombiniert zwei Bausteine, um Thorax‑Röntgenbilder effizient zu verarbeiten. Der erste, als Fire‑Block bezeichnet, wirkt wie ein intelligenter Filter, der die Bildinformation in eine kleinere Menge an Merkmalen komprimiert und diese anschließend wieder erweitert, um Muster wie Kanten und Texturen hervorzuheben, die mit Erkrankungen zusammenhängen. Der zweite, der Translution‑Block genannt wird, zerlegt das Bild in kleine Patches und wendet Attention an, wodurch das Modell Signale aus entfernten Bereichen der Lunge oder des Herzens in Beziehung setzen kann. Durch die Verwendung etwas größerer Patches als in vielen früheren Entwürfen reduziert das Modell den Aufwand für den Attention‑Schritt, erfasst aber weiterhin, wie Veränderungen in einem Bereich des Thorax mit anderen Bereichen zusammenhängen.
Das System im Praxistest
Um die Praxisrelevanz von SqueezeViT zu prüfen, evaluieren die Forschenden das Modell an zwei großen öffentlichen Sammlungen von Thorax‑Röntgenaufnahmen: dem NIH ChestX‑ray14‑Datensatz und dem CheXpert‑Datensatz. Zusammen umfassen diese Hunderttausende von Bildern, die für eine Reihe von Erkrankungen beschriftet sind, etwa Kardiomegalie, Ödem, Pneumonie und Lungenknoten. Das Team trainiert SqueezeViT von Grund auf neu und vergleicht seine Fähigkeit, kranke von gesunden Fällen zu unterscheiden, mit bekannten Deep‑Learning‑Modellen, darunter schwere Modelle wie ResNet und DenseNet sowie leichtere Optionen wie MobileNet, ShuffleNet, SqueezeNet und MobileViT. Im Fokus steht die Fläche unter der Receiver‑Operating‑Characteristic‑Kurve, eine Metrik, die Modelle dafür belohnt, abnorme Fälle gegenüber normalen über verschiedene Entscheidungsschwellen hinweg höher zu bewerten.
Balance zwischen Geschwindigkeit, Größe und Genauigkeit
Die Ergebnisse zeigen, dass SqueezeViT eine Genauigkeit erreicht, die mit deutlich größeren Modellen vergleichbar ist und in mehreren Aufgaben sogar überlegen, dabei jedoch deutlich kleiner ist. Es nutzt etwa eine halbe Million trainierbarer Parameter und reduziert die Anzahl der Parameter damit um mehr als 40 Prozent gegenüber MobileViT und um über 90 Prozent gegenüber einigen der größten Referenzmodelle. Auch Rechenaufwand, Speicherbedarf und Latenzen auf Grafikkarten sowie Standard‑CPUs sind reduziert, sodass das Modell Bilder auf typischer Hardware in nur wenigen Millisekunden analysieren kann. In Multi‑Erkrankungs‑Szenarien erreicht SqueezeViT für viele Befunde die Leistung der besten schweren Modelle oder liegt dicht dahinter und übertrifft deutlich andere leichtgewichtige Entwürfe. Bei einfachen Normal‑gegen‑Abnormal‑Entscheidungen liefert es ebenfalls starke und konsistente Ergebnisse in beiden Datensätzen.
Was das für die Routineversorgung bedeutet
Für nicht technische Leserinnen und Leser lautet die Kernbotschaft: SqueezeViT zeigt, dass sich ein KI‑Assistent für Thorax‑Röntgenbilder bauen lässt, der sowohl ressourcenschonend ist als auch sorgfältig bei der Erkennung von Erkrankungen vorgeht. Er ersetzt nicht die Radiologinnen und Radiologen oder Klinikärztinnen und ‑ärzte, könnte aber dabei helfen, auffällige Aufnahmen in überfüllten Kliniken schneller zu kennzeichnen und fortschrittliche Bildanalyse in Einrichtungen mit begrenzter Ausstattung zugänglich zu machen. Die Autorinnen und Autoren weisen darauf hin, dass reale Labels Rauschen enthalten können und einige Krankheitskategorien weiterhin schwierig bleiben, sehen dieses kompakte Design jedoch als vielversprechenden Schritt zu zuverlässigen, portablen Unterstützungstools für die Thorax‑Bildgebung, die sich künftig auch auf andere Bildgebungen wie CT oder MRT übertragen lassen könnten.
Zitation: Maurya, A., Lohia, A., Chirag et al. Efficient SqueezeViT: A lightweight vision transformer framework for chest X-ray image classification. Sci Rep 16, 16183 (2026). https://doi.org/10.1038/s41598-026-47918-4
Schlüsselwörter: KI für Thorax-Röntgen, Vision Transformer, medizinische Bildanalyse, leichte Deep Learning‑Modelle, Erkennung von Lungenerkrankungen